Compare commits
1 Commits
main
...
gopher-ser
| Author | SHA1 | Date |
|---|---|---|
|
|
f6d4cdfb9d |
|
|
@ -1 +0,0 @@
|
||||||
nix/sources.nix linguist-vendored
|
|
||||||
|
|
@ -0,0 +1,19 @@
|
||||||
|
name: Go
|
||||||
|
on: [push]
|
||||||
|
jobs:
|
||||||
|
build:
|
||||||
|
name: Build
|
||||||
|
runs-on: ubuntu-latest
|
||||||
|
steps:
|
||||||
|
- name: Set up Go 1.12
|
||||||
|
uses: actions/setup-go@v1
|
||||||
|
with:
|
||||||
|
go-version: 1.12
|
||||||
|
id: go
|
||||||
|
- name: Check out code into the Go module directory
|
||||||
|
uses: actions/checkout@v1
|
||||||
|
- name: Test
|
||||||
|
run: go test -v ./...
|
||||||
|
env:
|
||||||
|
GO111MODULE: on
|
||||||
|
GOPROXY: https://cache.greedo.xeserv.us
|
||||||
|
|
@ -0,0 +1,80 @@
|
||||||
|
name: "CI/CD"
|
||||||
|
on:
|
||||||
|
push:
|
||||||
|
branches:
|
||||||
|
- master
|
||||||
|
jobs:
|
||||||
|
deploy:
|
||||||
|
runs-on: ubuntu-latest
|
||||||
|
steps:
|
||||||
|
- uses: actions/checkout@v1
|
||||||
|
- name: Build container image
|
||||||
|
run: |
|
||||||
|
docker build -t xena/christinewebsite:$(echo $GITHUB_SHA | head -c7) .
|
||||||
|
echo $DOCKER_PASSWORD | docker login -u $DOCKER_USERNAME --password-stdin
|
||||||
|
docker push xena/christinewebsite
|
||||||
|
env:
|
||||||
|
DOCKER_USERNAME: "xena"
|
||||||
|
DOCKER_PASSWORD: ${{ secrets.DOCKER_PASSWORD }}
|
||||||
|
- name: Download secrets/Install/Configure/Use Dyson
|
||||||
|
run: |
|
||||||
|
mkdir ~/.ssh
|
||||||
|
echo $FILE_DATA | base64 -d > ~/.ssh/id_rsa
|
||||||
|
md5sum ~/.ssh/id_rsa
|
||||||
|
chmod 600 ~/.ssh/id_rsa
|
||||||
|
git clone git@ssh.tulpa.dev:cadey/within-terraform-secret
|
||||||
|
curl https://xena.greedo.xeserv.us/files/dyson-linux-amd64-0.1.0.tgz | tar xz
|
||||||
|
cp ./dyson-linux-amd64-0.1.1/dyson .
|
||||||
|
rm -rf dyson-linux-amd64-0.1.1
|
||||||
|
mkdir -p ~/.config/dyson
|
||||||
|
|
||||||
|
echo '[DigitalOcean]
|
||||||
|
Token = ""
|
||||||
|
|
||||||
|
[Cloudflare]
|
||||||
|
Email = ""
|
||||||
|
Token = ""
|
||||||
|
|
||||||
|
[Secrets]
|
||||||
|
GitCheckout = "./within-terraform-secret"' > ~/.config/dyson/dyson.ini
|
||||||
|
|
||||||
|
./dyson manifest \
|
||||||
|
--name=christinewebsite \
|
||||||
|
--domain=christine.website \
|
||||||
|
--dockerImage=xena/christinewebsite:$(echo $GITHUB_SHA | head -c7) \
|
||||||
|
--containerPort=5000 \
|
||||||
|
--replicas=1 \
|
||||||
|
--useProdLE=true > $GITHUB_WORKSPACE/deploy.yml
|
||||||
|
env:
|
||||||
|
FILE_DATA: ${{ secrets.SSH_PRIVATE_KEY }}
|
||||||
|
GIT_SSH_COMMAND: "ssh -i ~/.ssh/id_rsa -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no"
|
||||||
|
- name: Save DigitalOcean kubeconfig
|
||||||
|
uses: digitalocean/action-doctl@master
|
||||||
|
env:
|
||||||
|
DIGITALOCEAN_ACCESS_TOKEN: ${{ secrets.DIGITALOCEAN_TOKEN }}
|
||||||
|
with:
|
||||||
|
args: kubernetes cluster kubeconfig show kubermemes > $GITHUB_WORKSPACE/.kubeconfig
|
||||||
|
- name: Deploy to DigitalOcean Kubernetes
|
||||||
|
uses: docker://lachlanevenson/k8s-kubectl
|
||||||
|
with:
|
||||||
|
args: --kubeconfig=/github/workspace/.kubeconfig apply -n apps -f /github/workspace/deploy.yml
|
||||||
|
- name: Verify deployment
|
||||||
|
uses: docker://lachlanevenson/k8s-kubectl
|
||||||
|
with:
|
||||||
|
args: --kubeconfig=/github/workspace/.kubeconfig rollout status -n apps deployment/christinewebsite
|
||||||
|
- name: Ping Google
|
||||||
|
uses: docker://lachlanevenson/k8s-kubectl
|
||||||
|
with:
|
||||||
|
args: --kubeconfig=/github/workspace/.kubeconfig apply -f /github/workspace/k8s/job.yml
|
||||||
|
- name: Sleep
|
||||||
|
run: |
|
||||||
|
sleep 5
|
||||||
|
- name: Don't Ping Google
|
||||||
|
uses: docker://lachlanevenson/k8s-kubectl
|
||||||
|
with:
|
||||||
|
args: --kubeconfig=/github/workspace/.kubeconfig delete -f /github/workspace/k8s/job.yml
|
||||||
|
- name: POSSE
|
||||||
|
env:
|
||||||
|
MI_TOKEN: ${{ secrets.MI_TOKEN }}
|
||||||
|
run: |
|
||||||
|
curl -H "Authorization: $MI_TOKEN" --data "https://christine.website/blog.json" https://mi.within.website/blog/refresh
|
||||||
|
|
@ -1,18 +0,0 @@
|
||||||
name: "Nix"
|
|
||||||
on:
|
|
||||||
push:
|
|
||||||
branches:
|
|
||||||
- main
|
|
||||||
pull_request:
|
|
||||||
branches:
|
|
||||||
- main
|
|
||||||
jobs:
|
|
||||||
docker-build:
|
|
||||||
runs-on: ubuntu-latest
|
|
||||||
steps:
|
|
||||||
- uses: actions/checkout@v1
|
|
||||||
- uses: cachix/install-nix-action@v12
|
|
||||||
- uses: cachix/cachix-action@v7
|
|
||||||
with:
|
|
||||||
name: xe
|
|
||||||
- run: nix build --no-link
|
|
||||||
|
|
@ -2,7 +2,3 @@
|
||||||
cw.tar
|
cw.tar
|
||||||
.env
|
.env
|
||||||
.DS_Store
|
.DS_Store
|
||||||
/result-*
|
|
||||||
/result
|
|
||||||
.#*
|
|
||||||
/target
|
|
||||||
|
|
|
||||||
15
CHANGELOG.md
15
CHANGELOG.md
|
|
@ -1,15 +0,0 @@
|
||||||
# Changelog
|
|
||||||
|
|
||||||
New site features will be documented here.
|
|
||||||
|
|
||||||
## 2.1.0
|
|
||||||
|
|
||||||
- Blogpost bodies are now present in the RSS feed
|
|
||||||
|
|
||||||
## 2.0.1
|
|
||||||
|
|
||||||
Custom render RSS/Atom feeds
|
|
||||||
|
|
||||||
## 2.0.0
|
|
||||||
|
|
||||||
Complete site rewrite in Rust
|
|
||||||
File diff suppressed because it is too large
Load Diff
59
Cargo.toml
59
Cargo.toml
|
|
@ -1,59 +0,0 @@
|
||||||
[package]
|
|
||||||
name = "xesite"
|
|
||||||
version = "2.2.0"
|
|
||||||
authors = ["Christine Dodrill <me@christine.website>"]
|
|
||||||
edition = "2018"
|
|
||||||
build = "src/build.rs"
|
|
||||||
repository = "https://github.com/Xe/site"
|
|
||||||
|
|
||||||
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
|
|
||||||
|
|
||||||
[dependencies]
|
|
||||||
color-eyre = "0.5"
|
|
||||||
chrono = "0.4"
|
|
||||||
comrak = "0.9"
|
|
||||||
envy = "0.4"
|
|
||||||
glob = "0.3"
|
|
||||||
hyper = "0.14"
|
|
||||||
kankyo = "0.3"
|
|
||||||
lazy_static = "1.4"
|
|
||||||
log = "0.4"
|
|
||||||
mime = "0.3.0"
|
|
||||||
prometheus = { version = "0.11", default-features = false, features = ["process"] }
|
|
||||||
rand = "0"
|
|
||||||
reqwest = { version = "0.11", features = ["json"] }
|
|
||||||
sdnotify = { version = "0.1", default-features = false }
|
|
||||||
serde_dhall = "0.9.0"
|
|
||||||
serde = { version = "1", features = ["derive"] }
|
|
||||||
serde_yaml = "0.8"
|
|
||||||
sitemap = "0.4"
|
|
||||||
thiserror = "1"
|
|
||||||
tokio = { version = "1", features = ["full"] }
|
|
||||||
tracing = "0.1"
|
|
||||||
tracing-futures = "0.2"
|
|
||||||
tracing-subscriber = { version = "0.2", features = ["fmt"] }
|
|
||||||
warp = "0.3"
|
|
||||||
xml-rs = "0.8"
|
|
||||||
url = "2"
|
|
||||||
uuid = { version = "0.8", features = ["serde", "v4"] }
|
|
||||||
|
|
||||||
# workspace dependencies
|
|
||||||
cfcache = { path = "./lib/cfcache" }
|
|
||||||
go_vanity = { path = "./lib/go_vanity" }
|
|
||||||
jsonfeed = { path = "./lib/jsonfeed" }
|
|
||||||
mi = { path = "./lib/mi" }
|
|
||||||
patreon = { path = "./lib/patreon" }
|
|
||||||
|
|
||||||
[build-dependencies]
|
|
||||||
ructe = { version = "0.13", features = ["warp02"] }
|
|
||||||
|
|
||||||
[dev-dependencies]
|
|
||||||
pfacts = "0"
|
|
||||||
serde_json = "1"
|
|
||||||
eyre = "0.6"
|
|
||||||
pretty_env_logger = "0"
|
|
||||||
|
|
||||||
[workspace]
|
|
||||||
members = [
|
|
||||||
"./lib/*",
|
|
||||||
]
|
|
||||||
|
|
@ -0,0 +1,19 @@
|
||||||
|
FROM xena/go:1.13.6 AS build
|
||||||
|
ENV GOPROXY https://cache.greedo.xeserv.us
|
||||||
|
COPY . /site
|
||||||
|
WORKDIR /site
|
||||||
|
RUN CGO_ENABLED=0 go test -v ./...
|
||||||
|
RUN CGO_ENABLED=0 GOBIN=/root go install -v ./cmd/site
|
||||||
|
|
||||||
|
FROM xena/alpine
|
||||||
|
EXPOSE 5000
|
||||||
|
WORKDIR /site
|
||||||
|
COPY --from=build /root/site .
|
||||||
|
COPY ./static /site/static
|
||||||
|
COPY ./templates /site/templates
|
||||||
|
COPY ./blog /site/blog
|
||||||
|
COPY ./talks /site/talks
|
||||||
|
COPY ./gallery /site/gallery
|
||||||
|
COPY ./css /site/css
|
||||||
|
HEALTHCHECK CMD wget --spider http://127.0.0.1:5000/.within/health || exit 1
|
||||||
|
CMD ./site
|
||||||
2
LICENSE
2
LICENSE
|
|
@ -1,4 +1,4 @@
|
||||||
Copyright (c) 2017-2021 Christine Dodrill <me@christine.website>
|
Copyright (c) 2017 Christine Dodrill <me@christine.website>
|
||||||
|
|
||||||
This software is provided 'as-is', without any express or implied
|
This software is provided 'as-is', without any express or implied
|
||||||
warranty. In no event will the authors be held liable for any damages
|
warranty. In no event will the authors be held liable for any damages
|
||||||
|
|
|
||||||
|
|
@ -1,8 +1,5 @@
|
||||||
# site
|
# site
|
||||||
|
|
||||||
[](https://builtwithnix.org)
|
|
||||||

|
|
||||||

|
|
||||||
|
|
||||||
My personal/portfolio website.
|
My personal/portfolio website.
|
||||||
|
|
||||||
|

|
||||||
|
|
|
||||||
|
|
@ -1,177 +0,0 @@
|
||||||
---
|
|
||||||
title: The 7th Edition
|
|
||||||
date: 2020-12-19
|
|
||||||
tags:
|
|
||||||
- ttrpg
|
|
||||||
---
|
|
||||||
|
|
||||||
# The 7th Edition
|
|
||||||
|
|
||||||
You know what, fuck rules. Fuck systems. Fuck limitations. Let's dial the
|
|
||||||
tabletop RPG system down to its roots. Let's throw out every stat but one:
|
|
||||||
Awesomeness. When you try to do something that could fail, roll for Awesomeness.
|
|
||||||
If your roll is more than your awesomeness stat, you win. If not, you lose. If
|
|
||||||
you are or have something that would benefit you in that situation, roll for
|
|
||||||
awesomeness twice and take the higher value.
|
|
||||||
|
|
||||||
No stats.<br />
|
|
||||||
No counts.<br />
|
|
||||||
No limits.<br />
|
|
||||||
No gods.<br />
|
|
||||||
No masters.<br />
|
|
||||||
Just you and me and nature in the battlefield.
|
|
||||||
|
|
||||||
* Want to shoot an arrow? Roll for awesomeness. You failed? You're out of ammo.
|
|
||||||
* Want to, defeat a goblin but you have a goblin-slaying-broadsword? Roll twice
|
|
||||||
for awesomeness and take the higher value. You got a 20? That goblin was
|
|
||||||
obliterated. Good job.
|
|
||||||
* Want to pick up an item into your inventory? Roll for awesomeness. You got it?
|
|
||||||
It's in your inventory.
|
|
||||||
|
|
||||||
Etc. Don't think too hard. Let a roll of the dice decide if you are unsure.
|
|
||||||
|
|
||||||
## Base Awesomeness Stats
|
|
||||||
|
|
||||||
Here are some probably balanced awesomeness base stats depending on what kind of
|
|
||||||
dice you are using:
|
|
||||||
|
|
||||||
* 6-sided: 4 or 5
|
|
||||||
* 8-sided: 5 or 6
|
|
||||||
* 10-sided: 6 or 7
|
|
||||||
* 12-sided: 7 or 8
|
|
||||||
* 20-sided: anywhere from 11-13
|
|
||||||
|
|
||||||
## Character Sheet Template
|
|
||||||
|
|
||||||
Here's an example character sheet:
|
|
||||||
|
|
||||||
```
|
|
||||||
Name:
|
|
||||||
Awesomeness:
|
|
||||||
Race:
|
|
||||||
Class:
|
|
||||||
Inventory:
|
|
||||||
*
|
|
||||||
```
|
|
||||||
|
|
||||||
That's it. You don't even need the race or class if you don't want to have it.
|
|
||||||
|
|
||||||
You can add more if you feel it is relevant for your character. If your
|
|
||||||
character is a street brat that has experience with haggling, then fuck it be
|
|
||||||
the most street brattiest haggler you can. Try to not overload your sheet with
|
|
||||||
information, this game is supposed to be simple. A sentence or two at most is
|
|
||||||
good.
|
|
||||||
|
|
||||||
## One Player is The World
|
|
||||||
|
|
||||||
The World is a character that other systems would call the Narrator, the
|
|
||||||
Pathfinder, Dungeon Master or similar. Let's strip this down to the core of the
|
|
||||||
matter. One player doesn't just dictate the world, they _are_ the world.
|
|
||||||
|
|
||||||
The World also controls the monsters and non-player characters. In general, if
|
|
||||||
you are in doubt as to who should roll for an event, The World does that roll.
|
|
||||||
|
|
||||||
## Mixins/Mods
|
|
||||||
|
|
||||||
These are things you can do to make the base game even more tailored to your
|
|
||||||
group. Whether you should do this is highly variable to the needs and whims of
|
|
||||||
your group in particular.
|
|
||||||
|
|
||||||
### Mixin: Adjustable Awesomeness
|
|
||||||
|
|
||||||
So, one problem that could come up with this is that bad luck could make this
|
|
||||||
not as fun. As a result, add these two rules in:
|
|
||||||
|
|
||||||
* Every time you roll above your awesomeness, add 1 to your awesomeness stat
|
|
||||||
* Every time you roll below your awesomeness, remove 1 from your awesomeness
|
|
||||||
stat
|
|
||||||
|
|
||||||
This should add up so that luck would even out over time. Players that have less
|
|
||||||
luck than usual will eventually get their awesomeness evened out so that luck
|
|
||||||
will be in their favor.
|
|
||||||
|
|
||||||
### Mixin: No Awesomeness
|
|
||||||
|
|
||||||
In this mod, rip out Awesomeness altogether. When two parties are at odds, they
|
|
||||||
both roll dice. The one that rolls higher gets what they want. If they tie, both
|
|
||||||
people get a little part of what they want. For extra fun do this with six-sided
|
|
||||||
dice.
|
|
||||||
|
|
||||||
* Monster wants to attack a player? The World and that player roll. If the
|
|
||||||
player wins, they can choose to counterattack. If the monster wins, they do a
|
|
||||||
wound or something.
|
|
||||||
* One player wants to steal from another? Have them both roll to see what
|
|
||||||
happens.
|
|
||||||
|
|
||||||
Use your imagination! Ask others if you are unsure!
|
|
||||||
|
|
||||||
## Other Advice
|
|
||||||
|
|
||||||
This is not essential but it may help.
|
|
||||||
|
|
||||||
### Monster Building
|
|
||||||
|
|
||||||
Okay so basically monsters fall into two categories: peons and bosses. Peons
|
|
||||||
should be easy to defeat, usually requiring one action. Bosses may require more
|
|
||||||
and might require more than pure damage to defeat. Get clever. Maybe require the
|
|
||||||
players to drop a chandelier on the boss. Use the environment.
|
|
||||||
|
|
||||||
In general, peons should have a very high base awesomeness in order to do things
|
|
||||||
they want. Bosses can vary based on your mood.
|
|
||||||
|
|
||||||
Adjustable awesomeness should affect monsters too.
|
|
||||||
|
|
||||||
### Worldbuilding
|
|
||||||
|
|
||||||
Take a setting from somewhere and roll with it. You want to do a cyberpunk jaunt
|
|
||||||
in Night City with a sword-wielding warlock, a succubus space marine, a bard
|
|
||||||
netrunner and a shapeshifting monk? Do the hell out of that. That sounds
|
|
||||||
awesome.
|
|
||||||
|
|
||||||
Don't worry about accuracy or the like. You are setting out to have fun.
|
|
||||||
|
|
||||||
## Special Thanks
|
|
||||||
|
|
||||||
Special thanks goes to Jared, who sent out this [tweet][1] that inspired this
|
|
||||||
document. In case the tweet gets deleted, here's what it said:
|
|
||||||
|
|
||||||
[1]: https://twitter.com/infinite_mao/status/1340402360259137541
|
|
||||||
|
|
||||||
> heres a d&d for you
|
|
||||||
|
|
||||||
> you have one stat, its a saving throw. if you need to roll dice, you roll your
|
|
||||||
> save.
|
|
||||||
|
|
||||||
> you have a class and some equipment and junk. if the thing you need to roll
|
|
||||||
> dice for is relevant to your class or equipment or whatever, roll your save
|
|
||||||
> with advantage.
|
|
||||||
|
|
||||||
> oh your Save is 5 or something. if you do something awesome, raise your save
|
|
||||||
> by 1.
|
|
||||||
|
|
||||||
> no hp, save vs death. no damage, save vs goblin. no tracking arrows, save vs
|
|
||||||
> running out of ammo.
|
|
||||||
|
|
||||||
> thanks to @Axes_N_Orcs for this
|
|
||||||
|
|
||||||
> What's So Cool About Save vs Death?
|
|
||||||
|
|
||||||
> can you carry all that treasure and equipment? save vs gains
|
|
||||||
|
|
||||||
I replied:
|
|
||||||
|
|
||||||
> Can you get more minimal than this?
|
|
||||||
|
|
||||||
He replied:
|
|
||||||
|
|
||||||
> when two or more parties are at odds, all roll dice. highest result gets what
|
|
||||||
> they want.
|
|
||||||
|
|
||||||
> hows that?
|
|
||||||
|
|
||||||
This document is really just this twitter exchange in more words so that people
|
|
||||||
less familiar with tabletop games can understand it more easily. You know you
|
|
||||||
have finished when there is nothing left to remove, not when you can add
|
|
||||||
something to "fix" it.
|
|
||||||
|
|
||||||
I might put this on my [itch.io page](https://withinstudios.itch.io/).
|
|
||||||
|
|
@ -1,640 +0,0 @@
|
||||||
---
|
|
||||||
title: "TL;DR Rust"
|
|
||||||
date: 2020-09-19
|
|
||||||
series: rust
|
|
||||||
tags:
|
|
||||||
- go
|
|
||||||
- golang
|
|
||||||
---
|
|
||||||
|
|
||||||
# TL;DR Rust
|
|
||||||
|
|
||||||
Recently I've been starting to use Rust more and more for larger and larger
|
|
||||||
projects. As things have come up, I realized that I am missing a good reference
|
|
||||||
for common things in Rust as compared to Go. This post contains a quick
|
|
||||||
high-level overview of patterns in Rust and how they compare to patterns
|
|
||||||
in Go. This will focus on code samples. This is no replacement for the [Rust
|
|
||||||
book](https://doc.rust-lang.org/book/), but should help you get spun up on the
|
|
||||||
various patterns used in Rust code.
|
|
||||||
|
|
||||||
Also I'm happy to introduce Mara to the blog!
|
|
||||||
|
|
||||||
[Hey, happy to be here! I'm Mara, a shark hacker from Christine's imagination.
|
|
||||||
I'll interject with side information, challenge assertions and more! Thanks for
|
|
||||||
inviting me!](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
Let's start somewhere simple: functions.
|
|
||||||
|
|
||||||
## Making Functions
|
|
||||||
|
|
||||||
Functions are defined using `fn` instead of `func`:
|
|
||||||
|
|
||||||
```go
|
|
||||||
func foo() {}
|
|
||||||
```
|
|
||||||
|
|
||||||
```rust
|
|
||||||
fn foo() {}
|
|
||||||
```
|
|
||||||
|
|
||||||
### Arguments
|
|
||||||
|
|
||||||
Arguments can be passed by separating the name from the type with a colon:
|
|
||||||
|
|
||||||
```go
|
|
||||||
func foo(bar int) {}
|
|
||||||
```
|
|
||||||
|
|
||||||
```rust
|
|
||||||
fn foo(bar: i32) {}
|
|
||||||
```
|
|
||||||
|
|
||||||
### Returns
|
|
||||||
|
|
||||||
Values can be returned by adding `-> Type` to the function declaration:
|
|
||||||
|
|
||||||
```go
|
|
||||||
func foo() int {
|
|
||||||
return 2
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
```rust
|
|
||||||
fn foo() -> i32 {
|
|
||||||
return 2;
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
In Rust values can also be returned on the last statement without the `return`
|
|
||||||
keyword or a terminating semicolon:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
fn foo() -> i32 {
|
|
||||||
2
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
[Hmm, what if I try to do something like this. Will this
|
|
||||||
work?](conversation://Mara/hmm)
|
|
||||||
|
|
||||||
```rust
|
|
||||||
fn foo() -> i32 {
|
|
||||||
if some_cond {
|
|
||||||
2
|
|
||||||
}
|
|
||||||
|
|
||||||
4
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
Let's find out! The compiler spits back an error:
|
|
||||||
|
|
||||||
```
|
|
||||||
error[E0308]: mismatched types
|
|
||||||
--> src/lib.rs:3:9
|
|
||||||
|
|
|
||||||
2 | / if some_cond {
|
|
||||||
3 | | 2
|
|
||||||
| | ^ expected `()`, found integer
|
|
||||||
4 | | }
|
|
||||||
| | -- help: consider using a semicolon here
|
|
||||||
| |_____|
|
|
||||||
| expected this to be `()`
|
|
||||||
```
|
|
||||||
|
|
||||||
This happens because most basic statements in Rust can return values. The best
|
|
||||||
way to fix this would be to move the `4` return into an `else` block:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
fn foo() -> i32 {
|
|
||||||
if some_cond {
|
|
||||||
2
|
|
||||||
} else {
|
|
||||||
4
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
Otherwise, the compiler will think you are trying to use that `if` as a
|
|
||||||
statement, such as like this:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
let val = if some_cond { 2 } else { 4 };
|
|
||||||
```
|
|
||||||
|
|
||||||
### Functions that can fail
|
|
||||||
|
|
||||||
The [Result](https://doc.rust-lang.org/std/result/) type represents things that
|
|
||||||
can fail with specific errors. The [eyre Result
|
|
||||||
type](https://docs.rs/eyre) represents things that can fail
|
|
||||||
with any error. For readability, this post will use the eyre Result type.
|
|
||||||
|
|
||||||
[The angle brackets in the `Result` type are arguments to the type, this allows
|
|
||||||
the Result type to work across any type you could imagine.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
```go
|
|
||||||
import "errors"
|
|
||||||
|
|
||||||
func divide(x, y int) (int, err) {
|
|
||||||
if y == 0 {
|
|
||||||
return 0, errors.New("cannot divide by zero")
|
|
||||||
}
|
|
||||||
|
|
||||||
return x / y, nil
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
```rust
|
|
||||||
use eyre::{eyre, Result};
|
|
||||||
|
|
||||||
fn divide(x: i32, y: i32) -> Result<i32> {
|
|
||||||
match y {
|
|
||||||
0 => Err(eyre!("cannot divide by zero")),
|
|
||||||
_ => Ok(x / y),
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
[Huh? I thought Rust had the <a
|
|
||||||
href="https://doc.rust-lang.org/std/error/trait.Error.html">Error trait</a>,
|
|
||||||
shouldn't you be able to use that instead of a third party package like
|
|
||||||
eyre?](conversation://Mara/wat)
|
|
||||||
|
|
||||||
Let's try that, however we will need to make our own error type because the
|
|
||||||
[`eyre!`](https://docs.rs/eyre/0.6.0/eyre/macro.eyre.html) macro creates its own
|
|
||||||
transient error type on the fly.
|
|
||||||
|
|
||||||
First we need to make our own simple error type for a DivideByZero error:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
use std::error::Error;
|
|
||||||
use std::fmt;
|
|
||||||
|
|
||||||
#[derive(Debug)]
|
|
||||||
struct DivideByZero;
|
|
||||||
|
|
||||||
impl fmt::Display for DivideByZero {
|
|
||||||
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
|
|
||||||
write!(f, "cannot divide by zero")
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
impl Error for DivideByZero {}
|
|
||||||
```
|
|
||||||
|
|
||||||
So now let's use it:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
fn divide(x: i32, y: i32) -> Result<i32, DivideByZero> {
|
|
||||||
match y {
|
|
||||||
0 => Err(DivideByZero{}),
|
|
||||||
_ => Ok(x / y),
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
However there is still one thing left: the function returns a DivideByZero
|
|
||||||
error, not _any_ error like the [error interface in
|
|
||||||
Go](https://godoc.org/builtin#error). In order to represent that we need to
|
|
||||||
return something that implements the Error trait:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
fn divide(x: i32, y: i32) -> Result<i32, impl Error> {
|
|
||||||
// ...
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
And for the simple case, this will work. However as things get more complicated
|
|
||||||
this simple facade will not work due to reality and its complexities. This is
|
|
||||||
why I am shipping as much as I can out to other packages like eyre or
|
|
||||||
[anyhow](https://docs.rs/anyhow). Check out this code in the [Rust
|
|
||||||
Playground](https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=946057d8eb02f388cb3f03bae226d10d)
|
|
||||||
to mess with this code interactively.
|
|
||||||
|
|
||||||
[Pro tip: eyre (via <a href="https://docs.rs/color-eyre">color-eyre</a>) also
|
|
||||||
has support for adding <a href="https://docs.rs/color-eyre/0.5.4/color_eyre/#custom-sections-for-error-reports-via-help-trait">custom
|
|
||||||
sections and context</a> to errors similar to Go's <a href="https://godoc.org/fmt#Errorf">`fmt.Errorf` `%w`
|
|
||||||
format argument</a>, which will help in real world
|
|
||||||
applications. When you do need to actually make your own errors, you may want to look into
|
|
||||||
crates like <a href="https://docs.rs/thiserror">thiserror</a> to help with
|
|
||||||
automatically generating your error implementation.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
### The `?` Operator
|
|
||||||
|
|
||||||
In Rust, the `?` operator checks for an error in a function call and if there is
|
|
||||||
one, it automatically returns the error and gives you the result of the function
|
|
||||||
if there was no error. This only works in functions that return either an Option
|
|
||||||
or a Result.
|
|
||||||
|
|
||||||
[The <a href="https://doc.rust-lang.org/std/option/index.html">Option</a> type
|
|
||||||
isn't shown in very much detail here, but it acts like a "this thing might not exist and it's your
|
|
||||||
responsibility to check" container for any value. The closest analogue in Go is
|
|
||||||
making a pointer to a value or possibly putting a value in an `interface{}`
|
|
||||||
(which can be annoying to deal with in practice).](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
```go
|
|
||||||
func doThing() (int, error) {
|
|
||||||
result, err := divide(3, 4)
|
|
||||||
if err != nil {
|
|
||||||
return 0, err
|
|
||||||
}
|
|
||||||
|
|
||||||
return result, nil
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
```rust
|
|
||||||
use eyre::Result;
|
|
||||||
|
|
||||||
fn do_thing() -> Result<i32> {
|
|
||||||
let result = divide(3, 4)?;
|
|
||||||
Ok(result)
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
If the second argument of divide is changed to `0`, then `do_thing` will return
|
|
||||||
an error.
|
|
||||||
|
|
||||||
[And how does that work with eyre?](conversation://Mara/hmm)
|
|
||||||
|
|
||||||
It works with eyre because eyre has its own error wrapper type called
|
|
||||||
[`Report`](https://docs.rs/eyre/0.6.0/eyre/struct.Report.html), which can
|
|
||||||
represent anything that implements the Error trait.
|
|
||||||
|
|
||||||
## Macros
|
|
||||||
|
|
||||||
Rust macros are function calls with `!` after their name:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
println!("hello, world");
|
|
||||||
```
|
|
||||||
|
|
||||||
## Variables
|
|
||||||
|
|
||||||
Variables are created using `let`:
|
|
||||||
|
|
||||||
```go
|
|
||||||
var foo int
|
|
||||||
var foo = 3
|
|
||||||
foo := 3
|
|
||||||
```
|
|
||||||
|
|
||||||
```rust
|
|
||||||
let foo: i32;
|
|
||||||
let foo = 3;
|
|
||||||
```
|
|
||||||
|
|
||||||
### Mutability
|
|
||||||
|
|
||||||
In Rust, every variable is immutable (unchangeable) by default. If we try to
|
|
||||||
change those variables above we get a compiler error:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
fn main() {
|
|
||||||
let foo: i32;
|
|
||||||
let foo = 3;
|
|
||||||
foo = 4;
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
This makes the compiler return this error:
|
|
||||||
|
|
||||||
```
|
|
||||||
error[E0384]: cannot assign twice to immutable variable `foo`
|
|
||||||
--> src/main.rs:4:5
|
|
||||||
|
|
|
||||||
3 | let foo = 3;
|
|
||||||
| ---
|
|
||||||
| |
|
|
||||||
| first assignment to `foo`
|
|
||||||
| help: make this binding mutable: `mut foo`
|
|
||||||
4 | foo = 4;
|
|
||||||
| ^^^^^^^ cannot assign twice to immutable variable
|
|
||||||
```
|
|
||||||
|
|
||||||
As the compiler suggests, you can create a mutable variable by adding the `mut`
|
|
||||||
keyword after the `let` keyword. There is no analog to this in Go.
|
|
||||||
|
|
||||||
```rust
|
|
||||||
let mut foo: i32 = 0;
|
|
||||||
foo = 4;
|
|
||||||
```
|
|
||||||
|
|
||||||
[This is slightly a lie. There's more advanced cases involving interior
|
|
||||||
mutability and other fun stuff like that, however this is a more advanced topic
|
|
||||||
that isn't covered here.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
### Lifetimes
|
|
||||||
|
|
||||||
Rust does garbage collection at compile time. It also passes ownership of memory
|
|
||||||
to functions as soon as possible. Lifetimes are how Rust calculates how "long" a
|
|
||||||
given bit of data should exist in the program. Rust will then tell the compiled
|
|
||||||
code to destroy the data from memory as soon as possible.
|
|
||||||
|
|
||||||
[This is slightly inaccurate in order to make this simpler to explain and
|
|
||||||
understand. It's probably more accurate to say that Rust calculates _when_ to
|
|
||||||
collect garbage at compile time, but the difference doesn't really matter for
|
|
||||||
most cases](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
For example, this code will fail to compile because `quo` was moved into the
|
|
||||||
second divide call:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
let quo = divide(4, 8)?;
|
|
||||||
let other_quo = divide(quo, 5)?;
|
|
||||||
|
|
||||||
// Fails compile because ownership of quo was given to divide to create other_quo
|
|
||||||
let yet_another_quo = divide(quo, 4)?;
|
|
||||||
```
|
|
||||||
|
|
||||||
To work around this you can pass a reference to the divide function:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
let other_quo = divide(&quo, 5);
|
|
||||||
let yet_another_quo = divide(&quo, 4)?;
|
|
||||||
```
|
|
||||||
|
|
||||||
Or even create a clone of it:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
let other_quo = divide(quo.clone(), 5);
|
|
||||||
let yet_another_quo = divide(quo, 4)?;
|
|
||||||
```
|
|
||||||
|
|
||||||
[You can also get more fancy with <a
|
|
||||||
href="https://doc.rust-lang.org/rust-by-example/scope/lifetime/explicit.html">explicit
|
|
||||||
lifetime annotations</a>, however as of Rust's 2018 edition they aren't usually
|
|
||||||
required unless you are doing something weird. This is something that is also
|
|
||||||
covered in more detail in <a
|
|
||||||
href="https://doc.rust-lang.org/stable/book/ch04-00-understanding-ownership.html">The
|
|
||||||
Rust Book</a>.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
### Passing Mutability
|
|
||||||
|
|
||||||
Sometimes functions need mutable variables. To pass a mutable reference, add
|
|
||||||
`&mut` before the name of the variable:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
let something = do_something_to_quo(&mut quo)?;
|
|
||||||
```
|
|
||||||
|
|
||||||
## Project Setup
|
|
||||||
|
|
||||||
### Imports
|
|
||||||
|
|
||||||
External dependencies are declared using the [Cargo.toml
|
|
||||||
file](https://doc.rust-lang.org/cargo/reference/specifying-dependencies.html):
|
|
||||||
|
|
||||||
```toml
|
|
||||||
# Cargo.toml
|
|
||||||
|
|
||||||
[dependencies]
|
|
||||||
eyre = "0.6"
|
|
||||||
```
|
|
||||||
|
|
||||||
This depends on the crate [eyre](https://crates.io/crates/eyre) at version
|
|
||||||
0.6.x.
|
|
||||||
|
|
||||||
[You can do much more with version requirements with cargo, see more <a
|
|
||||||
href="https://doc.rust-lang.org/cargo/reference/specifying-dependencies.html">here</a>.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
Dependencies can also have optional features:
|
|
||||||
|
|
||||||
```toml
|
|
||||||
# Cargo.toml
|
|
||||||
|
|
||||||
[dependencies]
|
|
||||||
reqwest = { version = "0.10", features = ["json"] }
|
|
||||||
```
|
|
||||||
|
|
||||||
This depends on the crate [reqwest](https://crates.io/reqwest) at version 0.10.x
|
|
||||||
with the `json` feature enabled (in this case it enables reqwest being able to
|
|
||||||
automagically convert things to/from json using Serde).
|
|
||||||
|
|
||||||
External dependencies can be used with the `use` statement:
|
|
||||||
|
|
||||||
```go
|
|
||||||
// go
|
|
||||||
|
|
||||||
import "github.com/foo/bar"
|
|
||||||
```
|
|
||||||
|
|
||||||
```rust
|
|
||||||
use foo; // -> foo now has the members of crate foo behind the :: operator
|
|
||||||
use foo::Bar; // -> Bar is now exposed as a type in this file
|
|
||||||
|
|
||||||
use eyre::{eyre, Result}; // exposes the eyre! and Result members of eyre
|
|
||||||
```
|
|
||||||
|
|
||||||
[This doesn't cover how the <a
|
|
||||||
href="http://www.sheshbabu.com/posts/rust-module-system/">module system</a>
|
|
||||||
works, however the post I linked there covers this better than I
|
|
||||||
can.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
## Async/Await
|
|
||||||
|
|
||||||
Async functions may be interrupted to let other things execute as needed. This
|
|
||||||
program uses [tokio](https://tokio.rs/) to handle async tasks. To run an async
|
|
||||||
task and wait for its result, do this:
|
|
||||||
|
|
||||||
```
|
|
||||||
let printer_fact = reqwest::get("https://printerfacts.cetacean.club/fact")
|
|
||||||
.await?
|
|
||||||
.text()
|
|
||||||
.await?;
|
|
||||||
println!("your printer fact is: {}", printer_fact);
|
|
||||||
```
|
|
||||||
|
|
||||||
This will populate `response` with an amusing fact about everyone's favorite
|
|
||||||
household pet, the [printer](https://printerfacts.cetacean.club).
|
|
||||||
|
|
||||||
To make an async function, add the `async` keyword before the `fn` keyword:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
async fn get_text(url: String) -> Result<String> {
|
|
||||||
reqwest::get(&url)
|
|
||||||
.await?
|
|
||||||
.text()
|
|
||||||
.await?
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
This can then be called like this:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
let printer_fact = get_text("https://printerfacts.cetacean.club/fact").await?;
|
|
||||||
```
|
|
||||||
|
|
||||||
## Public/Private Types and Functions
|
|
||||||
|
|
||||||
Rust has three privacy levels for functions:
|
|
||||||
|
|
||||||
- Only visible to the current file (no keyword, lowercase in Go)
|
|
||||||
- Visible to anything in the current crate (`pub(crate)`, internal packages in
|
|
||||||
go)
|
|
||||||
- Visible to everyone (`pub`, upper case in Go)
|
|
||||||
|
|
||||||
[You can't get a perfect analog to `pub(crate)` in Go, but <a
|
|
||||||
href="https://docs.google.com/document/d/1e8kOo3r51b2BWtTs_1uADIA5djfXhPT36s6eHVRIvaU/edit">internal
|
|
||||||
packages</a> can get close to this behavior. Additionally you can have a lot
|
|
||||||
more control over access levels than this, see <a
|
|
||||||
href="https://doc.rust-lang.org/nightly/reference/visibility-and-privacy.html">here</a>
|
|
||||||
for more information.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
## Structures
|
|
||||||
|
|
||||||
Rust structures are created using the `struct` keyword:
|
|
||||||
|
|
||||||
```go
|
|
||||||
type Client struct {
|
|
||||||
Token string
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
```rust
|
|
||||||
pub struct Client {
|
|
||||||
pub token: String,
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
If the `pub` keyword is not specified before a member name, it will not be
|
|
||||||
usable outside the Rust source code file it is defined in:
|
|
||||||
|
|
||||||
```go
|
|
||||||
type Client struct {
|
|
||||||
token string
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
```rust
|
|
||||||
pub(crate) struct Client {
|
|
||||||
token: String,
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
### Encoding structs to JSON
|
|
||||||
|
|
||||||
[serde](https://serde.rs) is used to convert structures to json. The Rust
|
|
||||||
compiler's
|
|
||||||
[derive](https://doc.rust-lang.org/stable/rust-by-example/trait/derive.html)
|
|
||||||
feature is used to automatically implement the conversion logic.
|
|
||||||
|
|
||||||
```go
|
|
||||||
type Response struct {
|
|
||||||
Name string `json:"name"`
|
|
||||||
Description *string `json:"description,omitempty"`
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
```rust
|
|
||||||
use serde::{Serialize, Deserialize};
|
|
||||||
|
|
||||||
#[derive(Serialize, Deserialize, Debug)]
|
|
||||||
pub(crate) struct Response {
|
|
||||||
pub name: String,
|
|
||||||
pub description: Option<String>,
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
## Strings
|
|
||||||
|
|
||||||
Rust has a few string types that do different things. You can read more about
|
|
||||||
this [here](https://fasterthanli.me/blog/2020/working-with-strings-in-rust/),
|
|
||||||
but at a high level most projects only uses a few of them:
|
|
||||||
|
|
||||||
- `&str`, a slice reference to a String owned by someone else
|
|
||||||
- String, an owned UTF-8 string
|
|
||||||
- PathBuf, a filepath string (encoded in whatever encoding the OS running this
|
|
||||||
code uses for filesystems)
|
|
||||||
|
|
||||||
The strings are different types for safety reasons. See the linked blogpost for
|
|
||||||
more detail about this.
|
|
||||||
|
|
||||||
## Enumerations / Tagged Unions
|
|
||||||
|
|
||||||
Enumerations, also known as tagged unions, are a way to specify a superposition
|
|
||||||
of one of a few different kinds of values in one type. A neat way to show them
|
|
||||||
off (along with some other fancy features like the derivation system) is with the
|
|
||||||
[structopt](https://docs.rs/structopt/0.3.14/structopt/) crate. There is no easy
|
|
||||||
analog for this in Go.
|
|
||||||
|
|
||||||
[We've actually been dealing with enumerations ever since we touched the Result
|
|
||||||
type earlier. <a
|
|
||||||
href="https://doc.rust-lang.org/std/result/enum.Result.html">Result</a> and <a
|
|
||||||
href="https://doc.rust-lang.org/std/option/enum.Option.html">Option</a> are
|
|
||||||
implemented with enumerations.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
```rust
|
|
||||||
#[derive(StructOpt, Debug)]
|
|
||||||
#[structopt(about = "A simple release management tool")]
|
|
||||||
pub(crate) enum Cmd {
|
|
||||||
/// Creates a new release for a git repo
|
|
||||||
Cut {
|
|
||||||
#[structopt(flatten)]
|
|
||||||
common: Common,
|
|
||||||
/// Changelog location
|
|
||||||
#[structopt(long, short, default_value="./CHANGELOG.md")]
|
|
||||||
changelog: PathBuf,
|
|
||||||
},
|
|
||||||
|
|
||||||
/// Runs releases as triggered by GitHub Actions
|
|
||||||
GitHubAction {
|
|
||||||
#[structopt(flatten)]
|
|
||||||
gha: GitHubAction,
|
|
||||||
},
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
Enum variants can be matched using the `match` keyword:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
match cmd {
|
|
||||||
Cmd::Cut { common, changelog } => {
|
|
||||||
cmd::cut::run(common, changelog).await
|
|
||||||
}
|
|
||||||
Cmd::GitHubAction { gha } => {
|
|
||||||
cmd::github_action::run(gha).await
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
All variants of an enum must be matched in order for the code to compile.
|
|
||||||
|
|
||||||
[This code was borrowed from <a
|
|
||||||
href="https://github.com/lightspeed/palisade">palisade</a> in order to
|
|
||||||
demonstrate this better. If you want to see these patterns in action, check this
|
|
||||||
repository out!](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
## Testing
|
|
||||||
|
|
||||||
Test functions need to be marked with the `#[test]` annotation, then they will
|
|
||||||
be run alongside `cargo test`:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
mod tests { // not required but it is good practice
|
|
||||||
#[test]
|
|
||||||
fn math_works() {
|
|
||||||
assert_eq!(2 + 2, 4);
|
|
||||||
}
|
|
||||||
|
|
||||||
#[tokio::test] // needs tokio as a dependency
|
|
||||||
async fn http_works() {
|
|
||||||
let _ = get_html("https://within.website").await.unwrap();
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
Avoid the use of `unwrap()` outside of tests. In the wrong cases, using
|
|
||||||
`unwrap()` in production code can cause the server to crash and can incur data
|
|
||||||
loss.
|
|
||||||
|
|
||||||
[Alternatively, you can also use the <a href="https://learning-rust.github.io/docs/e4.unwrap_and_expect.html#expect">`.expect()`</a> method instead
|
|
||||||
of `.unwrap()`. This lets you attach a message that will be shown when the
|
|
||||||
result isn't Ok.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
This is by no means comprehensive, see the rust book or [Learn X in Y Minutes
|
|
||||||
Where X = Rust](https://learnxinyminutes.com/docs/rust/) for more information.
|
|
||||||
This code is written to be as boring and obvious as possible. If things don't
|
|
||||||
make sense, please reach out and don't be afraid to ask questions.
|
|
||||||
|
|
@ -23,13 +23,13 @@ This is a surprisingly hard question to answer. Most of the time though, I know
|
||||||
|
|
||||||
Art doesn't have to follow conventional ideas of what most people think "art" is. Art can be just about anything that you can classify as art. As a conventional example, consider something like the Mona Lisa:
|
Art doesn't have to follow conventional ideas of what most people think "art" is. Art can be just about anything that you can classify as art. As a conventional example, consider something like the Mona Lisa:
|
||||||
|
|
||||||

|
<center>  </center>
|
||||||
|
|
||||||
People will accept this as art without much argument. It's a painting, it obviously took a lot of skill and time to create. It is said that Leonardo Da Vinci (the artist of the painting) created it partially [as a contribution to the state of the art of oil painting][monalisawhy].
|
People will accept this as art without much argument. It's a painting, it obviously took a lot of skill and time to create. It is said that Leonardo Da Vinci (the artist of the painting) created it partially [as a contribution to the state of the art of oil painting][monalisawhy].
|
||||||
|
|
||||||
So that painting is art, and a lot of people would consider it art; so what *would* a lot of people *not* consider art? Here's an example:
|
So that painting is art, and a lot of people would consider it art; so what *would* a lot of people *not* consider art? Here's an example:
|
||||||
|
|
||||||

|
<center>  </center>
|
||||||
|
|
||||||
This is *Untitled (Perfect Lovers)* by Felix Gonzalez. If you just take a look at it without context, it's just two battery-operated clocks on a wall. Where is the expertise and the like that goes into this? This is just the result of someone buying two clocks from the store and putting them somewhere, right?
|
This is *Untitled (Perfect Lovers)* by Felix Gonzalez. If you just take a look at it without context, it's just two battery-operated clocks on a wall. Where is the expertise and the like that goes into this? This is just the result of someone buying two clocks from the store and putting them somewhere, right?
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -1,229 +0,0 @@
|
||||||
---
|
|
||||||
title: "</kubernetes>"
|
|
||||||
date: 2021-01-03
|
|
||||||
---
|
|
||||||
|
|
||||||
# </kubernetes>
|
|
||||||
|
|
||||||
Well, since I posted [that last post](/blog/k8s-pondering-2020-12-31) I have had
|
|
||||||
an adventure. A good friend pointed out a server host that I had missed when I
|
|
||||||
was looking for other places to use, and now I have migrated my blog to this new
|
|
||||||
server. As of yesterday, I now run my website on a dedicated server in Finland.
|
|
||||||
Here is the story of my journey to migrate 6 years of cruft and technical debt
|
|
||||||
to this new server.
|
|
||||||
|
|
||||||
Let's talk about this goliath of a server. This server is an AX41 from Hetzner.
|
|
||||||
It has 64 GB of ram, a 512 GB nvme drive, 3 2 TB drives, and a Ryzen 3600. For
|
|
||||||
all practical concerns, this beast is beyond overkill and rivals my workstation
|
|
||||||
tower in everything but the GPU power. I have named it `lufta`, which is the
|
|
||||||
word for feather in [L'ewa](https://lewa.within.website/dictionary.html).
|
|
||||||
|
|
||||||
## Assimilation
|
|
||||||
|
|
||||||
For my server setup process, the first step it to assimilate it. In this step I
|
|
||||||
get a base NixOS install on it somehow. Since I was using Hetzner, I was able to
|
|
||||||
boot into a NixOS install image using the process documented
|
|
||||||
[here](https://nixos.wiki/wiki/Install_NixOS_on_Hetzner_Online). Then I decided
|
|
||||||
that it would also be cool to have this server use
|
|
||||||
[zfs](https://en.wikipedia.org/wiki/ZFS) as its filesystem to take advantage of
|
|
||||||
its legendary subvolume and snapshotting features.
|
|
||||||
|
|
||||||
So I wrote up a bootstrap system definition like the Hetzner tutorial said and
|
|
||||||
ended up with `hosts/lufta/bootstrap.nix`:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
{ pkgs, ... }:
|
|
||||||
|
|
||||||
{
|
|
||||||
services.openssh.enable = true;
|
|
||||||
users.users.root.openssh.authorizedKeys.keys = [
|
|
||||||
"ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIPg9gYKVglnO2HQodSJt4z4mNrUSUiyJQ7b+J798bwD9 cadey@shachi"
|
|
||||||
];
|
|
||||||
|
|
||||||
networking.usePredictableInterfaceNames = false;
|
|
||||||
systemd.network = {
|
|
||||||
enable = true;
|
|
||||||
networks."eth0".extraConfig = ''
|
|
||||||
[Match]
|
|
||||||
Name = eth0
|
|
||||||
[Network]
|
|
||||||
# Add your own assigned ipv6 subnet here here!
|
|
||||||
Address = 2a01:4f9:3a:1a1c::/64
|
|
||||||
Gateway = fe80::1
|
|
||||||
# optionally you can do the same for ipv4 and disable DHCP (networking.dhcpcd.enable = false;)
|
|
||||||
Address = 135.181.162.99/26
|
|
||||||
Gateway = 135.181.162.65
|
|
||||||
'';
|
|
||||||
};
|
|
||||||
|
|
||||||
boot.supportedFilesystems = [ "zfs" ];
|
|
||||||
|
|
||||||
environment.systemPackages = with pkgs; [ wget vim zfs ];
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
Then I fired up the kexec tarball and waited for the server to boot into a NixOS
|
|
||||||
live environment. A few minutes later I was in. I started formatting the drives
|
|
||||||
according to the [NixOS install
|
|
||||||
guide](https://nixos.org/manual/nixos/stable/index.html#sec-installation) with
|
|
||||||
one major difference: I added a `/boot` ext4 partition on the SSD. This allows
|
|
||||||
me to have the system root device on zfs. I added the disks to a `raidz1` pool
|
|
||||||
and created a few volumes. I also added the SSD as a log device so I get SSD
|
|
||||||
caching.
|
|
||||||
|
|
||||||
From there I installed NixOS as normal and rebooted the server. It booted
|
|
||||||
normally. I had a shiny new NixOS server in the cloud! I noticed that the server
|
|
||||||
had booted into NixOS unstable as opposed to NixOS 20.09 like my other nodes. I
|
|
||||||
thought "ah, well, that probably isn't a problem" and continued to the
|
|
||||||
configuration step.
|
|
||||||
|
|
||||||
[That's ominous...](conversation://Mara/hmm)
|
|
||||||
|
|
||||||
## Configuration
|
|
||||||
|
|
||||||
Now that the server was assimilated and I could SSH into it, the next step was
|
|
||||||
to configure it to run my services. While I was waiting for Hetzner to provision
|
|
||||||
my server I ported a bunch of my services over to Nixops services [a-la this
|
|
||||||
post](/blog/nixops-services-2020-11-09) in [this
|
|
||||||
folder](https://github.com/Xe/nixos-configs/tree/master/common/services) of my
|
|
||||||
configs repo.
|
|
||||||
|
|
||||||
Now that I had them, it was time to add this server to my Nixops setup. So I
|
|
||||||
opened the [nixops definition
|
|
||||||
folder](https://github.com/Xe/nixos-configs/tree/master/nixops/hexagone) and
|
|
||||||
added the metadata for `lufta`. Then I added it to my Nixops deployment with
|
|
||||||
this command:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ nixops modify -d hexagone -n hexagone *.nix
|
|
||||||
```
|
|
||||||
|
|
||||||
Then I copied over the autogenerated config from `lufta`'s `/etc/nixos/` folder
|
|
||||||
into
|
|
||||||
[`hosts/lufta`](https://github.com/Xe/nixos-configs/tree/master/hosts/lufta) and
|
|
||||||
ran a `nixops deploy` to add some other base configuration.
|
|
||||||
|
|
||||||
## Migration
|
|
||||||
|
|
||||||
Once that was done, I started enabling my services and pushing configs to test
|
|
||||||
them. After I got to a point where I thought things would work I opened up the
|
|
||||||
Kubernetes console and started deleting deployments on my kubernetes cluster as
|
|
||||||
I felt "safe" to migrate them over. Then I saw the deployments come back. I
|
|
||||||
deleted them again and they came back again.
|
|
||||||
|
|
||||||
Oh, right. I enabled that one Kubernetes service that made it intentionally hard
|
|
||||||
to delete deployments. One clever set of scale-downs and kills later and I was
|
|
||||||
able to kill things with wild abandon.
|
|
||||||
|
|
||||||
I copied over the gitea data with `rsync` running in the kubernetes deployment.
|
|
||||||
Then I killed the gitea deployment, updated DNS and reran a whole bunch of gitea
|
|
||||||
jobs to resanify the environment. I did a test clone on a few of my repos and
|
|
||||||
then I deleted the gitea volume from DigitalOcean.
|
|
||||||
|
|
||||||
Moving over the other deployments from Kubernetes into NixOS services was
|
|
||||||
somewhat easy, however I did need to repackage a bunch of my programs and static
|
|
||||||
sites for NixOS. I made the
|
|
||||||
[`pkgs`](https://github.com/Xe/nixos-configs/tree/master/pkgs) tree a bit more
|
|
||||||
fleshed out to compensate.
|
|
||||||
|
|
||||||
[Okay, packaging static sites in NixOS is beyond overkill, however a lot of them
|
|
||||||
need some annoyingly complicated build steps and throwing it all into Nix means
|
|
||||||
that we can make them reproducible and use one build system to rule them
|
|
||||||
all. Not to mention that when I need to upgrade the system, everything will
|
|
||||||
rebuild with new system libraries to avoid the <a
|
|
||||||
href="https://blog.tidelift.com/bit-rot-the-silent-killer">Docker bitrot
|
|
||||||
problem</a>.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
## Reboot Test
|
|
||||||
|
|
||||||
After a significant portion of the services were moved over, I decided it was
|
|
||||||
time to do the reboot test. I ran the `reboot` command and then...nothing.
|
|
||||||
My continuous ping test was timing out. My phone was blowing up with downtime
|
|
||||||
messages from NodePing. Yep, I messed something up.
|
|
||||||
|
|
||||||
I was able to boot the server back into a NixOS recovery environment using the
|
|
||||||
kexec trick, and from there I was able to prove the following:
|
|
||||||
|
|
||||||
- The zfs setup is healthy
|
|
||||||
- I can read some of the data I migrated over
|
|
||||||
- I can unmount and remount the ZFS volumes repeatedly
|
|
||||||
|
|
||||||
I was confused. This shouldn't be happening. After half an hour of
|
|
||||||
troubleshooting, I gave in and ordered an IPKVM to be installed in my server.
|
|
||||||
|
|
||||||
Once that was set up (and I managed to trick MacOS into letting me boot a .jnlp
|
|
||||||
web start file), I rebooted the server so I could see what error I was getting
|
|
||||||
on boot. I missed it the first time around, but on the second time I was able to
|
|
||||||
capture this screenshot:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Then it hit me. I did the install on NixOS unstable. My other servers use NixOS
|
|
||||||
20.09. I had downgraded zfs and the older version of zfs couldn't mount the
|
|
||||||
volume created by the newer version of zfs in read/write mode. One more trip to
|
|
||||||
the recovery environment later to install NixOS unstable in a new generation.
|
|
||||||
|
|
||||||
Then I switched my tower's default NixOS channel to the unstable channel and ran
|
|
||||||
`nixops deploy` to reactivate my services. After the NodePing uptime
|
|
||||||
notifications came in, I ran the reboot test again while looking at the console
|
|
||||||
output to be sure.
|
|
||||||
|
|
||||||
It booted. It worked. I had a stable setup. Then I reconnected to IRC and passed
|
|
||||||
out.
|
|
||||||
|
|
||||||
## Services Migrated
|
|
||||||
|
|
||||||
Here is a list of all of the services I have migrated over from my old dedicated
|
|
||||||
server, my kubernetes cluster and my dokku server:
|
|
||||||
|
|
||||||
- aerial -> discord chatbot
|
|
||||||
- goproxy -> go modules proxy
|
|
||||||
- lewa -> https://lewa.within.website
|
|
||||||
- hlang -> https://h.christine.website
|
|
||||||
- mi -> https://mi.within.website
|
|
||||||
- printerfacts -> https://printerfacts.cetacean.club
|
|
||||||
- xesite -> https://christine.website
|
|
||||||
- graphviz -> https://graphviz.christine.website
|
|
||||||
- idp -> https://idp.christine.website
|
|
||||||
- oragono -> ircs://irc.within.website:6697/
|
|
||||||
- tron -> discord bot
|
|
||||||
- withinbot -> discord bot
|
|
||||||
- withinwebsite -> https://within.website
|
|
||||||
- gitea -> https://tulpa.dev
|
|
||||||
- other static sites
|
|
||||||
|
|
||||||
Doing this migration is a bit of an archaeology project as well. I was
|
|
||||||
continuously discovering services that I had littered over my machines with very
|
|
||||||
poorly documented requirements and configuration. I hope that this move will let
|
|
||||||
the next time I do this kind of migration be a lot easier by comparison.
|
|
||||||
|
|
||||||
I still have a few other services to move over, however the ones that are left
|
|
||||||
are much more annoying to set up properly. I'm going to get to deprovision 5
|
|
||||||
servers in this migration and as a result get this stupidly powerful goliath of
|
|
||||||
a server to do whatever I want with and I also get to cut my monthly server
|
|
||||||
costs by over half.
|
|
||||||
|
|
||||||
I am very close to being able to turn off the Kubernetes cluster and use NixOS
|
|
||||||
for everything. A few services that are still on the Kubernetes cluster are
|
|
||||||
resistant to being nixified, so I may have to use the Docker containers for
|
|
||||||
that. I was hoping to be able to cut out Docker entirely, however we don't seem
|
|
||||||
to be that lucky yet.
|
|
||||||
|
|
||||||
Sure, there is some added latency with the server being in Europe instead of
|
|
||||||
Montreal, however if this ever becomes a practical issue I can always launch a
|
|
||||||
cheap DigitalOcean VPS in Toronto to act as a DNS server for my WireGuard setup.
|
|
||||||
|
|
||||||
Either way, I am now off Kubernetes for my highest traffic services. If services
|
|
||||||
of mine need to use the disk, they can now just use the disk. If I really care
|
|
||||||
about the data, I can add the service folders to the list of paths to back up to
|
|
||||||
`rsync.net` (I have a post about how this backup process works in the drafting
|
|
||||||
stage) via [borgbackup](https://www.borgbackup.org/).
|
|
||||||
|
|
||||||
Let's hope it stays online!
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
Many thanks to [Graham Christensen](https://twitter.com/grhmc), [Dave
|
|
||||||
Anderson](https://twitter.com/dave_universetf) and everyone else who has been
|
|
||||||
helping me along this journey. I would be lost without them.
|
|
||||||
|
|
@ -1,178 +0,0 @@
|
||||||
---
|
|
||||||
title: "How to Set Up Borg Backup on NixOS"
|
|
||||||
date: 2021-01-09
|
|
||||||
series: howto
|
|
||||||
tags:
|
|
||||||
- nixos
|
|
||||||
- borgbackup
|
|
||||||
---
|
|
||||||
|
|
||||||
# How to Set Up Borg Backup on NixOS
|
|
||||||
|
|
||||||
[Borg Backup](https://www.borgbackup.org/) is a encrypted, compressed,
|
|
||||||
deduplicated backup program for multiple platforms including Linux. This
|
|
||||||
combined with the [NixOS options for configuring
|
|
||||||
Borg Backup](https://search.nixos.org/options?channel=20.09&show=services.borgbackup.jobs.%3Cname%3E.paths&from=0&size=30&sort=relevance&query=services.borgbackup.jobs)
|
|
||||||
allows you to backup on a schedule and restore from those backups when you need
|
|
||||||
to.
|
|
||||||
|
|
||||||
Borg Backup works with local files, remote servers and there are even [cloud
|
|
||||||
hosts](https://www.borgbackup.org/support/commercial.html) that specialize in
|
|
||||||
hosting your backups. In this post we will cover how to set up a backup job on a
|
|
||||||
server using [BorgBase](https://www.borgbase.com/)'s free tier to host the
|
|
||||||
backup files.
|
|
||||||
|
|
||||||
## Setup
|
|
||||||
|
|
||||||
You will need a few things:
|
|
||||||
|
|
||||||
- A free BorgBase account
|
|
||||||
- A server running NixOS
|
|
||||||
- A list of folders to back up
|
|
||||||
- A list of folders to NOT back up
|
|
||||||
|
|
||||||
First, we will need to create a SSH key for root to use when connecting to
|
|
||||||
BorgBase. Open a shell as root on the server and make a `borgbackup` folder in
|
|
||||||
root's home directory:
|
|
||||||
|
|
||||||
```shell
|
|
||||||
mkdir borgbackup
|
|
||||||
cd borgbackup
|
|
||||||
```
|
|
||||||
|
|
||||||
Then create a SSH key that will be used to connect to BorgBase:
|
|
||||||
|
|
||||||
```shell
|
|
||||||
ssh-keygen -f ssh_key -t ed25519 -C "Borg Backup"
|
|
||||||
```
|
|
||||||
|
|
||||||
Ignore the SSH key password because at this time the automated Borg Backup job
|
|
||||||
doesn't allow the use of password-protected SSH keys.
|
|
||||||
|
|
||||||
Now we need to create an encryption passphrase for the backup repository. Run
|
|
||||||
this command to generate one using [xkcdpass](https://pypi.org/project/xkcdpass/):
|
|
||||||
|
|
||||||
```shell
|
|
||||||
nix-shell -p python39Packages.xkcdpass --run 'xkcdpass -n 12' > passphrase
|
|
||||||
```
|
|
||||||
|
|
||||||
[You can do whatever you want to generate a suitable passphrase, however
|
|
||||||
xkcdpass is proven to be <a href="https://xkcd.com/936/">more random</a> than
|
|
||||||
most other password generators.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
## BorgBase Setup
|
|
||||||
|
|
||||||
Now that we have the basic requirements out of the way, let's configure BorgBase
|
|
||||||
to use that SSH key. In the BorgBase UI click on the Account tab in the upper
|
|
||||||
right and open the SSH key management window. Click on Add Key and paste in the
|
|
||||||
contents of `./ssh_key.pub`. Name it after the hostname of the server you are
|
|
||||||
working on. Click Add Key and then go back to the Repositories tab in the upper
|
|
||||||
right.
|
|
||||||
|
|
||||||
Click New Repo and name it after the hostname of the server you are working on.
|
|
||||||
Select the key you just created to have full access. Choose the region of the
|
|
||||||
backup volume and then click Add Repository.
|
|
||||||
|
|
||||||
On the main page copy the repository path with the copy icon next to your
|
|
||||||
repository in the list. You will need this below. Attempt to SSH into the backup
|
|
||||||
repo in order to have ssh recognize the server's host key:
|
|
||||||
|
|
||||||
```shell
|
|
||||||
ssh -i ./ssh_key o6h6zl22@o6h6zl22.repo.borgbase.com
|
|
||||||
```
|
|
||||||
|
|
||||||
Then accept the host key and press control-c to terminate the SSH connection.
|
|
||||||
|
|
||||||
## NixOS Configuration
|
|
||||||
|
|
||||||
In your `configuration.nix` file, add the following block:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
services.borgbackup.jobs."borgbase" = {
|
|
||||||
paths = [
|
|
||||||
"/var/lib"
|
|
||||||
"/srv"
|
|
||||||
"/home"
|
|
||||||
];
|
|
||||||
exclude = [
|
|
||||||
# very large paths
|
|
||||||
"/var/lib/docker"
|
|
||||||
"/var/lib/systemd"
|
|
||||||
"/var/lib/libvirt"
|
|
||||||
|
|
||||||
# temporary files created by cargo and `go build`
|
|
||||||
"**/target"
|
|
||||||
"/home/*/go/bin"
|
|
||||||
"/home/*/go/pkg"
|
|
||||||
];
|
|
||||||
repo = "o6h6zl22@o6h6zl22.repo.borgbase.com:repo";
|
|
||||||
encryption = {
|
|
||||||
mode = "repokey-blake2";
|
|
||||||
passCommand = "cat /root/borgbackup/passphrase";
|
|
||||||
};
|
|
||||||
environment.BORG_RSH = "ssh -i /root/borgbackup/ssh_key";
|
|
||||||
compression = "auto,lzma";
|
|
||||||
startAt = "daily";
|
|
||||||
};
|
|
||||||
```
|
|
||||||
|
|
||||||
Customize the paths and exclude lists to your needs. Once you are satisfied,
|
|
||||||
rebuild your NixOS system using `nixos-rebuild`:
|
|
||||||
|
|
||||||
```shell
|
|
||||||
nixos-rebuild switch
|
|
||||||
```
|
|
||||||
|
|
||||||
And then you can fire off an initial backup job with this command:
|
|
||||||
|
|
||||||
```shell
|
|
||||||
systemctl start borgbackup-job-borgbase.service
|
|
||||||
```
|
|
||||||
|
|
||||||
Monitor the job with this command:
|
|
||||||
|
|
||||||
```shell
|
|
||||||
journalctl -fu borgbackup-job-borgbase.service
|
|
||||||
```
|
|
||||||
|
|
||||||
The first backup job will always take the longest to run. Every incremental
|
|
||||||
backup after that will get smaller and smaller. By default, the system will
|
|
||||||
create new backup snapshots every night at midnight local time.
|
|
||||||
|
|
||||||
## Restoring Files
|
|
||||||
|
|
||||||
To restore files, first figure out when you want to restore the files from.
|
|
||||||
NixOS includes a wrapper script for each Borg job you define. you can mount your
|
|
||||||
backup archive using this command:
|
|
||||||
|
|
||||||
```
|
|
||||||
mkdir mount
|
|
||||||
borg-job-borgbase mount o6h6zl22@o6h6zl22.repo.borgbase.com:repo ./mount
|
|
||||||
```
|
|
||||||
|
|
||||||
Then you can explore the backup (and with it each incremental snapshot) to
|
|
||||||
your heart's content and copy files out manually. You can look through each
|
|
||||||
folder and copy out what you need.
|
|
||||||
|
|
||||||
When you are done you can unmount it with this command:
|
|
||||||
|
|
||||||
```
|
|
||||||
borg-job-borgbase umount /root/borgbase/mount
|
|
||||||
```
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
And that's it! You can get more fancy with nixops using a setup [like
|
|
||||||
this](https://github.com/Xe/nixos-configs/blob/master/common/services/backup.nix).
|
|
||||||
In general though, you can get away with this setup. It may be a good idea to
|
|
||||||
copy down the encryption passphrase onto paper and put it in a safe space like a
|
|
||||||
safety deposit box.
|
|
||||||
|
|
||||||
For more information about Borg Backup on NixOS, see [the relevant chapter of
|
|
||||||
the NixOS
|
|
||||||
manual](https://nixos.org/manual/nixos/stable/index.html#module-borgbase) or
|
|
||||||
[the list of borgbackup
|
|
||||||
options](https://search.nixos.org/options?channel=20.09&query=services.borgbackup.jobs)
|
|
||||||
that you can pick from.
|
|
||||||
|
|
||||||
I hope this is able to help.
|
|
||||||
|
|
@ -1,73 +0,0 @@
|
||||||
---
|
|
||||||
title: Chicken Stir Fry
|
|
||||||
date: 2020-04-13
|
|
||||||
series: recipes
|
|
||||||
tags:
|
|
||||||
- instant-pot
|
|
||||||
- pan
|
|
||||||
- rice
|
|
||||||
- garlic
|
|
||||||
---
|
|
||||||
|
|
||||||
# Chicken Stir Fry
|
|
||||||
|
|
||||||
This recipe was made up by me and my fiancé. We just sorta winged it every time
|
|
||||||
we made it until we found something that was easy to cook and tasty. We make
|
|
||||||
this every week or so.
|
|
||||||
|
|
||||||
## Recipe
|
|
||||||
|
|
||||||
### Ingredients
|
|
||||||
|
|
||||||
- Pack of 4 chicken breasts
|
|
||||||
- A fair amount of Montreal seasoning (garlic, onion, salt, oregano)
|
|
||||||
- 3 cups basmati rice
|
|
||||||
- 3.75 cups water
|
|
||||||
- 1/4th bag of frozen stir fry vegetables
|
|
||||||
- Avocado/coconut oil
|
|
||||||
- Standard frying pan
|
|
||||||
- Standard chef's knife
|
|
||||||
- Standard 11x14 cutting board
|
|
||||||
- Two metal bowls
|
|
||||||
- Instant Pot
|
|
||||||
- Spatula
|
|
||||||
|
|
||||||
### Seasoning
|
|
||||||
|
|
||||||
Put the seasoning in one of the bowls and unwrap the plastic around the chicken
|
|
||||||
breasts. Take each chicken breast out of the package (you may need to cut them
|
|
||||||
free of eachother, use a sharp knife for that) and rub all sides of it around in
|
|
||||||
the seasoning.
|
|
||||||
|
|
||||||
Put these into the other metal bowl and when you've done all four, cover with
|
|
||||||
plastic wrap and refrigerate for about 5-6 hours.
|
|
||||||
|
|
||||||
Doing this helps to have the chicken soak up the flavor of the seasoning so it
|
|
||||||
tastes better when you cook it.
|
|
||||||
|
|
||||||
### Cooking
|
|
||||||
|
|
||||||
Slice two chicken breasts up kinda like
|
|
||||||
[this](https://www.seriouseats.com/2014/04/knife-skills-how-to-slice-chicken-breast-for-stir-fries.html)
|
|
||||||
and then transfer to the heated pan with oil in it. Cook those and flip them
|
|
||||||
every few minutes until you've cooked everything all the way through (random
|
|
||||||
sampling by cutting a bit of chicken in half with the spatula and seeing if it's
|
|
||||||
overly juicy or not is a good way to tell, or if you have a food thermometer to
|
|
||||||
165 degrees fahrenheit or 75 degrees celsius). Put this chicken into a plastic
|
|
||||||
container for use in other meals (it goes really good on sandwiches).
|
|
||||||
|
|
||||||
Then repeat the slicing and cooking for the last two chicken breasts. However,
|
|
||||||
this time put _half_ of the chicken into the plastic container you used before
|
|
||||||
(about one chicken breast worth in total, it doesn't have to be exact). At the
|
|
||||||
same time as the second round of chicken is cooking, put about 3 cups of rice
|
|
||||||
and 3.75 cups of water into the instant pot; then seal it and set it to manual
|
|
||||||
for 4 minutes.
|
|
||||||
|
|
||||||
Dump frozen vegetables on top of the remainder of the chicken and stir until the
|
|
||||||
vegetables are warm.
|
|
||||||
|
|
||||||
### Serving
|
|
||||||
|
|
||||||
Serve the stir fry hot on a bed of rice.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
@ -1,88 +0,0 @@
|
||||||
---
|
|
||||||
title: Colemak Layout - First Week
|
|
||||||
date: 2020-08-22
|
|
||||||
series: colemak
|
|
||||||
---
|
|
||||||
|
|
||||||
# Colemak Layout - First Week
|
|
||||||
|
|
||||||
A week ago I posted the last post in this series where I announced I was going
|
|
||||||
all colemak all the time. I have not been measuring words per minute (to avoid
|
|
||||||
psyching myself out), but so far my typing speed has gone from intolerably slow
|
|
||||||
to manageably slow. I have been only dipping back into qwerty for two main
|
|
||||||
things:
|
|
||||||
|
|
||||||
1. Passwords, specifically the ones I have in muscle memory
|
|
||||||
2. Coding at work that needs to be done fast
|
|
||||||
|
|
||||||
Other than that, everything else has been in colemak. I have written DnD-style
|
|
||||||
game notes, hacked at my own "Linux distro", started a few QMK keymaps and more
|
|
||||||
all via colemak.
|
|
||||||
|
|
||||||
Here are some of the lessons I've learned:
|
|
||||||
|
|
||||||
## Let Your Coworkers Know You Are Going to Be Slow
|
|
||||||
|
|
||||||
This kind of thing is a long tirm investment. In the short term, your
|
|
||||||
productivity is going to crash through the floor. This will feel frustrating. It
|
|
||||||
took me an entire workday to implement and test a HTTP handler/client for it in
|
|
||||||
Go. You will be making weird typos. Let your coworkers know so they don't jump
|
|
||||||
to the wrong conclusions too quickly.
|
|
||||||
|
|
||||||
Also, this goes without saying, but don't do this kind of change during crunch
|
|
||||||
time. That's a bit of a dick move.
|
|
||||||
|
|
||||||
## Print Out the Layout
|
|
||||||
|
|
||||||
I have the layout printed and taped to my monitor and iPad stand. This helps a
|
|
||||||
lot. Instead of looking at the keyboard, I look at the layout image and let my
|
|
||||||
fingers drift into position.
|
|
||||||
|
|
||||||
I also have a blank keyboard at my desk, this helps because I can't look at the
|
|
||||||
keycaps and become confused (however this has backfired with typing numbers,
|
|
||||||
lol). This keyboard has cherry MX blues though, which means it can be loud when
|
|
||||||
I get to typing up a storm.
|
|
||||||
|
|
||||||
## Have Friends Ask You What Layout You Are Using
|
|
||||||
|
|
||||||
Something that works for me is to have friends ask me what keyboard layout I am
|
|
||||||
using, so I can be mindful of the change. I have a few people asking me that on
|
|
||||||
the regular, so I can be accountable to them and myself.
|
|
||||||
|
|
||||||
## macOS and iPadOS have Colemak Out of the Box
|
|
||||||
|
|
||||||
The settings app lets you configure colemak input without having to jailbreak or
|
|
||||||
install a custom keyboard layout. Take advantage of this.
|
|
||||||
|
|
||||||
Someone has also created a colemak windows package for windows that includes an
|
|
||||||
IA-64 (Itanium) binary. It was last updated in 2004, and still works without
|
|
||||||
hassle on windows 10. It was the irst time I've ever seen an IA-64 windows
|
|
||||||
binary in the wild!
|
|
||||||
|
|
||||||
## Relearn How To Type Your Passwords
|
|
||||||
|
|
||||||
I type passwords from muscle memory. I have had to rediscover what they actually
|
|
||||||
are so I can relearn how to type them.
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
The colemak experiment continues. I also have a [ZSA
|
|
||||||
Moonlander](https://www.zsa.io/moonlander/) and the kit for a
|
|
||||||
[GergoPlex](https://www.gboards.ca/product/gergoplex) coming in the mail. Both
|
|
||||||
of these run [QMK](https://qmk.fm), which allows me to fully program them with a
|
|
||||||
rich macro engine. Here are a few of the macros I plan to use:
|
|
||||||
|
|
||||||
```c
|
|
||||||
// Programming
|
|
||||||
SUBS(ifErr, "if err != nil {\n\t\n}", KC_E, KC_I)
|
|
||||||
SUBS(goTest, "go test ./...\n", KC_G, KC_T)
|
|
||||||
SUBS(cargoTest, "cargo test\n", KC_C, KC_T)
|
|
||||||
```
|
|
||||||
|
|
||||||
This will autotype a few common things when I press the keys "ei", "gt", or "ct"
|
|
||||||
at the same time. I plan to add a few more as things turn up so I can more
|
|
||||||
quickly type common idioms or commands to save me time. The `if err != nil`
|
|
||||||
combination started as a joke, but I bet it will end up being incredibly
|
|
||||||
valuable.
|
|
||||||
|
|
||||||
Be well, take care of your hands.
|
|
||||||
|
|
@ -1,27 +0,0 @@
|
||||||
---
|
|
||||||
title: Colemak Layout - Beginning
|
|
||||||
date: 2020-08-15
|
|
||||||
series: colemak
|
|
||||||
---
|
|
||||||
|
|
||||||
# Colemak Layout - Beginning
|
|
||||||
|
|
||||||
I write a lot. On average I write a few kilobytes of text per day. This has been
|
|
||||||
adding up and is taking a huge toll on my hands, especially considering the
|
|
||||||
Covid situation. Something needs to change. I've been working on learning a new
|
|
||||||
keyboard layout: [Colemak](https://colemak.com).
|
|
||||||
|
|
||||||
This post will be shorter than most of my posts because I'm writing it with
|
|
||||||
Colemak enabled on my iPad. Writing this is painfully slow at the moment. My
|
|
||||||
sentences are short and choppy because those are easier to type.
|
|
||||||
|
|
||||||
I also have a [ZSA Moonlander](https://www.zsa.io/moonlander/) on the way, it
|
|
||||||
should be here in October or November. I will also be sure to write about that
|
|
||||||
once I get it in the mail.
|
|
||||||
|
|
||||||
So far, I have about 30 words per minute on the homerow, but once I go off the
|
|
||||||
homerow the speed tanks to less than about five.
|
|
||||||
|
|
||||||
However, I am making progress!
|
|
||||||
|
|
||||||
Be well all, don't stress your hands out.
|
|
||||||
|
|
@ -11,7 +11,7 @@ Death is a very misunderstood card in Tarot, but not for the reasons you'd think
|
||||||
|
|
||||||
Tarot does not see death in this way. Death, the skeleton knight wearing armor, does not see color, race or creed, thus he is depicted as a skeleton. He is riding towards a child and another younger person. The sun is rising in the distance, but even it cannot stop Death. Nor can royalty, as shown by the king under him, dead.
|
Tarot does not see death in this way. Death, the skeleton knight wearing armor, does not see color, race or creed, thus he is depicted as a skeleton. He is riding towards a child and another younger person. The sun is rising in the distance, but even it cannot stop Death. Nor can royalty, as shown by the king under him, dead.
|
||||||
|
|
||||||

|
<center></center>
|
||||||
|
|
||||||
Death, however, does not actually refer to the act of a physical body physically dying. Death is a change that cannot be reverted. The consequences of this change can and will affect what comes next, however.
|
Death, however, does not actually refer to the act of a physical body physically dying. Death is a change that cannot be reverted. The consequences of this change can and will affect what comes next, however.
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -92,7 +92,7 @@ the real thing that advances is the skill of the player. You make the
|
||||||
deliveries. You go the distance. You do your job as the post-apocalyptic UPS man
|
deliveries. You go the distance. You do your job as the post-apocalyptic UPS man
|
||||||
that America needs.
|
that America needs.
|
||||||
|
|
||||||

|
<center></center>
|
||||||
|
|
||||||
By [mmmintdesign](https://twitter.com/mmmintdesign) [source](https://twitter.com/mmmintdesign/status/1192856164331114497)
|
By [mmmintdesign](https://twitter.com/mmmintdesign) [source](https://twitter.com/mmmintdesign/status/1192856164331114497)
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -1,435 +0,0 @@
|
||||||
---
|
|
||||||
title: Dhall for Kubernetes
|
|
||||||
date: 2020-01-25
|
|
||||||
tags:
|
|
||||||
- dhall
|
|
||||||
- kubernetes
|
|
||||||
- witchcraft
|
|
||||||
---
|
|
||||||
|
|
||||||
# Dhall for Kubernetes
|
|
||||||
|
|
||||||
Kubernetes is a surprisingly complicated software package. Arguably, it has to
|
|
||||||
be that complicated as a result of the problems it solves being complicated; but
|
|
||||||
managing yaml configuration files for Kubernetes is a complicated task. [YAML][yaml]
|
|
||||||
doesn't have support for variables or type metadata. This means that the
|
|
||||||
validity (or sensibility) of a given Kubernetes configuration file (or files)
|
|
||||||
isn't easy to figure out without using a Kubernetes server.
|
|
||||||
|
|
||||||
[yaml]: https://yaml.org
|
|
||||||
|
|
||||||
In my [last post][cultk8s] about Kubernetes, I mentioned I had developed a tool
|
|
||||||
named [dyson][dyson] in order to help me manage Terraform as well as create
|
|
||||||
Kubernetes manifests from [a template][template]. This works for the majority of
|
|
||||||
my apps, but it is difficult to extend at this point for a few reasons:
|
|
||||||
|
|
||||||
[cultk8s]: https://christine.website/blog/the-cult-of-kubernetes-2019-09-07
|
|
||||||
[dyson]: https://github.com/Xe/within-terraform/tree/master/dyson
|
|
||||||
[template]: https://github.com/Xe/within-terraform/blob/master/dyson/src/dysonPkg/deployment_with_ingress.yaml
|
|
||||||
|
|
||||||
- It assumes that everything passed to it are already valid yaml terms
|
|
||||||
- It doesn't assert the type of any values passed to it
|
|
||||||
- It is difficult to add another container to a given deployment
|
|
||||||
- Environment variables implicitly depend on the presence of a private git repo
|
|
||||||
- It depends on the template being correct more than the output being correct
|
|
||||||
|
|
||||||
So, this won't scale. People in the community have created other solutions for
|
|
||||||
this like [Helm][helm], but a lot of them have some of the same basic problems.
|
|
||||||
Helm also assumes that your template is correct. [Kustomize][kustomize] does
|
|
||||||
help with a lot of the type-safe variable replacements, but it doesn't have the
|
|
||||||
ability to ensure your manifest is valid.
|
|
||||||
|
|
||||||
[helm]: https://helm.sh
|
|
||||||
[kustomize]: https://kustomize.io
|
|
||||||
|
|
||||||
I looked around for alternate solutions for a while and eventually found
|
|
||||||
[Dhall][dhall] thanks to a friend. Dhall is a _statically typed_ configuration
|
|
||||||
language. This means that you can ensure that inputs are _always_ the correct
|
|
||||||
type or the configuration file won't load. There's also a built-in
|
|
||||||
[dhall-to-yaml][dhallyaml] tool that can be used with the [Kubernetes
|
|
||||||
package][dhallk8s] in order to declare Kubernetes manifests in a type-safe way.
|
|
||||||
|
|
||||||
[dhall]: https://dhall-lang.org
|
|
||||||
[dhallyaml]: https://github.com/dhall-lang/dhall-haskell/tree/master/dhall-yaml#dhall-yaml
|
|
||||||
[dhallk8s]: https://github.com/dhall-lang/dhall-kubernetes
|
|
||||||
|
|
||||||
Here's a small example of Dhall and the yaml it generates:
|
|
||||||
|
|
||||||
```dhall
|
|
||||||
-- Mastodon usernames
|
|
||||||
[ { name = "Cadey", mastodon = "@cadey@mst3k.interlinked.me" }
|
|
||||||
, { name = "Nicole", mastodon = "@sharkgirl@mst3k.interlinked.me" }
|
|
||||||
]
|
|
||||||
```
|
|
||||||
|
|
||||||
Which produces:
|
|
||||||
|
|
||||||
```yaml
|
|
||||||
- mastodon: "@cadey@mst3k.interlinked.me"
|
|
||||||
name: Cadey
|
|
||||||
- mastodon: "@sharkgirl@mst3k.interlinked.me"
|
|
||||||
name: Nicole
|
|
||||||
```
|
|
||||||
|
|
||||||
Which is fine, but we still have the type-safety problem that you would have in
|
|
||||||
normal yaml. Dhall lets us define [record types][dhallrecord] for this data like
|
|
||||||
this:
|
|
||||||
|
|
||||||
[dhallrecord]: http://www.haskellforall.com/2020/01/dhall-year-in-review-2019-2020.html
|
|
||||||
|
|
||||||
```dhall
|
|
||||||
let User =
|
|
||||||
{ Type = { name : Text, mastodon : Optional Text }
|
|
||||||
, default = { name = "", mastodon = None }
|
|
||||||
}
|
|
||||||
|
|
||||||
let users =
|
|
||||||
[ User::{ name = "Cadey", mastodon = Some "@cadey@mst3k.interlinked.me" }
|
|
||||||
, User::{
|
|
||||||
, name = "Nicole"
|
|
||||||
, mastodon = Some "@sharkgirl@mst3k.interlinked.me"
|
|
||||||
}
|
|
||||||
]
|
|
||||||
|
|
||||||
in users
|
|
||||||
```
|
|
||||||
|
|
||||||
Which produces:
|
|
||||||
|
|
||||||
```yaml
|
|
||||||
- mastodon: "@cadey@mst3k.interlinked.me"
|
|
||||||
name: Cadey
|
|
||||||
- mastodon: "@sharkgirl@mst3k.interlinked.me"
|
|
||||||
name: Nicole
|
|
||||||
```
|
|
||||||
|
|
||||||
This is type-safe because you cannot add arbitrary fields to User instances
|
|
||||||
without the compiler rejecting it. Let's add an invalid "preferred_language"
|
|
||||||
field to Cadey's instance:
|
|
||||||
|
|
||||||
```
|
|
||||||
-- ...
|
|
||||||
let users =
|
|
||||||
[ User::{
|
|
||||||
, name = "Cadey"
|
|
||||||
, mastodon = Some "@cadey@mst3k.interlinked.me"
|
|
||||||
, preferred_language = "en-US"
|
|
||||||
}
|
|
||||||
-- ...
|
|
||||||
]
|
|
||||||
```
|
|
||||||
|
|
||||||
Which gives us:
|
|
||||||
|
|
||||||
```
|
|
||||||
$ dhall-to-yaml --file example.dhall
|
|
||||||
Error: Expression doesn't match annotation
|
|
||||||
|
|
||||||
{ + preferred_language : …
|
|
||||||
, …
|
|
||||||
}
|
|
||||||
|
|
||||||
4│ User::{ name = "Cadey", mastodon = Some "@cadey@mst3k.interlinked.me",
|
|
||||||
5│ preferred_language = "en-US" }
|
|
||||||
|
|
||||||
example.dhall:4:9
|
|
||||||
```
|
|
||||||
|
|
||||||
Or [this more detailed explanation][explanation] if you add the `--explain` flag
|
|
||||||
to the `dhall-to-yaml` call.
|
|
||||||
|
|
||||||
[explanation]: https://clbin.com/JtVWT
|
|
||||||
|
|
||||||
We tried to do something that violated the contract that the type specified.
|
|
||||||
This means that it's an invalid configuration and is therefore rejected and no
|
|
||||||
yaml file is created.
|
|
||||||
|
|
||||||
The Dhall Kubernetes package specifies record types for _every_ object available
|
|
||||||
by default in Kubernetes. This does mean that the package is incredibly large,
|
|
||||||
but it also makes sure that _everything_ you could possibly want to do in
|
|
||||||
Kubernetes matches what it expects. In the [package
|
|
||||||
documentation][k8sdhalldocs], they give an example where a
|
|
||||||
[Deployment][k8sdeployment] is created.
|
|
||||||
|
|
||||||
[k8sdhalldocs]: https://github.com/dhall-lang/dhall-kubernetes/tree/master/1.15#quickstart---a-simple-deployment
|
|
||||||
[k8sdeployment]: https://kubernetes.io/docs/concepts/workloads/controllers/deployment/
|
|
||||||
|
|
||||||
``` dhall
|
|
||||||
-- examples/deploymentSimple.dhall
|
|
||||||
|
|
||||||
-- Importing other files is done by specifying the HTTPS URL/disk location of
|
|
||||||
-- the file. Attaching a sha256 hash (obtained with `dhall freeze`) allows
|
|
||||||
-- the Dhall compiler to cache these files and speed up configuration loads
|
|
||||||
-- drastically.
|
|
||||||
let kubernetes =
|
|
||||||
https://raw.githubusercontent.com/dhall-lang/dhall-kubernetes/1.15/master/package.dhall
|
|
||||||
sha256:4bd5939adb0a5fc83d76e0d69aa3c5a30bc1a5af8f9df515f44b6fc59a0a4815
|
|
||||||
|
|
||||||
let deployment =
|
|
||||||
kubernetes.Deployment::{
|
|
||||||
, metadata = kubernetes.ObjectMeta::{ name = "nginx" }
|
|
||||||
, spec =
|
|
||||||
Some
|
|
||||||
kubernetes.DeploymentSpec::{
|
|
||||||
, replicas = Some 2
|
|
||||||
, template =
|
|
||||||
kubernetes.PodTemplateSpec::{
|
|
||||||
, metadata = kubernetes.ObjectMeta::{ name = "nginx" }
|
|
||||||
, spec =
|
|
||||||
Some
|
|
||||||
kubernetes.PodSpec::{
|
|
||||||
, containers =
|
|
||||||
[ kubernetes.Container::{
|
|
||||||
, name = "nginx"
|
|
||||||
, image = Some "nginx:1.15.3"
|
|
||||||
, ports =
|
|
||||||
[ kubernetes.ContainerPort::{
|
|
||||||
, containerPort = 80
|
|
||||||
}
|
|
||||||
]
|
|
||||||
}
|
|
||||||
]
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
in deployment
|
|
||||||
```
|
|
||||||
|
|
||||||
Which creates the following yaml:
|
|
||||||
|
|
||||||
```
|
|
||||||
apiVersion: apps/v1
|
|
||||||
kind: Deployment
|
|
||||||
metadata:
|
|
||||||
name: nginx
|
|
||||||
spec:
|
|
||||||
replicas: 2
|
|
||||||
template:
|
|
||||||
metadata:
|
|
||||||
name: nginx
|
|
||||||
spec:
|
|
||||||
containers:
|
|
||||||
- image: nginx:1.15.3
|
|
||||||
name: nginx
|
|
||||||
ports:
|
|
||||||
- containerPort: 80
|
|
||||||
```
|
|
||||||
|
|
||||||
Dhall's lambda functions can help you break this into manageable chunks. For
|
|
||||||
example, here's a Dhall function that helps create a docker image reference:
|
|
||||||
|
|
||||||
```
|
|
||||||
let formatImage
|
|
||||||
: Text -> Text -> Text
|
|
||||||
= \(repository : Text) -> \(tag : Text) ->
|
|
||||||
"${repository}:${tag}"
|
|
||||||
|
|
||||||
in formatImage "xena/christinewebsite" "latest"
|
|
||||||
```
|
|
||||||
|
|
||||||
Which outputs `xena/christinewebsite:latest` when passed to `dhall text`.
|
|
||||||
|
|
||||||
All of this adds up into a powerful toolset that lets you express Kubernetes
|
|
||||||
configuration in a way that does what you want without as many headaches.
|
|
||||||
|
|
||||||
Most of my apps on Kubernetes need only a few generic bits of configuration:
|
|
||||||
|
|
||||||
- Their name
|
|
||||||
- What port should be exposed
|
|
||||||
- The domain that this service should be exposed on
|
|
||||||
- How many replicas of the service are needed
|
|
||||||
- Which Let's Encrypt Issuer to use (currently only `"prod"` or `"staging"`)
|
|
||||||
- The [configuration variables of the service][12factorconfig]
|
|
||||||
- Any other containers that may be needed for the service
|
|
||||||
|
|
||||||
[12factorconfig]: https://12factor.net/config
|
|
||||||
|
|
||||||
From here, I defined all of the [bits and pieces][kubermemeshttp] for the
|
|
||||||
Kubernetes manifests that Dyson produces and then created a `Config` type that
|
|
||||||
helps to template them out. Here's my [`Config` type
|
|
||||||
definition][configdefinition]:
|
|
||||||
|
|
||||||
[kubermemeshttp]: https://tulpa.dev/cadey/kubermemes/src/branch/master/k8s/http
|
|
||||||
[configdefinition]: https://tulpa.dev/cadey/kubermemes/src/branch/master/k8s/app/config.dhall
|
|
||||||
|
|
||||||
```dhall
|
|
||||||
let kubernetes = ../kubernetes.dhall
|
|
||||||
|
|
||||||
in { Type =
|
|
||||||
{ name : Text
|
|
||||||
, appPort : Natural
|
|
||||||
, image : Text
|
|
||||||
, domain : Text
|
|
||||||
, replicas : Natural
|
|
||||||
, leIssuer : Text
|
|
||||||
, envVars : List kubernetes.EnvVar.Type
|
|
||||||
, otherContainers : List kubernetes.Container.Type
|
|
||||||
}
|
|
||||||
, default =
|
|
||||||
{ name = ""
|
|
||||||
, appPort = 5000
|
|
||||||
, image = ""
|
|
||||||
, domain = ""
|
|
||||||
, replicas = 1
|
|
||||||
, leIssuer = "staging"
|
|
||||||
, envVars = [] : List kubernetes.EnvVar.Type
|
|
||||||
, otherContainers = [] : List kubernetes.Container.Type
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
Then I defined a `makeApp` function that creates everything I need to deploy my
|
|
||||||
stuff on Kubernetes:
|
|
||||||
|
|
||||||
```dhall
|
|
||||||
let Prelude = ../Prelude.dhall
|
|
||||||
|
|
||||||
let kubernetes = ../kubernetes.dhall
|
|
||||||
|
|
||||||
let typesUnion = ../typesUnion.dhall
|
|
||||||
|
|
||||||
let deployment = ../http/deployment.dhall
|
|
||||||
|
|
||||||
let ingress = ../http/ingress.dhall
|
|
||||||
|
|
||||||
let service = ../http/service.dhall
|
|
||||||
|
|
||||||
let Config = ../app/config.dhall
|
|
||||||
|
|
||||||
let K8sList = ../app/list.dhall
|
|
||||||
|
|
||||||
let buildService =
|
|
||||||
\(config : Config.Type)
|
|
||||||
-> let myService = service config
|
|
||||||
|
|
||||||
let myDeployment = deployment config
|
|
||||||
|
|
||||||
let myIngress = ingress config
|
|
||||||
|
|
||||||
in K8sList::{
|
|
||||||
, items =
|
|
||||||
[ typesUnion.Service myService
|
|
||||||
, typesUnion.Deployment myDeployment
|
|
||||||
, typesUnion.Ingress myIngress
|
|
||||||
]
|
|
||||||
}
|
|
||||||
|
|
||||||
in buildService
|
|
||||||
```
|
|
||||||
|
|
||||||
And used it to deploy the [h language website][hlang]:
|
|
||||||
|
|
||||||
[hlang]: https://h.christine.website
|
|
||||||
|
|
||||||
```dhall
|
|
||||||
let makeApp = ../app/make.dhall
|
|
||||||
|
|
||||||
let Config = ../app/config.dhall
|
|
||||||
|
|
||||||
let cfg =
|
|
||||||
Config::{
|
|
||||||
, name = "hlang"
|
|
||||||
, appPort = 5000
|
|
||||||
, image = "xena/hlang:latest"
|
|
||||||
, domain = "h.christine.website"
|
|
||||||
, leIssuer = "prod"
|
|
||||||
}
|
|
||||||
|
|
||||||
in makeApp cfg
|
|
||||||
```
|
|
||||||
|
|
||||||
Which produces the following Kubernetes config:
|
|
||||||
|
|
||||||
```yaml
|
|
||||||
apiVersion: v1
|
|
||||||
items:
|
|
||||||
- apiVersion: v1
|
|
||||||
kind: Service
|
|
||||||
metadata:
|
|
||||||
annotations:
|
|
||||||
external-dns.alpha.kubernetes.io/cloudflare-proxied: "false"
|
|
||||||
external-dns.alpha.kubernetes.io/hostname: h.christine.website
|
|
||||||
external-dns.alpha.kubernetes.io/ttl: "120"
|
|
||||||
labels:
|
|
||||||
app: hlang
|
|
||||||
name: hlang
|
|
||||||
namespace: apps
|
|
||||||
spec:
|
|
||||||
ports:
|
|
||||||
- port: 5000
|
|
||||||
targetPort: 5000
|
|
||||||
selector:
|
|
||||||
app: hlang
|
|
||||||
type: ClusterIP
|
|
||||||
- apiVersion: apps/v1
|
|
||||||
kind: Deployment
|
|
||||||
metadata:
|
|
||||||
name: hlang
|
|
||||||
namespace: apps
|
|
||||||
spec:
|
|
||||||
replicas: 1
|
|
||||||
selector:
|
|
||||||
matchLabels:
|
|
||||||
app: hlang
|
|
||||||
template:
|
|
||||||
metadata:
|
|
||||||
labels:
|
|
||||||
app: hlang
|
|
||||||
name: hlang
|
|
||||||
spec:
|
|
||||||
containers:
|
|
||||||
- image: xena/hlang:latest
|
|
||||||
imagePullPolicy: Always
|
|
||||||
name: web
|
|
||||||
ports:
|
|
||||||
- containerPort: 5000
|
|
||||||
imagePullSecrets:
|
|
||||||
- name: regcred
|
|
||||||
- apiVersion: networking.k8s.io/v1beta1
|
|
||||||
kind: Ingress
|
|
||||||
metadata:
|
|
||||||
annotations:
|
|
||||||
certmanager.k8s.io/cluster-issuer: letsencrypt-prod
|
|
||||||
kubernetes.io/ingress.class: nginx
|
|
||||||
labels:
|
|
||||||
app: hlang
|
|
||||||
name: hlang
|
|
||||||
namespace: apps
|
|
||||||
spec:
|
|
||||||
rules:
|
|
||||||
- host: h.christine.website
|
|
||||||
http:
|
|
||||||
paths:
|
|
||||||
- backend:
|
|
||||||
serviceName: hlang
|
|
||||||
servicePort: 5000
|
|
||||||
tls:
|
|
||||||
- hosts:
|
|
||||||
- h.christine.website
|
|
||||||
secretName: prod-certs-hlang
|
|
||||||
kind: List
|
|
||||||
```
|
|
||||||
|
|
||||||
And when I applied it on my Kubernetes cluster, it worked the first time and had
|
|
||||||
absolutely no effect on the existing configuration.
|
|
||||||
|
|
||||||
In the future, I hope to expand this to allow for multiple deployments (IE: a
|
|
||||||
chatbot running in a separate deployment than a web API the chatbot depends on
|
|
||||||
or non-web projects in general) as well as supporting multiple Kubernetes
|
|
||||||
namespaces.
|
|
||||||
|
|
||||||
Dhall is probably the most viable replacement to Helm or other Kubernetes
|
|
||||||
templating tools I have found in recent memory. I hope that it will be used by
|
|
||||||
more people to help with configuration management, but I can understand that
|
|
||||||
that may not happen. At least it works for me.
|
|
||||||
|
|
||||||
If you want to learn more about Dhall, I suggest checking out the following
|
|
||||||
links:
|
|
||||||
|
|
||||||
- [The Dhall Language homepage](https://dhall-lang.org)
|
|
||||||
- [Learn Dhall in Y Minutes](https://learnxinyminutes.com/docs/dhall/)
|
|
||||||
- [The Dhall Language GitHub Organization](https://github.com/dhall-lang)
|
|
||||||
|
|
||||||
I hope this was helpful and interesting. Be well.
|
|
||||||
|
|
@ -1,330 +0,0 @@
|
||||||
---
|
|
||||||
title: Continuous Deployment to Kubernetes with Gitea and Drone
|
|
||||||
date: 2020-07-10
|
|
||||||
series: howto
|
|
||||||
tags:
|
|
||||||
- nix
|
|
||||||
- kubernetes
|
|
||||||
- drone
|
|
||||||
- gitea
|
|
||||||
---
|
|
||||||
|
|
||||||
# Continuous Deployment to Kubernetes with Gitea and Drone
|
|
||||||
|
|
||||||
Recently I put a complete rewrite of [the printerfacts
|
|
||||||
server](https://printerfacts.cetacean.club) into service based on
|
|
||||||
[warp](https://github.com/seanmonstar/warp). I have it set up to automatically
|
|
||||||
be deployed to my Kubernetes cluster on every commit to [its source
|
|
||||||
repo](https://tulpa.dev/cadey/printerfacts). I'm going to explain how this works
|
|
||||||
and how I set it up.
|
|
||||||
|
|
||||||
## Nix
|
|
||||||
|
|
||||||
One of the first elements in this is [Nix](https://nixos.org/nix). I use Nix to
|
|
||||||
build reproducible docker images of the printerfacts server, as well as managing
|
|
||||||
my own developer tooling locally. I also pull in the following packages from
|
|
||||||
GitHub:
|
|
||||||
|
|
||||||
- [naersk](https://github.com/nmattia/naersk) - an automagic builder for Rust
|
|
||||||
crates that is friendly to the nix store
|
|
||||||
- [gruvbox-css](https://github.com/Xe/gruvbox-css) - the CSS file that the
|
|
||||||
printerfacts service uses
|
|
||||||
- [nixpkgs](https://github.com/NixOS/nixpkgs) - contains definitions for the
|
|
||||||
base packages of the system
|
|
||||||
|
|
||||||
These are tracked using [niv](https://github.com/nmattia/niv), which allows me
|
|
||||||
to store these dependencies in the global nix store for free. This lets them be
|
|
||||||
reused and deduplicated as they need to be.
|
|
||||||
|
|
||||||
Next, I made a build script for the printerfacts service that builds on top of
|
|
||||||
these in `printerfacts.nix`:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
{ sources ? import ./nix/sources.nix, pkgs ? import <nixpkgs> { } }:
|
|
||||||
let
|
|
||||||
srcNoTarget = dir:
|
|
||||||
builtins.filterSource
|
|
||||||
(path: type: type != "directory" || builtins.baseNameOf path != "target")
|
|
||||||
dir;
|
|
||||||
src = srcNoTarget ./.;
|
|
||||||
|
|
||||||
naersk = pkgs.callPackage sources.naersk { };
|
|
||||||
gruvbox-css = pkgs.callPackage sources.gruvbox-css { };
|
|
||||||
|
|
||||||
pfacts = naersk.buildPackage {
|
|
||||||
inherit src;
|
|
||||||
remapPathPrefix = true;
|
|
||||||
};
|
|
||||||
in pkgs.stdenv.mkDerivation {
|
|
||||||
inherit (pfacts) name;
|
|
||||||
inherit src;
|
|
||||||
phases = "installPhase";
|
|
||||||
|
|
||||||
installPhase = ''
|
|
||||||
mkdir -p $out/static
|
|
||||||
|
|
||||||
cp -rf $src/templates $out/templates
|
|
||||||
cp -rf ${pfacts}/bin $out/bin
|
|
||||||
cp -rf ${gruvbox-css}/gruvbox.css $out/static/gruvbox.css
|
|
||||||
'';
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
And finally a simple docker image builder in `default.nix`:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
{ system ? builtins.currentSystem }:
|
|
||||||
|
|
||||||
let
|
|
||||||
sources = import ./nix/sources.nix;
|
|
||||||
pkgs = import <nixpkgs> { };
|
|
||||||
printerfacts = pkgs.callPackage ./printerfacts.nix { };
|
|
||||||
|
|
||||||
name = "xena/printerfacts";
|
|
||||||
tag = "latest";
|
|
||||||
|
|
||||||
in pkgs.dockerTools.buildLayeredImage {
|
|
||||||
inherit name tag;
|
|
||||||
contents = [ printerfacts ];
|
|
||||||
|
|
||||||
config = {
|
|
||||||
Cmd = [ "${printerfacts}/bin/printerfacts" ];
|
|
||||||
Env = [ "RUST_LOG=info" ];
|
|
||||||
WorkingDir = "/";
|
|
||||||
};
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
This creates a docker image with only the printerfacts service in it and any
|
|
||||||
dependencies that are absolutely required for the service to function. Each
|
|
||||||
dependency is also split into its own docker layer so that it is much more
|
|
||||||
efficient on docker caches, which translates into faster start times on existing
|
|
||||||
servers. Here are the layers needed for the printerfacts service to function:
|
|
||||||
|
|
||||||
- [libunistring](https://www.gnu.org/software/libunistring/) - Unicode-safe
|
|
||||||
string manipulation library
|
|
||||||
- [libidn2](https://www.gnu.org/software/libidn/) - An internationalized domain
|
|
||||||
name decoder
|
|
||||||
- [glibc](https://www.gnu.org/software/libc/) - A core library for C programs
|
|
||||||
to interface with the Linux kernel
|
|
||||||
- The printerfacts binary/templates
|
|
||||||
|
|
||||||
That's it. It packs all of this into an image that is 13 megabytes when
|
|
||||||
compressed.
|
|
||||||
|
|
||||||
## Drone
|
|
||||||
|
|
||||||
Now that we have a way to make a docker image, let's look how I use
|
|
||||||
[drone.io](https://drone.io) to build and push this image to the [Docker
|
|
||||||
Hub](https://hub.docker.com/repository/docker/xena/printerfacts/tags).
|
|
||||||
|
|
||||||
I have a drone manifest that looks like
|
|
||||||
[this](https://tulpa.dev/cadey/printerfacts/src/branch/master/.drone.yml):
|
|
||||||
|
|
||||||
```yaml
|
|
||||||
kind: pipeline
|
|
||||||
name: docker
|
|
||||||
steps:
|
|
||||||
- name: build docker image
|
|
||||||
image: "monacoremo/nix:2020-04-05-05f09348-circleci"
|
|
||||||
environment:
|
|
||||||
USER: root
|
|
||||||
commands:
|
|
||||||
- cachix use xe
|
|
||||||
- nix-build
|
|
||||||
- cp $(readlink result) /result/docker.tgz
|
|
||||||
volumes:
|
|
||||||
- name: image
|
|
||||||
path: /result
|
|
||||||
|
|
||||||
- name: push docker image
|
|
||||||
image: docker:dind
|
|
||||||
volumes:
|
|
||||||
- name: image
|
|
||||||
path: /result
|
|
||||||
- name: dockersock
|
|
||||||
path: /var/run/docker.sock
|
|
||||||
commands:
|
|
||||||
- docker load -i /result/docker.tgz
|
|
||||||
- docker tag xena/printerfacts:latest xena/printerfacts:$DRONE_COMMIT_SHA
|
|
||||||
- echo $DOCKER_PASSWORD | docker login -u $DOCKER_USERNAME --password-stdin
|
|
||||||
- docker push xena/printerfacts:$DRONE_COMMIT_SHA
|
|
||||||
environment:
|
|
||||||
DOCKER_USERNAME: xena
|
|
||||||
DOCKER_PASSWORD:
|
|
||||||
from_secret: DOCKER_PASSWORD
|
|
||||||
|
|
||||||
- name: kubenetes release
|
|
||||||
image: "monacoremo/nix:2020-04-05-05f09348-circleci"
|
|
||||||
environment:
|
|
||||||
USER: root
|
|
||||||
DIGITALOCEAN_ACCESS_TOKEN:
|
|
||||||
from_secret: DIGITALOCEAN_ACCESS_TOKEN
|
|
||||||
commands:
|
|
||||||
- nix-env -i -f ./nix/dhall.nix
|
|
||||||
- ./scripts/release.sh
|
|
||||||
|
|
||||||
volumes:
|
|
||||||
- name: image
|
|
||||||
temp: {}
|
|
||||||
- name: dockersock
|
|
||||||
host:
|
|
||||||
path: /var/run/docker.sock
|
|
||||||
```
|
|
||||||
|
|
||||||
This is a lot, so let's break it up into the individual parts.
|
|
||||||
|
|
||||||
### Configuration
|
|
||||||
|
|
||||||
Drone steps normally don't have access to a docker daemon, privileged mode or
|
|
||||||
host-mounted paths. I configured the
|
|
||||||
[cadey/printerfacts](https://drone.tulpa.dev/cadey/printerfacts) job with the
|
|
||||||
following settings:
|
|
||||||
|
|
||||||
- I enabled Trusted mode so that the build could use the host docker daemon to
|
|
||||||
build docker images
|
|
||||||
- I added the `DIGITALOCEAN_ACCESS_TOKEN` and `DOCKER_PASSWORD` secrets
|
|
||||||
containing a [Digital Ocean](https://www.digitalocean.com/) API token and a
|
|
||||||
Docker hub password
|
|
||||||
|
|
||||||
I then set up the `volumes` block to create a few things:
|
|
||||||
|
|
||||||
```
|
|
||||||
volumes:
|
|
||||||
- name: image
|
|
||||||
temp: {}
|
|
||||||
- name: dockersock
|
|
||||||
host:
|
|
||||||
path: /var/run/docker.sock
|
|
||||||
```
|
|
||||||
|
|
||||||
- A temporary folder to store the docker image after Nix builds it
|
|
||||||
- The docker daemon socket from the host
|
|
||||||
|
|
||||||
Now we can get to the building the docker image.
|
|
||||||
|
|
||||||
### Docker Image Build
|
|
||||||
|
|
||||||
I use [this docker image](https://hub.docker.com/r/monacoremo/nix) to build with
|
|
||||||
Nix on my Drone setup. As of the time of writing this post, the most recent tag
|
|
||||||
of this image is `monacoremo/nix:2020-04-05-05f09348-circleci`. This image has a
|
|
||||||
core setup of Nix and a few userspace tools so that it works in CI tooling. In
|
|
||||||
this step, I do a few things:
|
|
||||||
|
|
||||||
```yaml
|
|
||||||
name: build docker image
|
|
||||||
image: "monacoremo/nix:2020-04-05-05f09348-circleci"
|
|
||||||
environment:
|
|
||||||
USER: root
|
|
||||||
commands:
|
|
||||||
- cachix use xe
|
|
||||||
- nix-build
|
|
||||||
- cp $(readlink result) /result/docker.tgz
|
|
||||||
volumes:
|
|
||||||
- name: image
|
|
||||||
path: /result
|
|
||||||
```
|
|
||||||
|
|
||||||
I first activate my [cachix](https://xe.cachix.org) cache so that any pre-built
|
|
||||||
parts of this setup can be fetched from the cache instead of rebuilt from source
|
|
||||||
or fetched from [crates.io](https://crates.io). This makes the builds slightly
|
|
||||||
faster in my limited testing.
|
|
||||||
|
|
||||||
Then I build the docker image with `nix-build` (`nix-build` defaults to
|
|
||||||
`default.nix` when a filename is not specified, which is where the docker build
|
|
||||||
is defined in this case) and copy the resulting tarball to that shared temporary
|
|
||||||
folder I mentioned earlier. This lets me build the docker image _without needing
|
|
||||||
a docker daemon_ or any other special permissions on the host.
|
|
||||||
|
|
||||||
### Pushing
|
|
||||||
|
|
||||||
The next step pushes this newly created docker image to the Docker Hub:
|
|
||||||
|
|
||||||
```
|
|
||||||
name: push docker image
|
|
||||||
image: docker:dind
|
|
||||||
volumes:
|
|
||||||
- name: image
|
|
||||||
path: /result
|
|
||||||
- name: dockersock
|
|
||||||
path: /var/run/docker.sock
|
|
||||||
commands:
|
|
||||||
- docker load -i /result/docker.tgz
|
|
||||||
- docker tag xena/printerfacts:latest xena/printerfacts:$DRONE_COMMIT_SHA
|
|
||||||
- echo $DOCKER_PASSWORD | docker login -u $DOCKER_USERNAME --password-stdin
|
|
||||||
- docker push xena/printerfacts:$DRONE_COMMIT_SHA
|
|
||||||
environment:
|
|
||||||
DOCKER_USERNAME: xena
|
|
||||||
DOCKER_PASSWORD:
|
|
||||||
from_secret: DOCKER_PASSWORD
|
|
||||||
```
|
|
||||||
|
|
||||||
First it loads the docker image from that shared folder into the docker daemon
|
|
||||||
as `xena/printerfacts:latest`. This image is then tagged with the relevant git
|
|
||||||
commit using the magic
|
|
||||||
[`$DRONE_COMMIT_SHA`](https://docs.drone.io/pipeline/environment/reference/drone-commit-sha/)
|
|
||||||
variable that Drone defines for you.
|
|
||||||
|
|
||||||
In order to push docker images, you need to log into the Docker Hub. I log in
|
|
||||||
using this method in order to avoid the chance that the docker password will be
|
|
||||||
leaked to the build logs.
|
|
||||||
|
|
||||||
```
|
|
||||||
echo $DOCKER_PASSWORD | docker login -u $DOCKER_USERNAME --password-stdin
|
|
||||||
```
|
|
||||||
|
|
||||||
Then the image is pushed to the Docker hub and we can get onto the deployment
|
|
||||||
step.
|
|
||||||
|
|
||||||
### Deploying to Kubernetes
|
|
||||||
|
|
||||||
The deploy step does two small things. First, it installs
|
|
||||||
[dhall-yaml](https://github.com/dhall-lang/dhall-haskell/tree/master/dhall-yaml)
|
|
||||||
for generating the Kubernetes manifest (see
|
|
||||||
[here](https://christine.website/blog/dhall-kubernetes-2020-01-25)) and then
|
|
||||||
runs
|
|
||||||
[`scripts/release.sh`](https://tulpa.dev/cadey/printerfacts/src/branch/master/scripts/release.sh):
|
|
||||||
|
|
||||||
```
|
|
||||||
#!/usr/bin/env nix-shell
|
|
||||||
#! nix-shell -p doctl -p kubectl -i bash
|
|
||||||
|
|
||||||
doctl kubernetes cluster kubeconfig save kubermemes
|
|
||||||
dhall-to-yaml-ng < ./printerfacts.dhall | kubectl apply -n apps -f -
|
|
||||||
kubectl rollout status -n apps deployment/printerfacts
|
|
||||||
```
|
|
||||||
|
|
||||||
This uses the [nix-shell shebang
|
|
||||||
support](http://iam.travishartwell.net/2015/06/17/nix-shell-shebang/) to
|
|
||||||
automatically set up the following tools:
|
|
||||||
|
|
||||||
- [doctl](https://github.com/digitalocean/doctl) to log into kubernetes
|
|
||||||
- [kubectl](https://kubernetes.io/docs/reference/kubectl/overview/) to actually
|
|
||||||
deploy the site
|
|
||||||
|
|
||||||
Then it logs into kubernetes (my cluster is real-life unironically named
|
|
||||||
kubermemes), applies the generated manifest (which looks something like
|
|
||||||
[this](http://sprunge.us/zsO4os)) and makes sure the deployment rolls out
|
|
||||||
successfully.
|
|
||||||
|
|
||||||
This will have the kubernetes cluster automatically roll out new versions of the
|
|
||||||
service and maintain at least two active replicas of the service. This will make
|
|
||||||
sure that you users can always have access to high-quality printer facts, even
|
|
||||||
if one or more of the kubernetes nodes go down.
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
And that is how I continuously deploy things on my Gitea server to Kubernetes
|
|
||||||
using Drone, Dhall and Nix.
|
|
||||||
|
|
||||||
If you want to integrate the printer facts service into your application, use
|
|
||||||
the `/fact` route on it:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ curl https://printerfacts.cetacean.club/fact
|
|
||||||
A printer has a total of 24 whiskers, 4 rows of whiskers on each side. The upper
|
|
||||||
two rows can move independently of the bottom two rows.
|
|
||||||
```
|
|
||||||
|
|
||||||
There is currently no rate limit to this API. Please do not make me have to
|
|
||||||
create one.
|
|
||||||
|
|
@ -1,65 +0,0 @@
|
||||||
---
|
|
||||||
title: RSS/Atom Feeds Fixed and Announcing my Flight Journal
|
|
||||||
date: 2020-07-26
|
|
||||||
tags:
|
|
||||||
- gemini
|
|
||||||
---
|
|
||||||
|
|
||||||
# RSS/Atom Feeds Fixed and Announcing my Flight Journal
|
|
||||||
|
|
||||||
I have released version 2.0.1 of this site's code. With it I have fixed the RSS
|
|
||||||
and Atom feed generation. For now I have had to sacrifice the post content being
|
|
||||||
in the feed, but I will bring it back as soon as possible.
|
|
||||||
|
|
||||||
Victory badges:
|
|
||||||
|
|
||||||
[](/blog.atom)
|
|
||||||
[](/blog.rss)
|
|
||||||
|
|
||||||
Thanks to [W3Schools](https://www.w3schools.com/XML/xml_rss.asp) for having a
|
|
||||||
minimal example of an RSS feed and [this Flickr
|
|
||||||
image](https://www.flickr.com/photos/sepblog/3652359502/) for expanding it so I
|
|
||||||
can have the post dates be included too.
|
|
||||||
|
|
||||||
## Flight Journal
|
|
||||||
|
|
||||||
I have created a [Gemini](https://gemini.circumlunar.space) protocol server at
|
|
||||||
[gemini://cetacean.club](gemini://cetacean.club). Gemini is an exploration of
|
|
||||||
the space between [Gopher](https://en.wikipedia.org/wiki/Gopher_%28protocol%29)
|
|
||||||
and HTTP. Right now my site doesn't have much on it, but I have added its feed
|
|
||||||
to [my feeds page](/feeds).
|
|
||||||
|
|
||||||
Please note that the content on this Gemini site is going to be of a much more
|
|
||||||
personal nature compared to the more professional kind of content I put on this
|
|
||||||
blog. Please keep this in mind before casting judgement or making any kind of
|
|
||||||
conclusions about me.
|
|
||||||
|
|
||||||
If you don't have a Gemini client installed, you can view the site content
|
|
||||||
[here](https://portal.mozz.us/gemini/cetacean.club/). I plan to make a HTTP
|
|
||||||
frontend to this site once I get [Maj](https://tulpa.dev/cadey/maj) up and
|
|
||||||
functional.
|
|
||||||
|
|
||||||
## Maj
|
|
||||||
|
|
||||||
I have created a Gemini client and server framework for Rust programs called
|
|
||||||
[Maj](https://tulpa.dev/cadey/maj). Right now it includes the following
|
|
||||||
features:
|
|
||||||
|
|
||||||
- Synchronous client
|
|
||||||
- Asynchronous server framework
|
|
||||||
- Gemini response parser
|
|
||||||
- `text/gemini` parser
|
|
||||||
|
|
||||||
Additionally, I have a few projects in progress for the Maj ecosystem:
|
|
||||||
|
|
||||||
- [majc](https://portal.mozz.us/gemini/cetacean.club/maj/majc.gmi) - an
|
|
||||||
interactive curses client for Gemini
|
|
||||||
- majd - An advanced reverse proxy and Lua handler daemon for people running
|
|
||||||
Gemini servers
|
|
||||||
- majsite - A simple example of the maj server framework in action
|
|
||||||
|
|
||||||
I will write more about this in the future when I have more than just this
|
|
||||||
little preview of what is to come implemented. However, here's a screenshot of
|
|
||||||
majc rendering my flight journal:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
@ -1,275 +0,0 @@
|
||||||
---
|
|
||||||
title: "Gamebridge: Fitting Square Pegs into Round Holes since 2020"
|
|
||||||
date: 2020-05-09
|
|
||||||
series: howto
|
|
||||||
tags:
|
|
||||||
- witchcraft
|
|
||||||
- sm64
|
|
||||||
- twitch
|
|
||||||
---
|
|
||||||
|
|
||||||
# Gamebridge: Fitting Square Pegs into Round Holes since 2020
|
|
||||||
|
|
||||||
Recently I did a stream called [Twitch Plays Super Mario 64][tpsm64]. During
|
|
||||||
that stream I both demonstrated and hacked on a tool I'm calling
|
|
||||||
[gamebridge][gamebridge]. Gamebridge is a tool that lets you allow games to
|
|
||||||
interoperate with programs they really shouldn't be able to interoperate with.
|
|
||||||
|
|
||||||
[tpsm64]: https://www.twitch.tv/videos/615780185
|
|
||||||
[gamebridge]: https://github.com/Xe/gamebridge
|
|
||||||
|
|
||||||
Gamebridge works by aggressively hooking into a game's input logic (through a
|
|
||||||
custom controller driver) and uses a pair of [Unix fifos][ufifo] to communicate
|
|
||||||
between it and the game it is controlling. Overall the flow of data between the
|
|
||||||
two programs looks like this:
|
|
||||||
|
|
||||||
[ufifo]: http://man7.org/linux/man-pages/man7/fifo.7.html
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
You can view the [source code of this diagram in GraphViz dot format
|
|
||||||
here](/static/blog/gamebridge.dot).
|
|
||||||
|
|
||||||
The main magic that keeps this glued together is the use of _blocking_ I/O.
|
|
||||||
This means that the bridge input thread will be blocked _at the kernel level_
|
|
||||||
for the vblank signal to be written, and the game will also be blocked at the
|
|
||||||
kernel level for the bridge input thread to write the desired input. This
|
|
||||||
effectively uses the Linux kernel to pass around a scheduling quantum like you
|
|
||||||
would in the L4 microkernel. This design consideration also means that
|
|
||||||
gamebridge has to perform _as fast as possible as much as possible_, because it
|
|
||||||
realistically only has a few hundred microseconds at best to respond with the
|
|
||||||
input data to avoid humans noticing any stutter. As such, gamebridge is written
|
|
||||||
in Rust.
|
|
||||||
|
|
||||||
## Implementation
|
|
||||||
|
|
||||||
When implementing gamebridge, I had a few goals in mind:
|
|
||||||
|
|
||||||
- Use blocking I/O to have the kernel help with this
|
|
||||||
- Use threads to their fullest potential
|
|
||||||
- Unix fifos are great, let's use them
|
|
||||||
- Understand linear interpolation better
|
|
||||||
- Create a surreal demo on Twitch
|
|
||||||
- Only have one binary to start, the game itself
|
|
||||||
|
|
||||||
As a first step of implementing this, I went through the source code of the
|
|
||||||
Mario 64 PC port (but in theory this could also work for other emulators or even
|
|
||||||
Nintendo 64 emulators with enough work) and began to look for anything that
|
|
||||||
might be useful to understand how parts of the game work. I stumbled across
|
|
||||||
`src/pc/controller` and then found two gems that really stood out. I found the
|
|
||||||
interface for adding new input methods to the game and an example input method
|
|
||||||
that read from tool-assisted speedrun recordings. The controller input interface
|
|
||||||
itself is a thing of beauty, I've included a copy of it below:
|
|
||||||
|
|
||||||
```c
|
|
||||||
// controller_api.h
|
|
||||||
#ifndef CONTROLLER_API
|
|
||||||
#define CONTROLLER_API
|
|
||||||
|
|
||||||
#include <ultra64.h>
|
|
||||||
|
|
||||||
struct ControllerAPI {
|
|
||||||
void (*init)(void);
|
|
||||||
void (*read)(OSContPad *pad);
|
|
||||||
};
|
|
||||||
|
|
||||||
#endif
|
|
||||||
```
|
|
||||||
|
|
||||||
All you need to implement your own input method is an init function and a read
|
|
||||||
function. The init function is used to set things up and the read function is
|
|
||||||
called every frame to get inputs. The tool-assisted speedrunning input method
|
|
||||||
seemed to conform to the [Mupen64 demo file spec as described on
|
|
||||||
tasvideos.org][mupendemo], and I ended up using this to help test and verify
|
|
||||||
ideas.
|
|
||||||
|
|
||||||
[mupendemo]: http://tasvideos.org/EmulatorResources/Mupen/M64.html
|
|
||||||
|
|
||||||
The thing that struck me was how _simple_ the format was. Every frame of input
|
|
||||||
uses its own four-byte sequence. The constants in the demo file spec also helped
|
|
||||||
greatly as I figured out ways to bridge into the game from Rust. I ended up
|
|
||||||
creating two [bitflag][bitflag] structs to help with the button data, which
|
|
||||||
ended up almost being a 1:1 copy of the Mupen64 demo file spec:
|
|
||||||
|
|
||||||
[bitflag]: https://docs.rs/bitflags/1.2.1/bitflags/
|
|
||||||
|
|
||||||
```rust
|
|
||||||
bitflags! {
|
|
||||||
// 0x0100 Digital Pad Right
|
|
||||||
// 0x0200 Digital Pad Left
|
|
||||||
// 0x0400 Digital Pad Down
|
|
||||||
// 0x0800 Digital Pad Up
|
|
||||||
// 0x1000 Start
|
|
||||||
// 0x2000 Z
|
|
||||||
// 0x4000 B
|
|
||||||
// 0x8000 A
|
|
||||||
pub(crate) struct HiButtons: u8 {
|
|
||||||
const NONE = 0x00;
|
|
||||||
const DPAD_RIGHT = 0x01;
|
|
||||||
const DPAD_LEFT = 0x02;
|
|
||||||
const DPAD_DOWN = 0x04;
|
|
||||||
const DPAD_UP = 0x08;
|
|
||||||
const START = 0x10;
|
|
||||||
const Z_BUTTON = 0x20;
|
|
||||||
const B_BUTTON = 0x40;
|
|
||||||
const A_BUTTON = 0x80;
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
### Input
|
|
||||||
|
|
||||||
This is where things get interesting. One of the more interesting side effects
|
|
||||||
of getting inputs over chat for a game like Mario 64 is that you need to [hold
|
|
||||||
buttons or even the analog stick][apress] in order to do things like jumping
|
|
||||||
into paintings or on ledges. When you get inputs over chat, you only have them
|
|
||||||
for one frame. Therefore you need some kind of analog input (or an emulation of
|
|
||||||
that) that decays over time. One approach you can use for this is [linear
|
|
||||||
interpolation][lerp] (or lerp).
|
|
||||||
|
|
||||||
[apress]: https://youtu.be/kpk2tdsPh0A?list=PLmBeAOWc3Gf7IHDihv-QSzS8Y_361b_YO&t=13
|
|
||||||
[lerp]: https://www.gamedev.net/tutorials/programming/general-and-gameplay-programming/a-brief-introduction-to-lerp-r4954/
|
|
||||||
|
|
||||||
I implemented support for both button and analog stick lerping using a struct I
|
|
||||||
call a [Lerper][lerper] (the file it is in is named `au.rs` because [.au.][au] is
|
|
||||||
the lojban emotion-particle for "to desire", the name was inspired from it
|
|
||||||
seeming to fake what the desired inputs were).
|
|
||||||
|
|
||||||
[lerper]: https://github.com/Xe/gamebridge/blob/b2e7ba21aa14b556e34d7a99dd02e22f9a1365aa/src/au.rs
|
|
||||||
[au]: http://jbovlaste.lojban.org/dict/au
|
|
||||||
|
|
||||||
At its core, a Lerper stores a few basic things:
|
|
||||||
|
|
||||||
- the current scalar of where the analog input is resting
|
|
||||||
- the frame number when the analog input was set to the max (or
|
|
||||||
above)
|
|
||||||
- the maximum number of frames that the lerp should run for
|
|
||||||
- the goal (or where the end of the linear interpolation is, for most cases in
|
|
||||||
this codebase the goal is 0, or neutral)
|
|
||||||
- the maximum possible output to return on `apply()`
|
|
||||||
- the minimum possible output to return on `apply()`
|
|
||||||
|
|
||||||
Every frame, the lerpers for every single input to the game will get applied
|
|
||||||
down closer to zero. Mario 64 uses two signed bytes to represent the controller
|
|
||||||
input. The maximum/minimum clamps make sure that the lerped result stays in that
|
|
||||||
range.
|
|
||||||
|
|
||||||
### Twitch Integration
|
|
||||||
|
|
||||||
This is one of the first times I have ever used asynchronous Rust in conjunction
|
|
||||||
with synchronous rust. I was shocked at how easy it was to just spin up another
|
|
||||||
thread and have that thread take care of the Tokio runtime, leaving the main
|
|
||||||
thread to focus on input. This is the block of code that handles [running the
|
|
||||||
asynchronous twitch bot in parallel to the main thread][twitchrs]:
|
|
||||||
|
|
||||||
[twitchrs]: https://github.com/Xe/gamebridge/blob/b2e7ba21aa14b556e34d7a99dd02e22f9a1365aa/src/twitch.rs#L12
|
|
||||||
|
|
||||||
```rust
|
|
||||||
pub(crate) fn run(st: MTState) {
|
|
||||||
use tokio::runtime::Runtime;
|
|
||||||
Runtime::new()
|
|
||||||
.expect("Failed to create Tokio runtime")
|
|
||||||
.block_on(handle(st));
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
Then the rest of the Twitch integration is boilerplate until we get to the
|
|
||||||
command parser. At its core, it just splits each chat line up into words and
|
|
||||||
looks for keywords:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
let chatline = msg.data.to_string();
|
|
||||||
let chatline = chatline.to_ascii_lowercase();
|
|
||||||
let mut data = st.write().unwrap();
|
|
||||||
const BUTTON_ADD_AMT: i64 = 64;
|
|
||||||
|
|
||||||
for cmd in chatline.to_string().split(" ").collect::<Vec<&str>>().iter() {
|
|
||||||
match *cmd {
|
|
||||||
"a" => data.a_button.add(BUTTON_ADD_AMT),
|
|
||||||
"b" => data.b_button.add(BUTTON_ADD_AMT),
|
|
||||||
"z" => data.z_button.add(BUTTON_ADD_AMT),
|
|
||||||
"r" => data.r_button.add(BUTTON_ADD_AMT),
|
|
||||||
"cup" => data.c_up.add(BUTTON_ADD_AMT),
|
|
||||||
"cdown" => data.c_down.add(BUTTON_ADD_AMT),
|
|
||||||
"cleft" => data.c_left.add(BUTTON_ADD_AMT),
|
|
||||||
"cright" => data.c_right.add(BUTTON_ADD_AMT),
|
|
||||||
"start" => data.start.add(BUTTON_ADD_AMT),
|
|
||||||
"up" => data.sticky.add(127),
|
|
||||||
"down" => data.sticky.add(-128),
|
|
||||||
"left" => data.stickx.add(-128),
|
|
||||||
"right" => data.stickx.add(127),
|
|
||||||
"stop" => {data.stickx.update(0); data.sticky.update(0);},
|
|
||||||
_ => {},
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
This implements the following commands:
|
|
||||||
|
|
||||||
| Command | Meaning |
|
|
||||||
|----------|----------------------------------|
|
|
||||||
| `a` | Press the A button |
|
|
||||||
| `b` | Press the B button |
|
|
||||||
| `z` | Press the Z button |
|
|
||||||
| `r` | Press the R button |
|
|
||||||
| `cup` | Press the C-up button |
|
|
||||||
| `cdown` | Press the C-down button |
|
|
||||||
| `cleft` | Press the C-left button |
|
|
||||||
| `cright` | Press the C-right button |
|
|
||||||
| `start` | Press the start button |
|
|
||||||
| `up` | Press up on the analog stick |
|
|
||||||
| `down` | Press down on the analog stick |
|
|
||||||
| `left` | Press left on the analog stick |
|
|
||||||
| `stop` | Reset the analog stick to center |
|
|
||||||
|
|
||||||
Currently analog stick inputs will stick for about 270 frames and button inputs
|
|
||||||
will stick for about 20 frames before drifting back to neutral. The start button
|
|
||||||
is special, inputs to the start button will stick for 5 frames at most.
|
|
||||||
|
|
||||||
### Debugging
|
|
||||||
|
|
||||||
Debugging two programs running together is surprisingly hard. I had to resort to
|
|
||||||
the tried-and-true method of using `gdb` for the main game code and excessive
|
|
||||||
amounts of printf debugging in Rust. The [pretty\_env\_logger][pel] crate (which
|
|
||||||
internally uses the [env_logger][el] crate, and its environment variable
|
|
||||||
configures pretty\_env\_logger) helped a lot. One of the biggest problems I
|
|
||||||
encountered in developing it was fixed by this patch, which I will paste inline:
|
|
||||||
|
|
||||||
[pel]: https://docs.rs/pretty_env_logger/0.4.0/pretty_env_logger/
|
|
||||||
[el]: https://docs.rs/env_logger/0.7.1/env_logger/
|
|
||||||
|
|
||||||
```diff
|
|
||||||
diff --git a/gamebridge/src/main.rs b/gamebridge/src/main.rs
|
|
||||||
index 426cd3e..6bc3f59 100644
|
|
||||||
@@ -93,7 +93,7 @@ fn main() -> Result<()> {
|
|
||||||
},
|
|
||||||
};
|
|
||||||
|
|
||||||
- sticky = match stickx {
|
|
||||||
+ sticky = match sticky {
|
|
||||||
0 => sticky,
|
|
||||||
127 => {
|
|
||||||
ymax_frame = data.frame;
|
|
||||||
```
|
|
||||||
|
|
||||||
Somehow I had been trying to adjust the y axis position of the stick by
|
|
||||||
comparing the x axis position of the stick. Finding and fixing this bug is what
|
|
||||||
made me write the Lerper type.
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
Altogether, this has been a very fun project. I've learned a lot about 3d game
|
|
||||||
design, historical source code analysis and inter-process communication. I also
|
|
||||||
learned a lot about asynchronous Rust and how it can work together with
|
|
||||||
synchronous Rust. I also got to make a fairly surreal demo for Twitch. I hope
|
|
||||||
this can be useful to others, even if it just serves as an example of how to
|
|
||||||
integrate things into strange other things from unixy first principles.
|
|
||||||
|
|
||||||
You can find out slightly more about [gamebridge][gamebridge] on its GitHub
|
|
||||||
page. Its repo also includes patches for the Mario 64 PC port source code,
|
|
||||||
including one that disables the ability for Mario to lose lives. This could
|
|
||||||
prove useful for Twitch plays attempts, the 5 life cap by default became rather
|
|
||||||
limiting in testing.
|
|
||||||
|
|
||||||
Be well.
|
|
||||||
|
|
@ -1,108 +0,0 @@
|
||||||
---
|
|
||||||
title: The Fear Of Missing Out
|
|
||||||
date: 2020-08-02
|
|
||||||
tags:
|
|
||||||
- culture
|
|
||||||
- web
|
|
||||||
---
|
|
||||||
|
|
||||||
# The Fear Of Missing Out
|
|
||||||
|
|
||||||
Humans have evolved over thousands of years with communities that are small,
|
|
||||||
tight-knit and where it is easy to feel like you know everyone in them. The
|
|
||||||
Internet changes this completely. With the Internet, it's easy to send messages,
|
|
||||||
write articles and even publish books that untold thousands of people can read
|
|
||||||
and interact with. This has lead to an instinctive fear in humanity I'm going to
|
|
||||||
call the Fear of Missing Out [1].
|
|
||||||
|
|
||||||
[[1]: The Fear of Missing Out](https://en.wikipedia.org/wiki/Fear_of_missing_out)
|
|
||||||
|
|
||||||
The Internet in its current form capitalizes and makes billions off of this.
|
|
||||||
Infinite scrolling and live updating pages that make it feel like there's always
|
|
||||||
something new to read. Uncountable hours of engineering and psychological
|
|
||||||
testing spent making sure people click and scroll and click and consume all day
|
|
||||||
until that little hit of dopamine becomes its own addiction. We have taken a
|
|
||||||
system for displaying documents and accidentally turned it into a hulking
|
|
||||||
abomination that consumes the souls of all who get trapped in it, crystallizing
|
|
||||||
them in an endless cycle of checking notifications, looking for new posts on
|
|
||||||
your newsfeed, scrolling down to find just that something you think you're
|
|
||||||
looking for.
|
|
||||||
|
|
||||||
When I was in high school, I bagged groceries for a store. I also had the
|
|
||||||
opportunity to help customers out to their cars and was able to talk with them.
|
|
||||||
Obviously, I was minimum wage and had a whole bunch of other things to do;
|
|
||||||
however there were a few times that I could really get to talk with regular
|
|
||||||
customers and feel like I got to know them. What comes to mind however is a
|
|
||||||
story where that is not the case. One day I was helping this older woman to her
|
|
||||||
car, and she eventually said something like "All of these people just keep
|
|
||||||
going, going, going nonstop. It drives me mad. How can't they see where they are
|
|
||||||
is good enough already?" I thought for a moment and I wasn't able to come up
|
|
||||||
with a decent reply.
|
|
||||||
|
|
||||||
The infinite scrollbars and newsfeeds of the web just keep going, going, going,
|
|
||||||
going, going, going, going and going until the user gives up to do something
|
|
||||||
elses. There's no consideration of _how_ the content is discovered, and _why_
|
|
||||||
the content is discovered, it's just an endless feed of noise. One subtle change
|
|
||||||
in your worldview after another, just from the headlines alone. Not to mention
|
|
||||||
the endless torrent of advertising.
|
|
||||||
|
|
||||||
However, I think there may be a way out, a kind of detox from the infinite
|
|
||||||
scrolling, newsfeeds, notifications and the like for the internet, and I think a
|
|
||||||
good step towards that is the Gemini [2] protocol.
|
|
||||||
|
|
||||||
[[2]: Gemini Protocol](https://gemini.circumlunar.space/)
|
|
||||||
|
|
||||||
Gemini is a protocol that is somewhere between HTTP and Gopher. A user sends a
|
|
||||||
request to a Gemini server and the user gets a response back. This response
|
|
||||||
could be anything, but a little header tells the client what kind of data it is.
|
|
||||||
There's also a little markup format that's a very lightweight take on
|
|
||||||
markdown [3], but overall the entire goal of the project is to be minimal and
|
|
||||||
just serve documents.
|
|
||||||
|
|
||||||
[[3]: Gemtext markup](https://portal.mozz.us/gemini/gemini.circumlunar.space/docs/gemtext.gmi)
|
|
||||||
|
|
||||||
I've noticed something as I browse through the known constellation of Gemini
|
|
||||||
capsules though. I keep refreshing the CAPCOM feed of posts. I keep refreshing
|
|
||||||
the mailing list archives. I keep refreshing my email client, looking for new
|
|
||||||
content and feel frustrated when it doesn't show up like I expect it to. I'm
|
|
||||||
addicted to the newsfeeds. I'm caught in the trap that autoplay put me in. I'm a
|
|
||||||
victim to infinite scrolling and that constant little hit of dopamine that
|
|
||||||
modern social media has put on us all. Realizing this feels like I am realizing
|
|
||||||
an addiction to a drug (but I'd argue that it somewhat is a drug, by design,
|
|
||||||
what better way to get people to be exposed to ads than to make the service that
|
|
||||||
serves the ads addictive!).
|
|
||||||
|
|
||||||
I'm not sure how to best combat this. It feels kind of scary. I'm starting to
|
|
||||||
attempt to detox though. I'm writing a lot more on my Gemini capsule [4] [5]. I'm
|
|
||||||
starting to really consider the Fear of Missing Out when I design and implement
|
|
||||||
things in the future. So many things update instantly on the modern internet, it
|
|
||||||
may be a good idea to attempt to make something that updates weekly or even
|
|
||||||
monthly.
|
|
||||||
|
|
||||||
[[4]: My Gemini capsule](gemini://cetacean.club)
|
|
||||||
[[5]: [experimental] My Gemini capsule over HTTP](http://cetacean.club)
|
|
||||||
|
|
||||||
I'm still going to attempt a few ideas that I have regarding long term archival
|
|
||||||
of the Gemini constellation, but I'm definitely going to make sure that I take
|
|
||||||
the time to actually consider the consequences of my actions and what kind of
|
|
||||||
world it creates. I want to create the kind of world that enables people to
|
|
||||||
better themselves.
|
|
||||||
|
|
||||||
Let's work together to detox from the harmful effects of what we all have
|
|
||||||
created. I'm considering opening up a Gemini server that other people can have
|
|
||||||
accounts on and write about things that interest them.
|
|
||||||
|
|
||||||
If you want to get started with Gemini, I suggest taking a look at the main site
|
|
||||||
through the Gemini to HTTP proxy [6]. There are some clients listed in the pages
|
|
||||||
there, including a _very good_ iOS client that is currently in TestFlight.
|
|
||||||
Please do keep in mind that Gemini is very much a back-button navigation kind of
|
|
||||||
experience. The web has made people expect navigation links to be everywhere,
|
|
||||||
which can make it a weird/jarring experience at first, but you get used to it.
|
|
||||||
You can see evidence of this in my site with all the "Go back" links on each
|
|
||||||
page. I'll remove those at some point, but for now I'm going to keep them.
|
|
||||||
|
|
||||||
[[6]: Project Gemini](https://portal.mozz.us/gemini/gemini.circumlunar.space/)
|
|
||||||
|
|
||||||
Don't be afraid of missing out. It's inevitable. Things happen. It's okay for
|
|
||||||
them to happen without you having to see them. They will still be there when you
|
|
||||||
look again.
|
|
||||||
|
|
@ -1,202 +0,0 @@
|
||||||
---
|
|
||||||
title: "gitea-release Tool Announcement"
|
|
||||||
date: "2020-05-31"
|
|
||||||
tags:
|
|
||||||
- gitea
|
|
||||||
- rust
|
|
||||||
- release
|
|
||||||
---
|
|
||||||
|
|
||||||
# gitea-release Tool Announcement
|
|
||||||
|
|
||||||
I'm a big fan of automating things that can possibly be automated. One of the
|
|
||||||
biggest pains that I've consistently had is creating/tagging releases of
|
|
||||||
software. This has been a very manual process for me. I have to write up
|
|
||||||
changelogs, bump versions and then replicate the changelog/versions in the web
|
|
||||||
UI of whatever git forge the project in question is using. This works great at
|
|
||||||
smaller scales, but can quickly become a huge pain in the butt when this needs
|
|
||||||
to be done more often. Today I've written a small tool to help me automate this
|
|
||||||
going forward, it is named
|
|
||||||
[`gitea-release`](https://tulpa.dev/cadey/gitea-release). This is one of my
|
|
||||||
largest Rust projects to date and something I am incredibly happy with. I will
|
|
||||||
be using it going forward for all of my repos on my gitea instance
|
|
||||||
[tulpa.dev](https://tulpa.dev).
|
|
||||||
|
|
||||||
`gitea-release` is a spiritual clone of the tool [`github-release`][ghrelease],
|
|
||||||
but optimized for my workflow. The biggest changes are that it works on
|
|
||||||
[gitea][gitea] repos instead of github repos, is written in Rust instead of Go
|
|
||||||
and it automatically scrapes release notes from `CHANGELOG.md` as well as
|
|
||||||
reading the version of the software from `VERSION`.
|
|
||||||
|
|
||||||
[ghrelease]: https://github.com/github-release/github-release
|
|
||||||
[gitea]: https://gitea.io
|
|
||||||
|
|
||||||
## CHANGELOG.md and VERSION files
|
|
||||||
|
|
||||||
The `CHANGELOG.md` file is based on the [Keep a Changelog][kacl] format, but
|
|
||||||
modified slightly to make it easier for this tool. Here is an example changelog
|
|
||||||
that this tool accepts:
|
|
||||||
|
|
||||||
[kacl]: https://keepachangelog.com/en/1.0.0/
|
|
||||||
|
|
||||||
```markdown
|
|
||||||
# Changelog
|
|
||||||
All notable changes to this project will be documented in this file.
|
|
||||||
|
|
||||||
The format is based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/),
|
|
||||||
and this project adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0.html).
|
|
||||||
|
|
||||||
## 0.1.0
|
|
||||||
|
|
||||||
### FIXED
|
|
||||||
|
|
||||||
- Refrobnicate the spurious rilkefs
|
|
||||||
|
|
||||||
## 0.0.1
|
|
||||||
|
|
||||||
First release, proof of concept.
|
|
||||||
```
|
|
||||||
|
|
||||||
When a release is created for version 0.1.0, this tool will make the description
|
|
||||||
of the release about as follows:
|
|
||||||
|
|
||||||
```
|
|
||||||
### FIXED
|
|
||||||
|
|
||||||
- Refrobnicate the spurious rilkefs
|
|
||||||
```
|
|
||||||
|
|
||||||
This allows the changelog file to be the ultimate source of truth for release
|
|
||||||
notes with this tool.
|
|
||||||
|
|
||||||
The `VERSION` file plays into this as well. The `VERSION` file MUST be a single
|
|
||||||
line containing a [semantic version][semver] string. This allows the `VERSION`
|
|
||||||
file to be the ultimate source of truth for software version data with this
|
|
||||||
tool.
|
|
||||||
|
|
||||||
[semver]: https://semver.org/spec/v2.0.0.html
|
|
||||||
|
|
||||||
## Release Process
|
|
||||||
|
|
||||||
When this tool is run with the `release` subcommand, the following actions take place:
|
|
||||||
|
|
||||||
- The `VERSION` file is read and loaded as the desired tag for the repo
|
|
||||||
- The `CHANGELOG.md` file is read and the changes for the `VERSION` are
|
|
||||||
cherry-picked out of the file
|
|
||||||
- The git repo is checked to see if that tag already exists
|
|
||||||
- If the tag exists, the tool exits and does nothing
|
|
||||||
- If the tag does not exist, it is created (with the changelog fragment as the
|
|
||||||
body of the tag) and pushed to the gitea server using the supplied gitea token
|
|
||||||
- A gitea release is created using the changelog fragment and the release name
|
|
||||||
is generated from the `VERSION` string
|
|
||||||
|
|
||||||
## Automation of the Automation
|
|
||||||
|
|
||||||
This tool works perfectly well locally, but this doesn't make it fully
|
|
||||||
automated from the gitea repo. I use [drone][drone] as a CI/CD tool for my gitea
|
|
||||||
repos. Drone has a very convenient and simple to use [plugin
|
|
||||||
system][droneplugin] that was easy to integrate with [structopt][structopt].
|
|
||||||
|
|
||||||
[drone]: https://drone.io
|
|
||||||
[droneplugin]: https://docs.drone.io/plugins/overview/
|
|
||||||
[structopt]: https://crates.io/crates/structopt
|
|
||||||
|
|
||||||
I created a drone plugin at `xena/gitea-release` that can be configured as a
|
|
||||||
pipeline step in your `.drone.yml` like this:
|
|
||||||
|
|
||||||
```yaml
|
|
||||||
kind: pipeline
|
|
||||||
name: ci/release
|
|
||||||
steps:
|
|
||||||
- name: whatever unit testing step
|
|
||||||
# ...
|
|
||||||
- name: auto-release
|
|
||||||
image: xena/gitea-release:0.2.5
|
|
||||||
settings:
|
|
||||||
auth_username: cadey
|
|
||||||
changelog_path: ./CHANGELOG.md
|
|
||||||
gitea_server: https://tulpa.dev
|
|
||||||
gitea_token:
|
|
||||||
from_secret: GITEA_TOKEN
|
|
||||||
when:
|
|
||||||
event:
|
|
||||||
- push
|
|
||||||
branch:
|
|
||||||
- master
|
|
||||||
```
|
|
||||||
|
|
||||||
This allows me to bump the `VERSION` and `CHANGELOG.md`, then push that commit
|
|
||||||
to git and a new release will automatically be created. You can see an example
|
|
||||||
of this in action with [the drone build history of the gitea-release
|
|
||||||
repo](https://drone.tulpa.dev/cadey/gitea-release). You can also how the
|
|
||||||
`CHANGELOG.md` file grows with the [CHANGELOG of
|
|
||||||
gitea-release](https://tulpa.dev/cadey/gitea-release/src/branch/master/CHANGELOG.md).
|
|
||||||
|
|
||||||
Once the release is pushed to gitea, you can then use drone to trigger
|
|
||||||
deployment commands. For example here is the deployment pipeline used to
|
|
||||||
automatically update the docker image for the gitea-release tool:
|
|
||||||
|
|
||||||
```yaml
|
|
||||||
kind: pipeline
|
|
||||||
name: docker
|
|
||||||
steps:
|
|
||||||
- name: build docker image
|
|
||||||
image: "monacoremo/nix:2020-04-05-05f09348-circleci"
|
|
||||||
environment:
|
|
||||||
USER: root
|
|
||||||
commands:
|
|
||||||
- cachix use xe
|
|
||||||
- nix-build docker.nix
|
|
||||||
- cp $(readlink result) /result/docker.tgz
|
|
||||||
volumes:
|
|
||||||
- name: image
|
|
||||||
path: /result
|
|
||||||
when:
|
|
||||||
event:
|
|
||||||
- tag
|
|
||||||
|
|
||||||
- name: push docker image
|
|
||||||
image: docker:dind
|
|
||||||
volumes:
|
|
||||||
- name: image
|
|
||||||
path: /result
|
|
||||||
- name: dockersock
|
|
||||||
path: /var/run/docker.sock
|
|
||||||
commands:
|
|
||||||
- docker load -i /result/docker.tgz
|
|
||||||
- echo $DOCKER_PASSWORD | docker login -u $DOCKER_USERNAME --password-stdin
|
|
||||||
- docker push xena/gitea-release
|
|
||||||
environment:
|
|
||||||
DOCKER_USERNAME:
|
|
||||||
from_secret: DOCKER_USERNAME
|
|
||||||
DOCKER_PASSWORD:
|
|
||||||
from_secret: DOCKER_PASSWORD
|
|
||||||
when:
|
|
||||||
event:
|
|
||||||
- tag
|
|
||||||
|
|
||||||
volumes:
|
|
||||||
- name: image
|
|
||||||
temp: {}
|
|
||||||
- name: dockersock
|
|
||||||
host:
|
|
||||||
path: /var/run/docker.sock
|
|
||||||
```
|
|
||||||
|
|
||||||
This pipeline will use [Nix](https://nixos.org/nix) to build the docker image,
|
|
||||||
load it into a Docker daemon and then log into the Docker Hub and push it. This
|
|
||||||
can then be used to do whatever you want. It may also be a good idea to push a
|
|
||||||
docker image for every commit and then re-label the tagged commits, but this
|
|
||||||
wasn't implemented in this repo.
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
I hope this tool will be useful. I will accept feedback over [any contact
|
|
||||||
method](/contact). If you want to contribute directly to the project, please
|
|
||||||
feel free to create [issues](https://tulpa.dev/cadey/gitea-release/issues) or
|
|
||||||
[pull requests](https://tulpa.dev/cadey/gitea-release/pulls). If you don't want
|
|
||||||
to create an account on my git server, get me the issue details or code diffs
|
|
||||||
somehow and I will do everything I can to fix issues and integrate code. I just
|
|
||||||
want to make this tool better however I can.
|
|
||||||
|
|
||||||
Be well.
|
|
||||||
|
|
@ -1,78 +0,0 @@
|
||||||
---
|
|
||||||
title: hlang in 30 Seconds
|
|
||||||
date: 2021-01-04
|
|
||||||
series: h
|
|
||||||
tags:
|
|
||||||
- satire
|
|
||||||
---
|
|
||||||
|
|
||||||
# hlang in 30 Seconds
|
|
||||||
|
|
||||||
hlang (the h language) is a revolutionary new use of WebAssembly that enables
|
|
||||||
single-paridigm programming without any pesky state or memory accessing. The
|
|
||||||
simplest program you can use in hlang is the h world program:
|
|
||||||
|
|
||||||
```
|
|
||||||
h
|
|
||||||
```
|
|
||||||
|
|
||||||
When run in [the hlang playground](https://h.christine.website/play), you can
|
|
||||||
see its output:
|
|
||||||
|
|
||||||
```
|
|
||||||
h
|
|
||||||
```
|
|
||||||
|
|
||||||
To get more output, separate multiple h's by spaces:
|
|
||||||
|
|
||||||
```
|
|
||||||
h h h h
|
|
||||||
```
|
|
||||||
|
|
||||||
This returns:
|
|
||||||
|
|
||||||
```
|
|
||||||
h
|
|
||||||
h
|
|
||||||
h
|
|
||||||
h
|
|
||||||
```
|
|
||||||
|
|
||||||
## Internationalization
|
|
||||||
|
|
||||||
For internationalization concerns, hlang also supports the Lojbanic h `'`. You can
|
|
||||||
mix h and `'` to your heart's content:
|
|
||||||
|
|
||||||
```
|
|
||||||
' h '
|
|
||||||
```
|
|
||||||
|
|
||||||
This returns:
|
|
||||||
|
|
||||||
```
|
|
||||||
'
|
|
||||||
h
|
|
||||||
'
|
|
||||||
```
|
|
||||||
|
|
||||||
Finally an easy solution to your pesky Lojban internationalization problems!
|
|
||||||
|
|
||||||
## Errors
|
|
||||||
|
|
||||||
For maximum understandability, compiler errors are provided in Lojban. For
|
|
||||||
example this error tells you that you have an invalid character at the first
|
|
||||||
character of the string:
|
|
||||||
|
|
||||||
```
|
|
||||||
h: gentoldra fi'o zvati fe li no
|
|
||||||
```
|
|
||||||
|
|
||||||
Here is an interlinear gloss of that error:
|
|
||||||
|
|
||||||
```
|
|
||||||
h: gentoldra fi'o zvati fe li no
|
|
||||||
grammar-wrong existing-at second-place use-number 0
|
|
||||||
```
|
|
||||||
|
|
||||||
And now you are fully fluent in hlang, the most exciting programming language
|
|
||||||
since sliced bread.
|
|
||||||
|
|
@ -1,164 +0,0 @@
|
||||||
---
|
|
||||||
title: How HTTP Requests Work
|
|
||||||
date: 2020-05-19
|
|
||||||
tags:
|
|
||||||
- http
|
|
||||||
- ohgod
|
|
||||||
- philosophy
|
|
||||||
---
|
|
||||||
|
|
||||||
# How HTTP Requests Work
|
|
||||||
|
|
||||||
Reading this webpage is possible because of millions of hours of effort with
|
|
||||||
tens of thousands of actors across thousands of companies. At some level it's a
|
|
||||||
minor miracle that this all works at all. Here's a preview into the madness that
|
|
||||||
goes into hitting enter on christine.website and this website being loaded.
|
|
||||||
|
|
||||||
## Beginnings
|
|
||||||
|
|
||||||
The user types in `https://christine.website` into the address bar and hits
|
|
||||||
enter on the keyboard. This sends a signal over USB to the computer and the
|
|
||||||
kernel polls the USB controller for a new message. It's recognized as from the
|
|
||||||
keyboard. The input is then sent to the browser through an input driver talking
|
|
||||||
to a windowing server talking to the browser program.
|
|
||||||
|
|
||||||
The browser selects the memory region normally reserved for the address bar. The
|
|
||||||
browser then parses this string as an [RFC 3986][rfc3986] URI and scrapes out
|
|
||||||
the protocol (https), hostname (christine.website) and path (/). The browser
|
|
||||||
then uses this information to create an abstract HTTP request object with the
|
|
||||||
Host header set to christine.website, HTTP method (GET), and path set to the
|
|
||||||
path. This request object then passes through various layers of credential
|
|
||||||
storage and middleware to add the appropriate cookies and other headers in order
|
|
||||||
to tell my website what language it should localize the response to, what
|
|
||||||
compression methods the browser understands, and what browser is being used to
|
|
||||||
make the request.
|
|
||||||
|
|
||||||
[rfc3986]: https://tools.ietf.org/html/rfc3986
|
|
||||||
|
|
||||||
## Connections
|
|
||||||
|
|
||||||
The browser then checks if it has a connection to christine.website open
|
|
||||||
already. If it does not, then it creates a new one. It creates a new connection
|
|
||||||
by figuring out what the IP address of christine.website is using [DNS][dns]. A
|
|
||||||
DNS request is made over [UDP][udp] on port 53 to the DNS server configured in
|
|
||||||
the operating system (such as 8.8.8.8, 1.1.1.1 or 75.75.75.75). The UDP
|
|
||||||
connection is created using operating system-dependent system calls and a DNS
|
|
||||||
request is sent.
|
|
||||||
|
|
||||||
[udp]: https://en.wikipedia.org/wiki/User_Datagram_Protocol
|
|
||||||
[dns]: https://en.wikipedia.org/wiki/Domain_Name_System
|
|
||||||
|
|
||||||
The packet that was created then is destined for the DNS server and added to the
|
|
||||||
operating system's output queue. The operating system then looks in its routing
|
|
||||||
table to see where the packet should go. If the packet matches a route, it is
|
|
||||||
queued for output to the relevant network card. The network card layer then
|
|
||||||
checks the ARP table to see what [mac address][macaddress] the
|
|
||||||
[ethernet][ethernet] frame should be sent to. If the ARP table doesn't have a
|
|
||||||
match, then an arp probe is broadcasted to every node on the local network. Then
|
|
||||||
the driver waits for an arp response to be sent to it with the correct IP -> MAC
|
|
||||||
address mapping. The driver then uses this information to send out the ethernet
|
|
||||||
frame to the node that matches the IP address in the routing table. From there
|
|
||||||
the packet is validated on the router it was sent to. It then unwraps the packet
|
|
||||||
to the IP layer to figure out the destination network interface to use. If this
|
|
||||||
router also does NAT termination, it creates an entry in the NAT table for
|
|
||||||
future use for a site-configured amount of time (for UDP at least). It then
|
|
||||||
passes the packet on to the correct node and this process is repeated until it
|
|
||||||
gets to the remote DNS server.
|
|
||||||
|
|
||||||
[macaddress]: https://en.wikipedia.org/wiki/MAC_address
|
|
||||||
[ethernet]: https://en.wikipedia.org/wiki/Ethernet
|
|
||||||
|
|
||||||
The DNS server then unwraps the ethernet frame into an IP packet and then as a
|
|
||||||
UDP packet and a DNS request. It checks its database for a match and if one is
|
|
||||||
not found, it attempts to discover the correct name server to contact by using a
|
|
||||||
NS record query to its upstreams or the authoritative name server for the
|
|
||||||
WEBSITE namespace. This then creates another process of ethernet frames and UDP
|
|
||||||
packets until it reaches the upstream DNS server which hopefully should reply
|
|
||||||
with the correct address. Once the DNS server gets the information that is
|
|
||||||
needed, it sends this back the results to the client as a wire-format DNS
|
|
||||||
response.
|
|
||||||
|
|
||||||
UDP is unreliable by design, so this packet may or may not survive the entire
|
|
||||||
round trip. It may take one or more retries for the DNS information to get to
|
|
||||||
the remote server and back, but it usually works the first time. The response to
|
|
||||||
this request is cached based on the time-to-live specified in the DNS response.
|
|
||||||
The response also contains the IP address of christine.website.
|
|
||||||
|
|
||||||
## Security
|
|
||||||
|
|
||||||
The protocol used in the URL determines which TCP port the browser connects to.
|
|
||||||
If it is http, it uses port 80. If it is https, it uses port 443. The user
|
|
||||||
specified HTTPS, so port 443 on whatever IP address DNS returned is dialed using
|
|
||||||
the operating system's network stack system calls. The [TCP][tcp] three-way
|
|
||||||
handshake is started with that target IP address and port. The client sends a
|
|
||||||
SYN packet, the server replies with a SYN ACK packet and the client replies with
|
|
||||||
an ACK packet. This indicates that the entire TCP session is active and data can
|
|
||||||
be transferred and read through it.
|
|
||||||
|
|
||||||
[tcp]: https://en.wikipedia.org/wiki/Transmission_Control_Protocol
|
|
||||||
|
|
||||||
However, this data is UNENCRYPTED by default. [Transport Layer Security][tls] is
|
|
||||||
used to encrypt this data so prying eyes can't look into it. TLS has its own
|
|
||||||
handshake too. The session is established by sending a TLS ClientHello packet
|
|
||||||
with the domain name (christine.website), the list of ciphers the client
|
|
||||||
supports, any application layer protocols the client supports (like HTTP/2) and
|
|
||||||
the list of TLS versions that the client supports. This information is sent over
|
|
||||||
the wire to the remote server using that entire long and complicated process
|
|
||||||
that I spelled out for how DNS works, except a TCP session requires the other
|
|
||||||
side to acknowledge when data is successfully received. The server on the other
|
|
||||||
end replies with a ClientHelloResponse that contains a HTTPS certificate and the
|
|
||||||
list of protocols and ciphers the server supports. Then they do an [encryption
|
|
||||||
session setup rain dance][tlsraindance] that I don't completely understand and
|
|
||||||
the resulting channel is encrypted with cipher (or encrypted) text written and
|
|
||||||
read from the wire and a session layer translates that cipher text to clear text
|
|
||||||
for the other parts of the browser stack.
|
|
||||||
|
|
||||||
[tls]: https://en.wikipedia.org/wiki/Transport_Layer_Security
|
|
||||||
[tlsraindance]: https://www.cloudflare.com/learning/ssl/what-happens-in-a-tls-handshake/
|
|
||||||
|
|
||||||
The browser then uses the information in the ClientHelloResponse to decide how
|
|
||||||
to proceed from here.
|
|
||||||
|
|
||||||
## HTTP
|
|
||||||
|
|
||||||
If the browser notices the server supports HTTP/2 it sets up a HTTP/2 session
|
|
||||||
(with a handshake that involves a few roundtrips like what I described for DNS)
|
|
||||||
and creates a new stream for this request. The browser then formats the request
|
|
||||||
as HTTP/2 wire format bytes (binary format) and writes it to the HTTP/2 stream,
|
|
||||||
which writes it to the HTTP/2 framing layer, which writes it to the encryption
|
|
||||||
layer, which writes it to the network socket and sends it over the internet.
|
|
||||||
|
|
||||||
If the browser notices the server DOES NOT support HTTP/2, it formats the
|
|
||||||
request as HTTP/1.1 wire formatted bytes and writes it to the encryption layer,
|
|
||||||
which writes it to the network socket and sends it over the internet using that
|
|
||||||
complicated process I spelled out for DNS.
|
|
||||||
|
|
||||||
This then hits the remote load balancer which parses the client HTTP request and
|
|
||||||
uses site-local configuration to select the best application server to handle
|
|
||||||
the response. It then forwards the client's HTTP request to the correct server
|
|
||||||
by creating a TCP session to that backend, writing the HTTP request and waiting
|
|
||||||
for a response over that TCP session. Depending on site-local configuration
|
|
||||||
there may be layers of encryption involved.
|
|
||||||
|
|
||||||
## Application Server
|
|
||||||
|
|
||||||
Now, the request finally gets to the application server. This TCP session is
|
|
||||||
accepted by the application server and the headers are read into memory. The
|
|
||||||
path is read by the application server and the correct handler is chosen. The
|
|
||||||
HTML for the front page of christine.website is rendered and written to the TCP
|
|
||||||
session and travels to the load balancer, gets encrypted with TLS, the encrypted
|
|
||||||
HTML gets sent back over the internet to your browser and then your browser
|
|
||||||
decrypts it and starts to parse and display the website. The browser will run
|
|
||||||
into places where it needs more resources (such as stylesheets or images), so it will
|
|
||||||
make additional HTTP requests to the load balancer to grab those too.
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
The end result is that the user sees the website in all its glory. Given all
|
|
||||||
these moving parts it's astounding that this works as reliably as it does. Each
|
|
||||||
of the TCP, ARP and DNS requests also happen at each level of the stack. There
|
|
||||||
are layers upon layers upon layers of interacting protocols and implementations.
|
|
||||||
|
|
||||||
This is why it is hard to reliably put a website on the internet. If there is a
|
|
||||||
god, they are surely the one holding all these potentially unreliable systems
|
|
||||||
together to make everything appear like it is working.
|
|
||||||
|
|
@ -1,574 +0,0 @@
|
||||||
---
|
|
||||||
title: "How I Start: Nix"
|
|
||||||
date: 2020-03-08
|
|
||||||
series: howto
|
|
||||||
tags:
|
|
||||||
- nix
|
|
||||||
- rust
|
|
||||||
---
|
|
||||||
|
|
||||||
# How I Start: Nix
|
|
||||||
|
|
||||||
[Nix][nix] is a tool that helps people create reproducible builds. This means that
|
|
||||||
given a known input, you can get the same output on other machines. Let's build
|
|
||||||
and deploy a small Rust service with Nix. This will not require the Rust compiler
|
|
||||||
to be installed with [rustup][rustup] or similar.
|
|
||||||
|
|
||||||
[nix]: https://nixos.org/nix/
|
|
||||||
[rustup]: https://rustup.rs
|
|
||||||
|
|
||||||
- Setting up your environment
|
|
||||||
- A new project
|
|
||||||
- Setting up the Rust compiler
|
|
||||||
- Serving HTTP
|
|
||||||
- A simple package build
|
|
||||||
- Shipping it in a docker image
|
|
||||||
|
|
||||||
## Setting up your environment
|
|
||||||
|
|
||||||
The first step is to install Nix. If you are using a Linux machine, run this
|
|
||||||
script:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ curl https://nixos.org/nix/install | sh
|
|
||||||
```
|
|
||||||
|
|
||||||
This will prompt you for more information as it goes on, so be sure to follow
|
|
||||||
the instructions carefully. Once it is done, close and re-open your shell. After
|
|
||||||
you have done this, `nix-env` should exist in your shell. Try to run it:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ nix-env
|
|
||||||
error: no operation specified
|
|
||||||
Try 'nix-env --help' for more information.
|
|
||||||
```
|
|
||||||
|
|
||||||
Let's install a few other tools to help us with development. First, let's
|
|
||||||
install [lorri][lorri] to help us manage our development shell:
|
|
||||||
|
|
||||||
[lorri]: https://github.com/target/lorri
|
|
||||||
|
|
||||||
```
|
|
||||||
$ nix-env --install --file https://github.com/target/lorri/archive/master.tar.gz
|
|
||||||
```
|
|
||||||
|
|
||||||
This will automatically download and build lorri for your system based on the
|
|
||||||
latest possible version. Once that is done, open another shell window (the lorri
|
|
||||||
docs include ways to do this more persistently, but this will work for now) and run:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ lorri daemon
|
|
||||||
```
|
|
||||||
|
|
||||||
Now go back to your main shell window and install [direnv][direnv]:
|
|
||||||
|
|
||||||
[direnv]: https://direnv.net
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ nix-env --install direnv
|
|
||||||
```
|
|
||||||
|
|
||||||
Next, follow the [shell setup][direnvsetup] needed for your shell. I personally
|
|
||||||
use `fish` with [oh my fish][omf], so I would run this:
|
|
||||||
|
|
||||||
[direnvsetup]: https://direnv.net/docs/hook.html
|
|
||||||
[omf]: https://github.com/oh-my-fish/oh-my-fish
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ omf install direnv
|
|
||||||
```
|
|
||||||
|
|
||||||
Finally, let's install [niv][niv] to help us handle dependencies for the
|
|
||||||
project. This will allow us to make sure that our builds pin _everything_ to a
|
|
||||||
specific set of versions, including operating system packages.
|
|
||||||
|
|
||||||
[niv]: https://github.com/nmattia/niv
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ nix-env --install niv
|
|
||||||
```
|
|
||||||
|
|
||||||
Now that we have all of the tools we will need installed, let's create the
|
|
||||||
project.
|
|
||||||
|
|
||||||
# A new project
|
|
||||||
|
|
||||||
Go to your favorite place to put code and make a new folder. I personally prefer
|
|
||||||
`~/code`, so I will be using that here:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ cd ~/code
|
|
||||||
$ mkdir helloworld
|
|
||||||
$ cd helloworld
|
|
||||||
```
|
|
||||||
|
|
||||||
Let's set up the basic skeleton of the project. First, initialize niv:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ niv init
|
|
||||||
```
|
|
||||||
|
|
||||||
This will add the latest versions of `niv` itself and the packages used for the
|
|
||||||
system to `nix/sources.json`. This will allow us to pin exact versions so the
|
|
||||||
environment is as predictable as possible. Sometimes the versions of software in
|
|
||||||
the pinned nixpkgs are too old. If this happens, you can update to the
|
|
||||||
"unstable" branch of nixpkgs with this command:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ niv update nixpkgs -b nixpkgs-unstable
|
|
||||||
```
|
|
||||||
|
|
||||||
Next, set up lorri using `lorri init`:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ lorri init
|
|
||||||
```
|
|
||||||
|
|
||||||
This will create `shell.nix` and `.envrc`. `shell.nix` will be where we define
|
|
||||||
the development environment for this service. `.envrc` is used to tell direnv
|
|
||||||
what it needs to do. Let's try and activate the `.envrc`:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ cd .
|
|
||||||
direnv: error /home/cadey/code/helloworld/.envrc is blocked. Run `direnv allow`
|
|
||||||
to approve its content
|
|
||||||
```
|
|
||||||
|
|
||||||
Let's review its content:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ cat .envrc
|
|
||||||
eval "$(lorri direnv)"
|
|
||||||
```
|
|
||||||
|
|
||||||
This seems reasonable, so approve it with `direnv allow` like the error message
|
|
||||||
suggests:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ direnv allow
|
|
||||||
```
|
|
||||||
|
|
||||||
Now let's customize the `shell.nix` file to use our pinned version of nixpkgs.
|
|
||||||
Currently, it looks something like this:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
# shell.nix
|
|
||||||
let
|
|
||||||
pkgs = import <nixpkgs> {};
|
|
||||||
in
|
|
||||||
pkgs.mkShell {
|
|
||||||
buildInputs = [
|
|
||||||
pkgs.hello
|
|
||||||
];
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
This currently imports nixpkgs from the system-level version of it. This means
|
|
||||||
that different systems could have different versions of nixpkgs on it, and that
|
|
||||||
could make the `shell.nix` file hard to reproduce between machines. Let's import
|
|
||||||
the pinned version of nixpkgs that niv created:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
# shell.nix
|
|
||||||
let
|
|
||||||
sources = import ./nix/sources.nix;
|
|
||||||
pkgs = import sources.nixpkgs {};
|
|
||||||
in
|
|
||||||
pkgs.mkShell {
|
|
||||||
buildInputs = [
|
|
||||||
pkgs.hello
|
|
||||||
];
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
And then let's test it with `lorri shell`:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ lorri shell
|
|
||||||
lorri: building environment........ done
|
|
||||||
(lorri) $
|
|
||||||
```
|
|
||||||
|
|
||||||
And let's see if `hello` is available inside the shell:
|
|
||||||
|
|
||||||
```console
|
|
||||||
(lorri) $ hello
|
|
||||||
Hello, world!
|
|
||||||
```
|
|
||||||
|
|
||||||
You can set environment variables inside the `shell.nix` file. Do so like this:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
# shell.nix
|
|
||||||
let
|
|
||||||
sources = import ./nix/sources.nix;
|
|
||||||
pkgs = import sources.nixpkgs {};
|
|
||||||
in
|
|
||||||
pkgs.mkShell {
|
|
||||||
buildInputs = [
|
|
||||||
pkgs.hello
|
|
||||||
];
|
|
||||||
|
|
||||||
# Environment variables
|
|
||||||
HELLO="world";
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
Wait a moment for lorri to finish rebuilding the development environment and
|
|
||||||
then let's see if the environment variable shows up:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ cd .
|
|
||||||
direnv: loading ~/code/helloworld/.envrc
|
|
||||||
<output snipped>
|
|
||||||
$ echo $HELLO
|
|
||||||
world
|
|
||||||
```
|
|
||||||
|
|
||||||
Now that we have the basics of the environment set up, lets install the Rust
|
|
||||||
compiler.
|
|
||||||
|
|
||||||
# Setting up the Rust compiler
|
|
||||||
|
|
||||||
First, add [nixpkgs-mozilla][nixpkgsmoz] to niv:
|
|
||||||
|
|
||||||
[nixpkgsmoz]: https://github.com/mozilla/nixpkgs-mozilla
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ niv add mozilla/nixpkgs-mozilla
|
|
||||||
```
|
|
||||||
|
|
||||||
Then create `nix/rust.nix` in your repo:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
# nix/rust.nix
|
|
||||||
{ sources ? import ./sources.nix }:
|
|
||||||
|
|
||||||
let
|
|
||||||
pkgs =
|
|
||||||
import sources.nixpkgs { overlays = [ (import sources.nixpkgs-mozilla) ]; };
|
|
||||||
channel = "nightly";
|
|
||||||
date = "2020-03-08";
|
|
||||||
targets = [ ];
|
|
||||||
chan = pkgs.rustChannelOfTargets channel date targets;
|
|
||||||
in chan
|
|
||||||
```
|
|
||||||
|
|
||||||
This creates a nix function that takes in the pre-imported list of sources,
|
|
||||||
creates a copy of nixpkgs with Rust at the nightly version `2020-03-08` overlaid
|
|
||||||
into it, and exposes the rust package out of it. Let's add this to `shell.nix`:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
# shell.nix
|
|
||||||
let
|
|
||||||
sources = import ./nix/sources.nix;
|
|
||||||
rust = import ./nix/rust.nix { inherit sources; };
|
|
||||||
pkgs = import sources.nixpkgs { };
|
|
||||||
in
|
|
||||||
pkgs.mkShell {
|
|
||||||
buildInputs = [
|
|
||||||
rust
|
|
||||||
];
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
Then ask lorri to recreate the development environment. This may take a bit to
|
|
||||||
run because it's setting up everything the Rust compiler requires to run.
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ lorri shell
|
|
||||||
(lorri) $
|
|
||||||
```
|
|
||||||
|
|
||||||
Let's see what version of Rust is installed:
|
|
||||||
|
|
||||||
```console
|
|
||||||
(lorri) $ rustc --version
|
|
||||||
rustc 1.43.0-nightly (823ff8cf1 2020-03-07)
|
|
||||||
```
|
|
||||||
|
|
||||||
This is exactly what we expect. Rust nightly versions get released with the
|
|
||||||
date of the previous day in them. To be extra sure, let's see what the shell
|
|
||||||
thinks `rustc` resolves to:
|
|
||||||
|
|
||||||
```console
|
|
||||||
(lorri) $ which rustc
|
|
||||||
/nix/store/w6zk1zijfwrnjm6xyfmrgbxb6dvvn6di-rust-1.43.0-nightly-2020-03-07-823ff8cf1/bin/rustc
|
|
||||||
```
|
|
||||||
|
|
||||||
And now exit that shell and reload direnv:
|
|
||||||
|
|
||||||
```console
|
|
||||||
(lorri) $ exit
|
|
||||||
$ cd .
|
|
||||||
direnv: loading ~/code/helloworld/.envrc
|
|
||||||
$ which rustc
|
|
||||||
/nix/store/w6zk1zijfwrnjm6xyfmrgbxb6dvvn6di-rust-1.43.0-nightly-2020-03-07-823ff8cf1/bin/rustc
|
|
||||||
```
|
|
||||||
|
|
||||||
And now we have Rust installed at an arbitrary nightly version for _that project
|
|
||||||
only_. This will work on other machines too. Now that we have our development
|
|
||||||
environment set up, let's serve HTTP.
|
|
||||||
|
|
||||||
## Serving HTTP
|
|
||||||
|
|
||||||
[Rocket][rocket] is a popular web framework for Rust programs. Let's use that to
|
|
||||||
create a small "hello, world" server. We will need to do the following:
|
|
||||||
|
|
||||||
[rocket]: https://rocket.rs
|
|
||||||
|
|
||||||
- Create the new Rust project
|
|
||||||
- Add Rocket as a dependency
|
|
||||||
- Write our "hello world" route
|
|
||||||
- Test a build of the service with `cargo build`
|
|
||||||
|
|
||||||
### Create the new Rust project
|
|
||||||
|
|
||||||
Create the new Rust project with `cargo init`:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ cargo init --vcs git .
|
|
||||||
Created binary (application) package
|
|
||||||
```
|
|
||||||
|
|
||||||
This will create the directory `src` and a file named `Cargo.toml`. Rust code
|
|
||||||
goes in `src` and the `Cargo.toml` file configures dependencies. Adding the
|
|
||||||
`--vcs git` flag also has cargo create a [gitignore][gitignore] file so that the
|
|
||||||
target folder isn't tracked by git.
|
|
||||||
|
|
||||||
[gitignore]: https://git-scm.com/docs/gitignore
|
|
||||||
|
|
||||||
### Add Rocket as a dependency
|
|
||||||
|
|
||||||
Open `Cargo.toml` and add the following to it:
|
|
||||||
|
|
||||||
```toml
|
|
||||||
[dependencies]
|
|
||||||
rocket = "0.4.3"
|
|
||||||
```
|
|
||||||
|
|
||||||
Then download/build Rocket with `cargo build`:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ cargo build
|
|
||||||
```
|
|
||||||
|
|
||||||
This will download all of the dependencies you need and precompile Rocket, and it
|
|
||||||
will help speed up later builds.
|
|
||||||
|
|
||||||
### Write our "hello world" route
|
|
||||||
|
|
||||||
Now put the following in `src/main.rs`:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
#![feature(proc_macro_hygiene, decl_macro)] // language features needed by Rocket
|
|
||||||
|
|
||||||
// Import the rocket macros
|
|
||||||
#[macro_use]
|
|
||||||
extern crate rocket;
|
|
||||||
|
|
||||||
// Create route / that returns "Hello, world!"
|
|
||||||
#[get("/")]
|
|
||||||
fn index() -> &'static str {
|
|
||||||
"Hello, world!"
|
|
||||||
}
|
|
||||||
|
|
||||||
fn main() {
|
|
||||||
rocket::ignite().mount("/", routes![index]).launch();
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
### Test a build
|
|
||||||
|
|
||||||
Rerun `cargo build`:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ cargo build
|
|
||||||
```
|
|
||||||
|
|
||||||
This will create the binary at `target/debug/helloworld`. Let's run it locally
|
|
||||||
and see if it works:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ ./target/debug/helloworld &
|
|
||||||
$ curl http://127.0.0.1:8000
|
|
||||||
Hello, world!
|
|
||||||
$ fg
|
|
||||||
<press control-c>
|
|
||||||
```
|
|
||||||
|
|
||||||
The HTTP service works. We have a binary that is created with the Rust compiler
|
|
||||||
Nix installed.
|
|
||||||
|
|
||||||
## A simple package build
|
|
||||||
|
|
||||||
Now that we have the HTTP service working, let's put it inside a nix package. We
|
|
||||||
will need to use [naersk][naersk] to do this. Add naersk to your project with
|
|
||||||
niv:
|
|
||||||
|
|
||||||
[naersk]: https://github.com/nmattia/naersk
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ niv add nmattia/naersk
|
|
||||||
```
|
|
||||||
|
|
||||||
Now let's create `helloworld.nix`:
|
|
||||||
|
|
||||||
```
|
|
||||||
# import niv sources and the pinned nixpkgs
|
|
||||||
{ sources ? import ./nix/sources.nix, pkgs ? import sources.nixpkgs { }}:
|
|
||||||
let
|
|
||||||
# import rust compiler
|
|
||||||
rust = import ./nix/rust.nix { inherit sources; };
|
|
||||||
|
|
||||||
# configure naersk to use our pinned rust compiler
|
|
||||||
naersk = pkgs.callPackage sources.naersk {
|
|
||||||
rustc = rust;
|
|
||||||
cargo = rust;
|
|
||||||
};
|
|
||||||
|
|
||||||
# tell nix-build to ignore the `target` directory
|
|
||||||
src = builtins.filterSource
|
|
||||||
(path: type: type != "directory" || builtins.baseNameOf path != "target")
|
|
||||||
./.;
|
|
||||||
in naersk.buildPackage {
|
|
||||||
inherit src;
|
|
||||||
remapPathPrefix =
|
|
||||||
true; # remove nix store references for a smaller output package
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
And then build it with `nix-build`:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ nix-build helloworld.nix
|
|
||||||
```
|
|
||||||
|
|
||||||
This can take a bit to run, but it will do the following things:
|
|
||||||
|
|
||||||
- Download naersk
|
|
||||||
- Download every Rust crate your HTTP service depends on into the Nix store
|
|
||||||
- Run your program's tests
|
|
||||||
- Build your dependencies into a Nix package
|
|
||||||
- Build your program with those dependencies
|
|
||||||
- Place a link to the result at `./result`
|
|
||||||
|
|
||||||
Once it is done, let's take a look at the result:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ du -hs ./result/bin/helloworld
|
|
||||||
2.1M ./result/bin/helloworld
|
|
||||||
|
|
||||||
$ ldd ./result/bin/helloworld
|
|
||||||
linux-vdso.so.1 (0x00007fffae080000)
|
|
||||||
libdl.so.2 => /nix/store/wx1vk75bpdr65g6xwxbj4rw0pk04v5j3-glibc-2.27/lib/libdl.so.2 (0x0
|
|
||||||
0007f3a01666000)
|
|
||||||
librt.so.1 => /nix/store/wx1vk75bpdr65g6xwxbj4rw0pk04v5j3-glibc-2.27/lib/librt.so.1 (0x0
|
|
||||||
0007f3a0165c000)
|
|
||||||
libpthread.so.0 => /nix/store/wx1vk75bpdr65g6xwxbj4rw0pk04v5j3-glibc-2.27/lib/libpthread
|
|
||||||
.so.0 (0x00007f3a0163b000)
|
|
||||||
libgcc_s.so.1 => /nix/store/wx1vk75bpdr65g6xwxbj4rw0pk04v5j3-glibc-2.27/lib/libgcc_s.so.
|
|
||||||
1 (0x00007f3a013f5000)
|
|
||||||
libc.so.6 => /nix/store/wx1vk75bpdr65g6xwxbj4rw0pk04v5j3-glibc-2.27/lib/libc.so.6 (0x000
|
|
||||||
07f3a0123f000)
|
|
||||||
/nix/store/wx1vk75bpdr65g6xwxbj4rw0pk04v5j3-glibc-2.27/lib/ld-linux-x86-64.so.2 => /lib6
|
|
||||||
4/ld-linux-x86-64.so.2 (0x00007f3a0160b000)
|
|
||||||
libm.so.6 => /nix/store/wx1vk75bpdr65g6xwxbj4rw0pk04v5j3-glibc-2.27/lib/libm.so.6 (0x000
|
|
||||||
07f3a010a9000)
|
|
||||||
```
|
|
||||||
|
|
||||||
This means that the Nix build created a 2.1 megabyte binary that only depends on
|
|
||||||
[glibc][glibc], the implementation of the C language standard library that Nix
|
|
||||||
prefers.
|
|
||||||
|
|
||||||
[glibc]: https://www.gnu.org/software/libc/
|
|
||||||
|
|
||||||
For repo cleanliness, add the `result` link to the [gitignore][gitignore]:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ echo 'result*' >> .gitignore
|
|
||||||
```
|
|
||||||
|
|
||||||
## Shipping it in a Docker image
|
|
||||||
|
|
||||||
Now that we have a package built, let's ship it in a docker image. nixpkgs
|
|
||||||
provides [dockerTools][dockertools] which helps us create docker images out of
|
|
||||||
Nix packages. Let's create `default.nix` with the following contents:
|
|
||||||
|
|
||||||
[dockertools]: https://nixos.org/nixpkgs/manual/#sec-pkgs-dockerTools
|
|
||||||
|
|
||||||
```nix
|
|
||||||
{ system ? builtins.currentSystem }:
|
|
||||||
|
|
||||||
let
|
|
||||||
sources = import ./nix/sources.nix;
|
|
||||||
pkgs = import sources.nixpkgs { };
|
|
||||||
helloworld = import ./helloworld.nix { inherit sources pkgs; };
|
|
||||||
|
|
||||||
name = "xena/helloworld";
|
|
||||||
tag = "latest";
|
|
||||||
|
|
||||||
in pkgs.dockerTools.buildLayeredImage {
|
|
||||||
inherit name tag;
|
|
||||||
contents = [ helloworld ];
|
|
||||||
|
|
||||||
config = {
|
|
||||||
Cmd = [ "/bin/helloworld" ];
|
|
||||||
Env = [ "ROCKET_PORT=5000" ];
|
|
||||||
WorkingDir = "/";
|
|
||||||
};
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
And then build it with `nix-build`:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ nix-build default.nix
|
|
||||||
```
|
|
||||||
|
|
||||||
This will create a tarball containing the docker image information as the result
|
|
||||||
of the Nix build. Load it into docker using `docker load`:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ docker load -i result
|
|
||||||
```
|
|
||||||
|
|
||||||
And then run it using `docker run`:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ docker run --rm -itp 52340:5000 xena/helloworld
|
|
||||||
```
|
|
||||||
|
|
||||||
Now test it using curl:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ curl http://127.0.0.1:52340
|
|
||||||
Hello, world!
|
|
||||||
```
|
|
||||||
|
|
||||||
And now you have a docker image you can run wherever you want. The
|
|
||||||
`buildLayeredImage` function used in `default.nix` also makes Nix put each
|
|
||||||
dependency of the package into its own docker layer. This makes new versions of
|
|
||||||
your program very efficient to upgrade on your clusters, realistically this
|
|
||||||
reduces the amount of data needed for new versions of the program down to what
|
|
||||||
changed. If nothing but some resources in their own package were changed, only
|
|
||||||
those packages get downloaded.
|
|
||||||
|
|
||||||
This is how I start a new project with Nix. I put all of the code described in
|
|
||||||
this post in [this GitHub repo][helloworldrepo] in case it helps. Have fun and
|
|
||||||
be well.
|
|
||||||
|
|
||||||
[helloworldrepo]: https://github.com/Xe/helloworld
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
For some "extra credit" tasks, try and see if you can do the following:
|
|
||||||
|
|
||||||
- Use the version of [niv][niv] that niv pinned
|
|
||||||
- Customize the environment of the container by following the [Rocket
|
|
||||||
configuration documentation](https://rocket.rs/v0.4/guide/configuration/)
|
|
||||||
- Add some more routes to the program
|
|
||||||
- Read the [Nix
|
|
||||||
documentation](https://nixos.org/nix/manual/#chap-writing-nix-expressions) and
|
|
||||||
learn more about writing Nix expressions
|
|
||||||
- Configure your editor/IDE to use the `direnv` path
|
|
||||||
|
|
@ -1,558 +0,0 @@
|
||||||
---
|
|
||||||
title: "How I Start: Rust"
|
|
||||||
date: 2020-03-15
|
|
||||||
series: howto
|
|
||||||
tags:
|
|
||||||
- rust
|
|
||||||
- how-i-start
|
|
||||||
- nix
|
|
||||||
---
|
|
||||||
|
|
||||||
# How I Start: Rust
|
|
||||||
|
|
||||||
[Rust][rustlang] is an exciting new programming language that makes it easy to
|
|
||||||
make understandable and reliable software. It is made by Mozilla and is used by
|
|
||||||
Amazon, Google, Microsoft and many other large companies.
|
|
||||||
|
|
||||||
[rustlang]: https://www.rust-lang.org/
|
|
||||||
|
|
||||||
Rust has a reputation of being difficult because it makes no effort to hide what
|
|
||||||
is going on. I'd like to show you how I start with Rust projects. Let's make a
|
|
||||||
small HTTP service using [Rocket][rocket].
|
|
||||||
|
|
||||||
[rocket]: https://rocket.rs
|
|
||||||
|
|
||||||
- Setting up your environment
|
|
||||||
- A new project
|
|
||||||
- Testing
|
|
||||||
- Adding functionality
|
|
||||||
- OpenAPI specifications
|
|
||||||
- Error responses
|
|
||||||
- Shipping it in a docker image
|
|
||||||
|
|
||||||
## Setting up your environment
|
|
||||||
|
|
||||||
The first step is to install the Rust compiler. You can use any method you like,
|
|
||||||
but since we are requiring the nightly version of Rust for this project, I
|
|
||||||
suggest using [rustup][rustup]:
|
|
||||||
|
|
||||||
[rustup]: https://rustup.rs/
|
|
||||||
|
|
||||||
```console
|
|
||||||
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh -s -- --default-toolchain nightly
|
|
||||||
```
|
|
||||||
|
|
||||||
If you are using [NixOS][nixos] or another Linux distribution with [Nix][nix]
|
|
||||||
installed, see [this post][howistartnix] for some information on how to set up
|
|
||||||
the Rust compiler.
|
|
||||||
|
|
||||||
[nixos]: https://nixos.org/nixos/
|
|
||||||
[nix]: https://nixos.org/nix/
|
|
||||||
[howistartnix]: https://christine.website/blog/how-i-start-nix-2020-03-08
|
|
||||||
|
|
||||||
## A new project
|
|
||||||
|
|
||||||
[Rocket][rocket] is a popular web framework for Rust programs. Let's use that to
|
|
||||||
create a small "hello, world" server. We will need to do the following:
|
|
||||||
|
|
||||||
[rocket]: https://rocket.rs/
|
|
||||||
|
|
||||||
- Create the new Rust project
|
|
||||||
- Add Rocket as a dependency
|
|
||||||
- Write the hello world route
|
|
||||||
- Test a build of the service with `cargo build`
|
|
||||||
- Run it and see what happens
|
|
||||||
|
|
||||||
### Create the new Rust project
|
|
||||||
|
|
||||||
Create the new Rust project with `cargo init`:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ cargo init --vcs git .
|
|
||||||
Created binary (application) package
|
|
||||||
```
|
|
||||||
|
|
||||||
This will create the directory `src` and a file named `Cargo.toml`. Rust code
|
|
||||||
goes in `src` and the `Cargo.toml` file configures dependencies. Adding the
|
|
||||||
`--vcs git` flag also has cargo create a [gitignore][gitignore] file so that the
|
|
||||||
target folder isn't tracked by git.
|
|
||||||
|
|
||||||
[gitignore]: https://git-scm.com/docs/gitignore
|
|
||||||
|
|
||||||
### Add Rocket as a dependency
|
|
||||||
|
|
||||||
Open `Cargo.toml` and add the following to it:
|
|
||||||
|
|
||||||
```toml
|
|
||||||
[dependencies]
|
|
||||||
rocket = "0.4.4"
|
|
||||||
```
|
|
||||||
|
|
||||||
Then download/build [Rocket][rocket] with `cargo build`:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ cargo build
|
|
||||||
```
|
|
||||||
|
|
||||||
This will download all of the dependencies you need and precompile Rocket, and it
|
|
||||||
will help speed up later builds.
|
|
||||||
|
|
||||||
### Write our "hello world" route
|
|
||||||
|
|
||||||
Now put the following in `src/main.rs`:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
#![feature(proc_macro_hygiene, decl_macro)] // Nightly-only language features needed by Rocket
|
|
||||||
|
|
||||||
// Import the rocket macros
|
|
||||||
#[macro_use]
|
|
||||||
extern crate rocket;
|
|
||||||
|
|
||||||
/// Create route / that returns "Hello, world!"
|
|
||||||
#[get("/")]
|
|
||||||
fn index() -> &'static str {
|
|
||||||
"Hello, world!"
|
|
||||||
}
|
|
||||||
|
|
||||||
fn main() {
|
|
||||||
rocket::ignite().mount("/", routes![index]).launch();
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
### Test a build
|
|
||||||
|
|
||||||
Rerun `cargo build`:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ cargo build
|
|
||||||
```
|
|
||||||
|
|
||||||
This will create the binary at `target/debug/helloworld`. Let's run it locally
|
|
||||||
and see if it works:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ ./target/debug/helloworld
|
|
||||||
```
|
|
||||||
|
|
||||||
And in another terminal window:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ curl http://127.0.0.1:8000
|
|
||||||
Hello, world!
|
|
||||||
$ fg
|
|
||||||
<press control-c>
|
|
||||||
```
|
|
||||||
|
|
||||||
The HTTP service works. We have a binary that is created with the Rust compiler.
|
|
||||||
This binary will be available at `./target/debug/helloworld`. However, it could
|
|
||||||
use some tests.
|
|
||||||
|
|
||||||
## Testing
|
|
||||||
|
|
||||||
Rocket has support for [unit testing][rockettest] built in. Let's create a tests
|
|
||||||
module and verify this route in testing.
|
|
||||||
|
|
||||||
[rockettest]: https://rocket.rs/v0.4/guide/testing/
|
|
||||||
|
|
||||||
### Create a tests module
|
|
||||||
|
|
||||||
Rust allows you to nest modules within files using the `mod` keyword. Create a
|
|
||||||
`tests` module that will only build when testing is requested:
|
|
||||||
|
|
||||||
[rustmod]: https://doc.rust-lang.org/rust-by-example/mod/visibility.html
|
|
||||||
|
|
||||||
```rust
|
|
||||||
#[cfg(test)] // Only compile this when unit testing is requested
|
|
||||||
mod tests {
|
|
||||||
use super::*; // Modules are their own scope, so you
|
|
||||||
// need to explictly use the stuff in
|
|
||||||
// the parent module.
|
|
||||||
|
|
||||||
use rocket::http::Status;
|
|
||||||
use rocket::local::*;
|
|
||||||
|
|
||||||
#[test]
|
|
||||||
fn test_index() {
|
|
||||||
// create the rocket instance to test
|
|
||||||
let rkt = rocket::ignite().mount("/", routes![index]);
|
|
||||||
|
|
||||||
// create a HTTP client bound to this rocket instance
|
|
||||||
let client = Client::new(rkt).expect("valid rocket");
|
|
||||||
|
|
||||||
// get a HTTP response
|
|
||||||
let mut response = client.get("/").dispatch();
|
|
||||||
|
|
||||||
// Ensure it returns HTTP 200
|
|
||||||
assert_eq!(response.status(), Status::Ok);
|
|
||||||
|
|
||||||
// Ensure the body is what we expect it to be
|
|
||||||
assert_eq!(response.body_string(), Some("Hello, world!".into()));
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
### Run tests
|
|
||||||
|
|
||||||
`cargo test` is used to run tests in Rust. Let's run it:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ cargo test
|
|
||||||
Compiling helloworld v0.1.0 (/home/cadey/code/helloworld)
|
|
||||||
Finished test [unoptimized + debuginfo] target(s) in 1.80s
|
|
||||||
Running target/debug/deps/helloworld-49d1bd4d4f816617
|
|
||||||
|
|
||||||
running 1 test
|
|
||||||
test tests::test_index ... ok
|
|
||||||
```
|
|
||||||
|
|
||||||
## Adding functionality
|
|
||||||
|
|
||||||
Most HTTP services return [JSON][json] or JavaScript Object Notation as a way to
|
|
||||||
pass objects between computer programs. Let's use Rocket's [JSON
|
|
||||||
support][rocketjson] to add a `/hostinfo` route to this app that returns some
|
|
||||||
simple information:
|
|
||||||
|
|
||||||
[json]: https://www.json.org/json-en.html
|
|
||||||
[rocketjson]: https://api.rocket.rs/v0.4/rocket_contrib/json/index.html
|
|
||||||
|
|
||||||
- the hostname of the computer serving the response
|
|
||||||
- the process ID of the HTTP service
|
|
||||||
- the uptime of the system in seconds
|
|
||||||
|
|
||||||
### Encoding things to JSON
|
|
||||||
|
|
||||||
For encoding things to JSON, we will be using [serde][serde]. We will need to
|
|
||||||
add serde as a dependency. Open `Cargo.toml` and put the following lines in it:
|
|
||||||
|
|
||||||
[serde]: https://serde.rs/
|
|
||||||
|
|
||||||
```toml
|
|
||||||
[dependencies]
|
|
||||||
serde_json = "1.0"
|
|
||||||
serde = { version = "1.0", features = ["derive"] }
|
|
||||||
```
|
|
||||||
|
|
||||||
This lets us use `#[derive(Serialize, Deserialize)]` on our Rust structs, which
|
|
||||||
will allow us to automate away the JSON generation code _at compile time_. For
|
|
||||||
more information about derivation in Rust, see [here][rustderive].
|
|
||||||
|
|
||||||
[rustderive]: https://doc.rust-lang.org/rust-by-example/trait/derive.html
|
|
||||||
|
|
||||||
Let's define the data we will send back to the client using a [struct][ruststruct].
|
|
||||||
|
|
||||||
[ruststruct]: https://doc.rust-lang.org/rust-by-example/custom_types/structs.html
|
|
||||||
|
|
||||||
```rust
|
|
||||||
use serde::*;
|
|
||||||
|
|
||||||
/// Host information structure returned at /hostinfo
|
|
||||||
#[derive(Serialize, Debug)]
|
|
||||||
struct HostInfo {
|
|
||||||
hostname: String,
|
|
||||||
pid: u32,
|
|
||||||
uptime: u64,
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
To implement this call, we will need another few dependencies in the `Cargo.toml`
|
|
||||||
file. We will use [gethostname][gethostname] to get the hostname of the machine
|
|
||||||
and [psutil][psutil] to get the uptime of the machine. Put the following below
|
|
||||||
the `serde` dependency line:
|
|
||||||
|
|
||||||
[gethostname]: https://crates.io/crates/gethostname
|
|
||||||
[psutil]: https://crates.io/crates/psutil
|
|
||||||
|
|
||||||
```toml
|
|
||||||
gethostname = "0.2.1"
|
|
||||||
psutil = "3.0.1"
|
|
||||||
```
|
|
||||||
|
|
||||||
Finally, we will need to enable Rocket's JSON support. Put the following at the
|
|
||||||
end of your `Cargo.toml` file:
|
|
||||||
|
|
||||||
```toml
|
|
||||||
[dependencies.rocket_contrib]
|
|
||||||
version = "0.4.4"
|
|
||||||
default-features = false
|
|
||||||
features = ["json"]
|
|
||||||
```
|
|
||||||
|
|
||||||
Now we can implement the `/hostinfo` route:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
/// Create route /hostinfo that returns information about the host serving this
|
|
||||||
/// page.
|
|
||||||
#[get("/hostinfo")]
|
|
||||||
fn hostinfo() -> Json<HostInfo> {
|
|
||||||
// gets the current machine hostname or "unknown" if the hostname doesn't
|
|
||||||
// parse into UTF-8 (very unlikely)
|
|
||||||
let hostname = gethostname::gethostname()
|
|
||||||
.into_string()
|
|
||||||
.or(|_| "unknown".to_string())
|
|
||||||
.unwrap();
|
|
||||||
|
|
||||||
Json(HostInfo{
|
|
||||||
hostname: hostname,
|
|
||||||
pid: std::process::id(),
|
|
||||||
uptime: psutil::host::uptime()
|
|
||||||
.unwrap() // normally this is a bad idea, but this code is
|
|
||||||
// very unlikely to fail.
|
|
||||||
.as_secs(),
|
|
||||||
})
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
And then register it in the main function:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
fn main() {
|
|
||||||
rocket::ignite()
|
|
||||||
.mount("/", routes![index, hostinfo])
|
|
||||||
.launch();
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
Now rebuild the project and run the server:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ cargo build
|
|
||||||
$ ./target/debug/helloworld
|
|
||||||
```
|
|
||||||
|
|
||||||
And in another terminal test it with `curl`:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ curl http://127.0.0.1:8000
|
|
||||||
{"hostname":"shachi","pid":4291,"uptime":13641}
|
|
||||||
```
|
|
||||||
|
|
||||||
You can use a similar process for any kind of other route.
|
|
||||||
|
|
||||||
## OpenAPI specifications
|
|
||||||
|
|
||||||
[OpenAPI][openapi] is a common specification format for describing API routes.
|
|
||||||
This allows users of the API to automatically generate valid clients for them.
|
|
||||||
Writing these by hand can be tedious, so let's pass that work off to the
|
|
||||||
compiler using [okapi][okapi].
|
|
||||||
|
|
||||||
[openapi]: https://swagger.io/docs/specification/about/
|
|
||||||
[okapi]: https://github.com/GREsau/okapi
|
|
||||||
|
|
||||||
Add the following line to your `Cargo.toml` file in the `[dependencies]` block:
|
|
||||||
|
|
||||||
```toml
|
|
||||||
rocket_okapi = "0.3.6"
|
|
||||||
schemars = "0.6"
|
|
||||||
okapi = { version = "0.3", features = ["derive_json_schema"] }
|
|
||||||
```
|
|
||||||
|
|
||||||
This will allow us to generate OpenAPI specifications from Rocket routes and the
|
|
||||||
types in them. Let's import the rocket_okapi macros and use them:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
// Import OpenAPI macros
|
|
||||||
#[macro_use]
|
|
||||||
extern crate rocket_okapi;
|
|
||||||
|
|
||||||
use rocket_okapi::JsonSchema;
|
|
||||||
```
|
|
||||||
|
|
||||||
We need to add JSON schema generation abilities to `HostInfo`. Change:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
#[derive(Serialize, Debug)]
|
|
||||||
```
|
|
||||||
|
|
||||||
to
|
|
||||||
|
|
||||||
```rust
|
|
||||||
#[derive(Serialize, JsonSchema, Debug)]
|
|
||||||
```
|
|
||||||
|
|
||||||
to generate the OpenAPI code for our type.
|
|
||||||
|
|
||||||
Next we can add the `/hostinfo` route to the OpenAPI schema:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
/// Create route /hostinfo that returns information about the host serving this
|
|
||||||
/// page.
|
|
||||||
#[openapi]
|
|
||||||
#[get("/hostinfo")]
|
|
||||||
fn hostinfo() -> Json<HostInfo> {
|
|
||||||
// ...
|
|
||||||
```
|
|
||||||
|
|
||||||
Also add the index route to the OpenAPI schema:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
/// Create route / that returns "Hello, world!"
|
|
||||||
#[openapi]
|
|
||||||
#[get("/")]
|
|
||||||
fn index() -> &'static str {
|
|
||||||
"Hello, world!"
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
And finally update the main function to use openapi:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
fn main() {
|
|
||||||
rocket::ignite()
|
|
||||||
.mount("/", routes_with_openapi![index, hostinfo])
|
|
||||||
.launch();
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
Then rebuild it and run the server:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ cargo build
|
|
||||||
$ ./target/debug/helloworld
|
|
||||||
```
|
|
||||||
|
|
||||||
And then in another terminal:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ curl http://127.0.0.1:8000/openapi.json
|
|
||||||
```
|
|
||||||
|
|
||||||
This should return a large JSON object that describes all of the HTTP routes and
|
|
||||||
the data they return. To see this visually, change main to this:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
use rocket_okapi::swagger_ui::{make_swagger_ui, SwaggerUIConfig};
|
|
||||||
|
|
||||||
fn main() {
|
|
||||||
rocket::ignite()
|
|
||||||
.mount("/", routes_with_openapi![index, hostinfo])
|
|
||||||
.mount(
|
|
||||||
"/swagger-ui/",
|
|
||||||
make_swagger_ui(&SwaggerUIConfig {
|
|
||||||
url: Some("../openapi.json".to_owned()),
|
|
||||||
urls: None,
|
|
||||||
}),
|
|
||||||
)
|
|
||||||
.launch();
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
Then rebuild and run the service:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ cargo build
|
|
||||||
$ ./target/debug/helloworld
|
|
||||||
```
|
|
||||||
|
|
||||||
And [open the swagger UI](http://127.0.0.1:8000/swagger-ui/) in your favorite
|
|
||||||
browser. This will show you a graphical display of all of the routes and the
|
|
||||||
data types in your service. For an example, see
|
|
||||||
[here](https://printerfacts.cetacean.club/swagger-ui/index.html).
|
|
||||||
|
|
||||||
## Error responses
|
|
||||||
|
|
||||||
Earlier in the /hostinfo route we glossed over error handling. Let's correct
|
|
||||||
this using the [okapi error type][okapierror]. Let's use the
|
|
||||||
[OpenAPIError][okapierror] type in the helloworld function:
|
|
||||||
|
|
||||||
[okapierror]: https://docs.rs/rocket_okapi/0.3.6/rocket_okapi/struct.OpenApiError.html
|
|
||||||
|
|
||||||
```rust
|
|
||||||
/// Create route /hostinfo that returns information about the host serving
|
|
||||||
/// this page.
|
|
||||||
#[openapi]
|
|
||||||
#[get("/hostinfo")]
|
|
||||||
fn hostinfo() -> Result<Json<HostInfo>> {
|
|
||||||
match gethostname::gethostname().into_string() {
|
|
||||||
Ok(hostname) => Ok(Json(HostInfo {
|
|
||||||
hostname: hostname,
|
|
||||||
pid: std::process::id(),
|
|
||||||
uptime: psutil::host::uptime().unwrap().as_secs(),
|
|
||||||
})),
|
|
||||||
Err(_) => Err(OpenApiError::new(format!(
|
|
||||||
"hostname does not parse as UTF-8"
|
|
||||||
))),
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
When the `into_string` operation fails (because the hostname is somehow invalid
|
|
||||||
UTF-8), this will result in a non-200 response with the `"hostname does not parse
|
|
||||||
as UTF-8"` message.
|
|
||||||
|
|
||||||
## Shipping it in a docker image
|
|
||||||
|
|
||||||
Many deployment systems use [Docker][docker] to describe a program's environment
|
|
||||||
and dependencies. Create a `Dockerfile` with the following contents:
|
|
||||||
|
|
||||||
```Dockerfile
|
|
||||||
# Use the minimal image
|
|
||||||
FROM rustlang/rust:nightly-slim AS build
|
|
||||||
|
|
||||||
# Where we will build the program
|
|
||||||
WORKDIR /src/helloworld
|
|
||||||
|
|
||||||
# Copy source code into the container
|
|
||||||
COPY . .
|
|
||||||
|
|
||||||
# Build the program in release mode
|
|
||||||
RUN cargo build --release
|
|
||||||
|
|
||||||
# Create the runtime image
|
|
||||||
FROM ubuntu:18.04
|
|
||||||
|
|
||||||
# Copy the compiled service binary
|
|
||||||
COPY --from=build /src/helloworld/target/release/helloworld /usr/local/bin/helloworld
|
|
||||||
|
|
||||||
# Start the helloworld service on container boot
|
|
||||||
CMD ["usr/local/bin/helloworld"]
|
|
||||||
```
|
|
||||||
|
|
||||||
And then build it:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ docker build -t xena/helloworld .
|
|
||||||
```
|
|
||||||
|
|
||||||
And then run it:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ docker run --rm -itp 8000:8000 xena/helloworld
|
|
||||||
```
|
|
||||||
|
|
||||||
And in another terminal:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ curl http://127.0.0.1:8000
|
|
||||||
Hello, world!
|
|
||||||
```
|
|
||||||
|
|
||||||
From here you can do whatever you want with this service. You can deploy it to
|
|
||||||
Kubernetes with a manifest that would look something like [this][k8shack].
|
|
||||||
|
|
||||||
[k8shack]: https://clbin.com/zSPDs
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
This is how I start a new Rust project. I put all of the code described in this
|
|
||||||
post in [this GitHub repo][helloworldrepo] in case it helps. Have fun and be
|
|
||||||
well.
|
|
||||||
|
|
||||||
[helloworldrepo]: https://github.com/Xe/helloworld
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
For some "extra credit" tasks, try and see if you can do the following:
|
|
||||||
|
|
||||||
- Customize the environment of the container by following the [Rocket
|
|
||||||
configuration documentation](https://rocket.rs/v0.4/guide/configuration/) and
|
|
||||||
docker [environment variables][dockerenvvars]
|
|
||||||
- Use Rocket's [templates][rockettemplate] to make the host information show up
|
|
||||||
in HTML
|
|
||||||
- Add tests for the `/hostinfo` route
|
|
||||||
- Make a route that always returns errors, what does it look like?
|
|
||||||
|
|
||||||
[dockerenvvars]: https://docs.docker.com/engine/reference/builder/#env
|
|
||||||
[rockettemplate]: https://api.rocket.rs/v0.4/rocket_contrib/templates/index.html
|
|
||||||
|
|
||||||
Many thanks to [Coleman McFarland](https://coleman.codes/) for proofreading this
|
|
||||||
post.
|
|
||||||
|
|
@ -1,193 +0,0 @@
|
||||||
---
|
|
||||||
title: "How Mara Works"
|
|
||||||
date: 2020-09-30
|
|
||||||
tags:
|
|
||||||
- avif
|
|
||||||
- webp
|
|
||||||
- markdown
|
|
||||||
---
|
|
||||||
|
|
||||||
# How Mara Works
|
|
||||||
|
|
||||||
Recently I introduced Mara to this blog and I didn't explain much of the theory
|
|
||||||
and implementation behind them in order to proceed with the rest of the post.
|
|
||||||
There was actually a significant amount of engineering that went into
|
|
||||||
implementing Mara and I'd like to go into detail about this as well as explain
|
|
||||||
how I implemented them into this blog.
|
|
||||||
|
|
||||||
## Mara's Background
|
|
||||||
|
|
||||||
Mara is an anthropomorphic shark. They are nonbinary and go by they/she
|
|
||||||
pronouns. Mara enjoys hacking, swimming and is a Chaotic Good Rogue in the
|
|
||||||
tabletop games I've played her in. Mara was originally made to help test my
|
|
||||||
upcoming tabletop game The Source, and I have used them in a few solitaire
|
|
||||||
tabletop sessions (click
|
|
||||||
[here](http://cetacean.club/journal/mara-castle-charon.gmi) to read the results
|
|
||||||
of one of these).
|
|
||||||
|
|
||||||
[I use a hand-soldered <a href="https://www.ergodox.io/">Ergodox</a> with the <a
|
|
||||||
href="https://www.artofchording.com/">stenographer</a> layout so I can dab on
|
|
||||||
the haters at 200 words per minute!](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
## The Theory
|
|
||||||
|
|
||||||
My blogposts have a habit of getting long, wordy and sometimes pretty damn dry.
|
|
||||||
I notice that there are usually a few common threads in how this becomes the
|
|
||||||
case, so I want to do these three things to help keep things engaging.
|
|
||||||
|
|
||||||
1. I go into detail. A lot of detail. This can make paragraphs long and wordy
|
|
||||||
because there is legitimately a lot to cover. [fasterthanlime's Cool Bear's
|
|
||||||
Hot Tip](https://fasterthanli.me/articles/image-decay-as-a-service) is a good
|
|
||||||
way to help Amos focus on the core and let another character bring up the
|
|
||||||
finer details that may go off the core of the message.
|
|
||||||
2. I have been looking into how to integrate concepts from [The Socratic
|
|
||||||
method](https://en.wikipedia.org/wiki/Socratic_method) into my posts. The
|
|
||||||
Socratic method focuses on dialogue/questions and answers between
|
|
||||||
interlocutors as a way to explore a topic that can be dry or vague.
|
|
||||||
3. [Soatok's
|
|
||||||
blog](https://soatok.blog/2020/09/12/edutech-spyware-is-still-spyware-proctorio-edition/)
|
|
||||||
was an inspiration to this. Soatok dives into deep technical topics that can
|
|
||||||
feel like a slog, and inserts some stickers between paragraphs to help keep
|
|
||||||
things upbeat and lively.
|
|
||||||
|
|
||||||
I wanted to make a unique way to help break up walls of text using the concepts
|
|
||||||
of Cool Bear's Hot Tip and the Socratic method with some furry art sprinkled in
|
|
||||||
and I eventually arrived at Mara.
|
|
||||||
|
|
||||||
[Fun fact! My name was originally derived from a <a
|
|
||||||
href="https://en.wikipedia.org/wiki/Mara_(demon)">Buddhist conceptual demon of
|
|
||||||
forces antagonistic to enlightenment</a> which is deliciously ironic given that
|
|
||||||
my role is to help people understand things now.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
## How Mara is Implemented
|
|
||||||
|
|
||||||
I write my blogposts in
|
|
||||||
[Markdown](https://daringfireball.net/projects/markdown/), specifically a
|
|
||||||
dialect that has some niceties from [GitHub flavored
|
|
||||||
markdown](https://guides.github.com/features/mastering-markdown/#GitHub-flavored-markdown)
|
|
||||||
as parsed by [comrak](https://docs.rs/comrak). Mara's interjections are actually
|
|
||||||
specially formed links, such as this:
|
|
||||||
|
|
||||||
[Hi! I am saying something!](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
```markdown
|
|
||||||
[Hi! I am saying something!](conversation://Mara/hacker)
|
|
||||||
```
|
|
||||||
|
|
||||||
Notice how the destination URL doesn't actually exist. It's actually intercepted
|
|
||||||
in my [markdown parsing
|
|
||||||
function](https://github.com/Xe/site/blob/b540631792493169bd41f489c18b7369159d12a9/src/app/markdown.rs#L8)
|
|
||||||
and then a [HTML
|
|
||||||
template](https://github.com/Xe/site/blob/b540631792493169bd41f489c18b7369159d12a9/templates/mara.rs.html#L1)
|
|
||||||
is used to create the divs that make up the image and conversation bits. I have
|
|
||||||
intentionally left this open so I can add more characters in the future. I may
|
|
||||||
end up making some stickers for myself so I can reply to Mara a-la [this
|
|
||||||
blogpost by
|
|
||||||
fasterthanlime](https://fasterthanli.me/articles/so-you-want-to-live-reload-rust)
|
|
||||||
(search for "What's with the @@GLIBC_2.2.5 suffixes?"). The syntax of the URL is
|
|
||||||
as follows:
|
|
||||||
|
|
||||||
```
|
|
||||||
conversation://<character>/<mood>[?reply]
|
|
||||||
```
|
|
||||||
|
|
||||||
This will then fetch the images off of my CDN hosted by CloudFlare. However if
|
|
||||||
you are using Tor to view my site, this may result in not being able to see the
|
|
||||||
images. I am working on ways to solve this. Please bear with me, this stuff is
|
|
||||||
hard.
|
|
||||||
|
|
||||||
You may have noticed that Mara sometimes has links inside her dialogue.
|
|
||||||
Understandably, this is something that vanilla markdown does not support.
|
|
||||||
However, I enabled putting raw HTML in my markdown which lets this work anyways!
|
|
||||||
Consider this:
|
|
||||||
|
|
||||||
[My art was drawn by <a
|
|
||||||
href="https://selic.re">Selicre</a>!](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
In the markdown source, that actually looks like this:
|
|
||||||
|
|
||||||
```markdown
|
|
||||||
[My art was drawn by <a href="https://selic.re">Selicre</a>!](conversation://Mara/hacker)
|
|
||||||
```
|
|
||||||
|
|
||||||
This is honestly one of my favorite parts of how this is implemented, though
|
|
||||||
others I have shown this to say it's kind of terrifying.
|
|
||||||
|
|
||||||
### The `<picture>` Element and Image Formats
|
|
||||||
|
|
||||||
Something you might notice about the HTML template is that I use the
|
|
||||||
[`<picture>`](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/picture)
|
|
||||||
element like this:
|
|
||||||
|
|
||||||
```html
|
|
||||||
<picture>
|
|
||||||
<source srcset="https://cdn.christine.website/file/christine-static/stickers/@character.to_lowercase()/@(mood).avif" type="image/avif">
|
|
||||||
<source srcset="https://cdn.christine.website/file/christine-static/stickers/@character.to_lowercase()/@(mood).webp" type="image/webp">
|
|
||||||
<img src="https://cdn.christine.website/file/christine-static/stickers/@character.to_lowercase()/@(mood).png" alt="@character is @mood">
|
|
||||||
</picture>
|
|
||||||
```
|
|
||||||
|
|
||||||
The `<picture>` element allows me to specify multiple versions of the stickers
|
|
||||||
and have your browser pick the image format that it supports. It is also fully
|
|
||||||
backwards compatible with browsers that do not support `<picture>` and in those
|
|
||||||
cases you will see the fallback image in .png format. I went into a lot of
|
|
||||||
detail about this in [a twitter
|
|
||||||
thread](https://twitter.com/theprincessxena/status/1310358201842401281?s=21),
|
|
||||||
but in short here are how each of the formats looks next to its filesize
|
|
||||||
information:
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
The
|
|
||||||
[avif](https://reachlightspeed.com/blog/using-the-new-high-performance-avif-image-format-on-the-web-today/)
|
|
||||||
version does have the ugliest quality when blown up, however consider how small
|
|
||||||
these stickers will appear on the webpages:
|
|
||||||
|
|
||||||
[This is how big the stickers will appear, or is it?](conversation://Mara/hmm)
|
|
||||||
|
|
||||||
At these sizes most people will not notice any lingering artifacts unless they
|
|
||||||
look closely. However at about 5-6 kilobytes per image I think the smaller
|
|
||||||
filesize greatly wins out. This helps keep page loads fast, which is something I
|
|
||||||
want to optimize for as it makes people think my website loads quickly.
|
|
||||||
|
|
||||||
I go into a lot more detail on the twitter thread, but the commands I use to get
|
|
||||||
the webp and avif versions of the stickers are as follows:
|
|
||||||
|
|
||||||
```shell
|
|
||||||
#!/bin/sh
|
|
||||||
|
|
||||||
cwebp \
|
|
||||||
$1.png \
|
|
||||||
-o $1.webp
|
|
||||||
avifenc \
|
|
||||||
$1.png \
|
|
||||||
-o $1.avif \
|
|
||||||
-s 0 \
|
|
||||||
-d 8 \
|
|
||||||
--min 48 \
|
|
||||||
--max 48 \
|
|
||||||
--minalpha 48 \
|
|
||||||
--maxalpha 48
|
|
||||||
```
|
|
||||||
|
|
||||||
I plan to automate this further in the future, but for the scale I am at this
|
|
||||||
works fine. These stickers are then uploaded to my cloud storage bucket and
|
|
||||||
CloudFlare provides a CDN for them so they can load very quickly.
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
Anyways, this is how Mara is implemented and some of the challenges that went
|
|
||||||
into developing them as a feature (while leaving the door open for other
|
|
||||||
characters in the future). Mara is here to stay and I have gotten a lot of
|
|
||||||
positive feedback about her.
|
|
||||||
|
|
||||||
As a side note, for those of you that are not amused that I am choosing to have
|
|
||||||
Mara (and consequentially furry art in general) as a site feature, I can only
|
|
||||||
hope that you can learn to respect that as an independent blogger I am free to
|
|
||||||
implement my blog (and the content that I am choosing to provide _FOR FREE_ even
|
|
||||||
though I've gotten requests to make it paid content) as I see fit. Further
|
|
||||||
complaints will only increase the amount of furry art in future posts.
|
|
||||||
|
|
||||||
Be well all.
|
|
||||||
|
|
@ -1,437 +0,0 @@
|
||||||
---
|
|
||||||
title: I was Wrong about Nix
|
|
||||||
date: 2020-02-10
|
|
||||||
tags:
|
|
||||||
- nix
|
|
||||||
- witchcraft
|
|
||||||
---
|
|
||||||
|
|
||||||
# I was Wrong about Nix
|
|
||||||
|
|
||||||
From time to time, I am outright wrong on my blog. This is one of those times.
|
|
||||||
In my [last post about Nix][nixpost], I didn't see the light yet. I think I do
|
|
||||||
now, and I'm going to attempt to clarify below.
|
|
||||||
|
|
||||||
[nixpost]: https://christine.website/blog/thoughts-on-nix-2020-01-28
|
|
||||||
|
|
||||||
Let's talk about a more simple scenario: writing a service in Go. This service
|
|
||||||
will depend on at least the following:
|
|
||||||
|
|
||||||
- A Go compiler to build the code into a binary
|
|
||||||
- An appropriate runtime to ensure the code will run successfully
|
|
||||||
- Any data files needed at runtime
|
|
||||||
|
|
||||||
A popular way to model this is with a Dockerfile. Here's the Dockerfile I use
|
|
||||||
for my website (the one you are reading right now):
|
|
||||||
|
|
||||||
```
|
|
||||||
FROM xena/go:1.13.6 AS build
|
|
||||||
ENV GOPROXY https://cache.greedo.xeserv.us
|
|
||||||
COPY . /site
|
|
||||||
WORKDIR /site
|
|
||||||
RUN CGO_ENABLED=0 go test -v ./...
|
|
||||||
RUN CGO_ENABLED=0 GOBIN=/root go install -v ./cmd/site
|
|
||||||
|
|
||||||
FROM xena/alpine
|
|
||||||
EXPOSE 5000
|
|
||||||
WORKDIR /site
|
|
||||||
COPY --from=build /root/site .
|
|
||||||
COPY ./static /site/static
|
|
||||||
COPY ./templates /site/templates
|
|
||||||
COPY ./blog /site/blog
|
|
||||||
COPY ./talks /site/talks
|
|
||||||
COPY ./gallery /site/gallery
|
|
||||||
COPY ./css /site/css
|
|
||||||
HEALTHCHECK CMD wget --spider http://127.0.0.1:5000/.within/health || exit 1
|
|
||||||
CMD ./site
|
|
||||||
```
|
|
||||||
|
|
||||||
This fetches the Go compiler from [an image I made][godockerfile], copies the
|
|
||||||
source code to the image, builds it (in a way that makes the resulting binary a
|
|
||||||
[static executable][staticbin]), and creates the runtime environment for it.
|
|
||||||
|
|
||||||
[godockerfile]: https://github.com/Xe/dockerfiles/blob/master/lang/go/Dockerfile
|
|
||||||
[staticbin]: https://oddcode.daveamit.com/2018/08/16/statically-compile-golang-binary/
|
|
||||||
|
|
||||||
Let's let it build and see how big the result is:
|
|
||||||
|
|
||||||
```
|
|
||||||
$ docker build -t xena/christinewebsite:example1 .
|
|
||||||
<output omitted>
|
|
||||||
$ docker images | grep xena
|
|
||||||
xena/christinewebsite example1 4b8ee64969e8 24 seconds ago 111MB
|
|
||||||
```
|
|
||||||
|
|
||||||
Investigating this image with [dive][dive], we see the following:
|
|
||||||
|
|
||||||
[dive]: https://github.com/wagoodman/dive
|
|
||||||
|
|
||||||
- The package manager is included in the image
|
|
||||||
- The package manager's database is included in the image
|
|
||||||
- An entire copy of the C library is included in the image (even though the
|
|
||||||
binary was _statically linked_ to specifically avoid this)
|
|
||||||
- Most of the files in the docker image are unrelated to my website's
|
|
||||||
functionality and are involved with the normal functioning of Linux systems
|
|
||||||
|
|
||||||
Granted, [Alpine Linux][alpine] does a good job at keeping this chaff to a
|
|
||||||
minimum, but it is still there, still needs to be updated (causing all of my
|
|
||||||
docker images to be rebuilt and applications to be redeployed) and still takes
|
|
||||||
up space in transfer quotas and on the disk.
|
|
||||||
|
|
||||||
[alpine]: https://alpinelinux.org
|
|
||||||
|
|
||||||
Let's compare this to the same build process but done with Nix. My Nix setup is
|
|
||||||
done in a few phases. First I use [niv][niv] to manage some dependencies a-la
|
|
||||||
git submodules that don't hate you:
|
|
||||||
|
|
||||||
[niv]: https://github.com/nmattia/niv
|
|
||||||
|
|
||||||
```
|
|
||||||
$ nix-shell -p niv
|
|
||||||
[nix-shel]$ niv init
|
|
||||||
<writes nix/*>
|
|
||||||
```
|
|
||||||
|
|
||||||
Now I add the tool [vgo2nix][vgo2nix] in niv:
|
|
||||||
|
|
||||||
[vgo2nix]: https://github.com/adisbladis/vgo2nix
|
|
||||||
|
|
||||||
```
|
|
||||||
[nix-shell]$ niv add adisbladis/vgo2nix
|
|
||||||
```
|
|
||||||
|
|
||||||
And I can use it in my shell.nix:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
let
|
|
||||||
pkgs = import <nixpkgs> { };
|
|
||||||
sources = import ./nix/sources.nix;
|
|
||||||
vgo2nix = (import sources.vgo2nix { });
|
|
||||||
in pkgs.mkShell { buildInputs = [ pkgs.go pkgs.niv vgo2nix ]; }
|
|
||||||
```
|
|
||||||
|
|
||||||
And then relaunch nix-shell with vgo2nix installed and convert my [go modules][gomod]
|
|
||||||
dependencies to a Nix expression:
|
|
||||||
|
|
||||||
[gomod]: https://github.com/golang/go/wiki/Modules
|
|
||||||
|
|
||||||
```
|
|
||||||
$ nix-shell
|
|
||||||
<some work is done to compile things, etc>
|
|
||||||
[nix-shell]$ vgo2nix
|
|
||||||
<writes deps.nix>
|
|
||||||
```
|
|
||||||
|
|
||||||
Now that I have this, I can follow the [buildGoPackage
|
|
||||||
instructions][buildgopackage] from the upstream nixpkgs documentation and create
|
|
||||||
`site.nix`:
|
|
||||||
|
|
||||||
[buildgopackage]: https://nixos.org/nixpkgs/manual/#ssec-go-legacy
|
|
||||||
|
|
||||||
```
|
|
||||||
{ pkgs ? import <nixpkgs> {} }:
|
|
||||||
with pkgs;
|
|
||||||
|
|
||||||
assert lib.versionAtLeast go.version "1.13";
|
|
||||||
|
|
||||||
buildGoPackage rec {
|
|
||||||
name = "christinewebsite-HEAD";
|
|
||||||
version = "latest";
|
|
||||||
goPackagePath = "christine.website";
|
|
||||||
src = ./.;
|
|
||||||
|
|
||||||
goDeps = ./deps.nix;
|
|
||||||
allowGoReference = false;
|
|
||||||
preBuild = ''
|
|
||||||
export CGO_ENABLED=0
|
|
||||||
buildFlagsArray+=(-pkgdir "$TMPDIR")
|
|
||||||
'';
|
|
||||||
|
|
||||||
postInstall = ''
|
|
||||||
cp -rf $src/blog $bin/blog
|
|
||||||
cp -rf $src/css $bin/css
|
|
||||||
cp -rf $src/gallery $bin/gallery
|
|
||||||
cp -rf $src/static $bin/static
|
|
||||||
cp -rf $src/talks $bin/talks
|
|
||||||
cp -rf $src/templates $bin/templates
|
|
||||||
'';
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
And this will do the following:
|
|
||||||
|
|
||||||
- Download all of the needed dependencies and place them in the system-level Nix
|
|
||||||
store so that they are not downloaded again
|
|
||||||
- Set the `CGO_ENABLED` environment variable to `0` so the Go compiler emits a
|
|
||||||
static binary
|
|
||||||
- Copy all of the needed files to the right places so that the blog, gallery and
|
|
||||||
talks features can load all of their data
|
|
||||||
- Depend on nothing other than a working system at runtime
|
|
||||||
|
|
||||||
This Nix build manifest doesn't just work on Linux. It works on my mac too. The
|
|
||||||
dockerfile approach works great for Linux boxes, but (unlike what the me of a
|
|
||||||
decade ago would have hoped) the whole world just doesn't run Linux on their
|
|
||||||
desktops. The real world has multiple OSes and Nix allows me to compensate.
|
|
||||||
|
|
||||||
So, now that we have a working _cross-platform_ build, let's see how big it
|
|
||||||
comes out as:
|
|
||||||
|
|
||||||
```
|
|
||||||
$ readlink ./result-bin
|
|
||||||
/nix/store/ayvafpvn763wwdzwjzvix3mizayyblx5-christinewebsite-HEAD-bin
|
|
||||||
$ du -hs result-bin/
|
|
||||||
89M ./result-bin/
|
|
||||||
$ du -hs result-bin/
|
|
||||||
11M ./result-bin/bin
|
|
||||||
888K ./result-bin/blog
|
|
||||||
40K ./result-bin/css
|
|
||||||
44K ./result-bin/gallery
|
|
||||||
77M ./result-bin/static
|
|
||||||
28K ./result-bin/talks
|
|
||||||
64K ./result-bin/templates
|
|
||||||
```
|
|
||||||
|
|
||||||
As expected, most of the build results are static assets. I have a lot of larger
|
|
||||||
static assets including an entire copy of TempleOS, so this isn't too
|
|
||||||
surprising. Let's compare this to on the mac:
|
|
||||||
|
|
||||||
```
|
|
||||||
$ du -hs result-bin/
|
|
||||||
91M result-bin/
|
|
||||||
$ du -hs result-bin/*
|
|
||||||
14M result-bin/bin
|
|
||||||
872K result-bin/blog
|
|
||||||
36K result-bin/css
|
|
||||||
40K result-bin/gallery
|
|
||||||
77M result-bin/static
|
|
||||||
24K result-bin/talks
|
|
||||||
60K result-bin/templates
|
|
||||||
```
|
|
||||||
|
|
||||||
Which is damn-near identical save some macOS specific crud that Go has to deal
|
|
||||||
with.
|
|
||||||
|
|
||||||
I mentioned this is used for Docker builds, so let's make `docker.nix`:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
{ system ? builtins.currentSystem }:
|
|
||||||
|
|
||||||
let
|
|
||||||
pkgs = import <nixpkgs> { inherit system; };
|
|
||||||
|
|
||||||
callPackage = pkgs.lib.callPackageWith pkgs;
|
|
||||||
|
|
||||||
site = callPackage ./site.nix { };
|
|
||||||
|
|
||||||
dockerImage = pkg:
|
|
||||||
pkgs.dockerTools.buildImage {
|
|
||||||
name = "xena/christinewebsite";
|
|
||||||
tag = pkg.version;
|
|
||||||
|
|
||||||
contents = [ pkg ];
|
|
||||||
|
|
||||||
config = {
|
|
||||||
Cmd = [ "/bin/site" ];
|
|
||||||
WorkingDir = "/";
|
|
||||||
};
|
|
||||||
};
|
|
||||||
|
|
||||||
in dockerImage site
|
|
||||||
```
|
|
||||||
|
|
||||||
And then build it:
|
|
||||||
|
|
||||||
```
|
|
||||||
$ nix-build docker.nix
|
|
||||||
<output omitted>
|
|
||||||
$ docker load -i result
|
|
||||||
c6b1d6ce7549: Loading layer [==================================================>] 95.81MB/95.81MB
|
|
||||||
$ docker images | grep xena
|
|
||||||
xena/christinewebsite latest 0d1ccd676af8 50 years ago 94.6MB
|
|
||||||
```
|
|
||||||
|
|
||||||
And the output is 16 megabytes smaller.
|
|
||||||
|
|
||||||
The image age might look weird at first, but it's part of the reproducibility
|
|
||||||
Nix offers. The date an image was built is something that can change with time
|
|
||||||
and is actually a part of the resulting file. This means that an image built one
|
|
||||||
second after another has a different cryptographic hash. It helpfully pins all
|
|
||||||
images to Unix timestamp 0, which just happens to be about 50 years ago.
|
|
||||||
|
|
||||||
Looking into the image with `dive`, the only packages installed into this image
|
|
||||||
are:
|
|
||||||
|
|
||||||
- The website and all of its static content goodness
|
|
||||||
- IANA portmaps that Go depends on as part of the [`net`][gonet] package
|
|
||||||
- The standard list of [MIME types][mimetypes] that the [`net/http`][gonethttp]
|
|
||||||
package needs
|
|
||||||
- Time zone data that the [`time`][gotime] package needs
|
|
||||||
|
|
||||||
[gonet]: https://godoc.org/net
|
|
||||||
[gonethttp]: https://godoc.org/net/http
|
|
||||||
[gotime]: https://godoc.org/time
|
|
||||||
|
|
||||||
And that's it. This is _fantastic_. Nearly all of the disk usage has been
|
|
||||||
eliminated. If someone manages to trick my website into executing code, that
|
|
||||||
attacker cannot do anything but run more copies of my website (that will
|
|
||||||
immediately fail and die because the port is already allocated).
|
|
||||||
|
|
||||||
This strategy pans out to more complicated projects too. Consider a case where a
|
|
||||||
frontend and backend need to be built and deployed as a unit. Let's create a new
|
|
||||||
setup using niv:
|
|
||||||
|
|
||||||
```
|
|
||||||
$ niv init
|
|
||||||
```
|
|
||||||
|
|
||||||
Since we are using [Elm][elm] for this complicated project, let's add the
|
|
||||||
[elm2nix][elm2nix] tool so that our Elm dependencies have repeatable builds, and
|
|
||||||
[gruvbox-css][gcss] for some nice simple CSS:
|
|
||||||
|
|
||||||
[elm]: https://elm-lang.org
|
|
||||||
[elm2nix]: https://github.com/cachix/elm2nix
|
|
||||||
[gcss]: https://github.com/Xe/gruvbox-css
|
|
||||||
|
|
||||||
```
|
|
||||||
$ niv add cachix/elm2nix
|
|
||||||
$ niv add Xe/gruvbox-css
|
|
||||||
```
|
|
||||||
|
|
||||||
And then add it to our `shell.nix`:
|
|
||||||
|
|
||||||
```
|
|
||||||
let
|
|
||||||
pkgs = import <nixpkgs> {};
|
|
||||||
sources = import ./nix/sources.nix;
|
|
||||||
elm2nix = (import sources.elm2nix { });
|
|
||||||
in
|
|
||||||
pkgs.mkShell {
|
|
||||||
buildInputs = [
|
|
||||||
pkgs.elmPackages.elm
|
|
||||||
pkgs.elmPackages.elm-format
|
|
||||||
elm2nix
|
|
||||||
];
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
And then enter `nix-shell` to create the Elm boilerplate:
|
|
||||||
|
|
||||||
```
|
|
||||||
$ nix-shell
|
|
||||||
[nix-shell]$ cd frontend
|
|
||||||
[nix-shell:frontend]$ elm2nix init > default.nix
|
|
||||||
[nix-shell:frontend]$ elm2nix convert > elm-srcs.nix
|
|
||||||
[nix-shell:frontend]$ elm2nix snapshot
|
|
||||||
```
|
|
||||||
|
|
||||||
And then we can edit the generated Nix expression:
|
|
||||||
|
|
||||||
```
|
|
||||||
let
|
|
||||||
sources = import ./nix/sources.nix;
|
|
||||||
gcss = (import sources.gruvbox-css { });
|
|
||||||
# ...
|
|
||||||
buildInputs = [ elmPackages.elm gcss ]
|
|
||||||
++ lib.optional outputJavaScript nodePackages_10_x.uglify-js;
|
|
||||||
# ...
|
|
||||||
cp -rf ${gcss}/gruvbox.css $out/public
|
|
||||||
cp -rf $src/public/* $out/public/
|
|
||||||
# ...
|
|
||||||
outputJavaScript = true;
|
|
||||||
```
|
|
||||||
|
|
||||||
And then test it with `nix-build`:
|
|
||||||
|
|
||||||
```
|
|
||||||
$ nix-build
|
|
||||||
<output omitted>
|
|
||||||
```
|
|
||||||
|
|
||||||
And now create a `name.nix` for your Go service like I did above. The real
|
|
||||||
magic comes from the `docker.nix` file:
|
|
||||||
|
|
||||||
```
|
|
||||||
{ system ? builtins.currentSystem }:
|
|
||||||
|
|
||||||
let
|
|
||||||
pkgs = import <nixpkgs> { inherit system; };
|
|
||||||
sources = import ./nix/sources.nix;
|
|
||||||
backend = import ./backend.nix { };
|
|
||||||
frontend = import ./frontend/default.nix { };
|
|
||||||
in
|
|
||||||
|
|
||||||
pkgs.dockerTools.buildImage {
|
|
||||||
name = "xena/complicatedservice";
|
|
||||||
tag = "latest";
|
|
||||||
|
|
||||||
contents = [ backend frontend ];
|
|
||||||
|
|
||||||
config = {
|
|
||||||
Cmd = [ "/bin/backend" ];
|
|
||||||
WorkingDir = "/public";
|
|
||||||
};
|
|
||||||
};
|
|
||||||
```
|
|
||||||
|
|
||||||
Now both your backend and frontend services are built with the dependencies in
|
|
||||||
the Nix store and shipped as a repeatable Docker image.
|
|
||||||
|
|
||||||
Sometimes it might be useful to ship the dependencies to a service like
|
|
||||||
[Cachix][cachix] to help speed up builds.
|
|
||||||
|
|
||||||
[cachix]: https://cachix.org
|
|
||||||
|
|
||||||
You can install the cachix tool like this:
|
|
||||||
|
|
||||||
```
|
|
||||||
$ nix-env -iA cachix -f https://cachix.org/api/v1/install
|
|
||||||
```
|
|
||||||
|
|
||||||
And then follow the steps at [cachix.org][cachix] to create a new binary cache.
|
|
||||||
Let's assume you made a cache named `teddybear`. When you've created a new
|
|
||||||
cache, logged in with an API token and created a signing key, you can pipe
|
|
||||||
nix-build to the Cachix client like so:
|
|
||||||
|
|
||||||
```
|
|
||||||
$ nix-build | cachix push teddybear
|
|
||||||
```
|
|
||||||
|
|
||||||
And other people using that cache will benefit from your premade dependency and
|
|
||||||
binary downloads.
|
|
||||||
|
|
||||||
To use the cache somewhere, install the Cachix client and then run the
|
|
||||||
following:
|
|
||||||
|
|
||||||
```
|
|
||||||
$ cachix use teddybear
|
|
||||||
```
|
|
||||||
|
|
||||||
I've been able to use my Go, Elm, Rust and Haskell dependencies on other
|
|
||||||
machines using this. It's saved so much extra download time.
|
|
||||||
|
|
||||||
## tl;dr
|
|
||||||
|
|
||||||
I was wrong about Nix. It's actually quite good once you get past the
|
|
||||||
documentation being baroque and hard to read as a beginner. I'm going to try and
|
|
||||||
do what I can to get the documentation improved.
|
|
||||||
|
|
||||||
As far as getting started with Nix, I suggest following these posts:
|
|
||||||
|
|
||||||
- Nix Pills: https://nixos.org/nixos/nix-pills/
|
|
||||||
- Nix Shorts: https://github.com/justinwoo/nix-shorts
|
|
||||||
- NixOS: For Developers: https://myme.no/posts/2020-01-26-nixos-for-development.html
|
|
||||||
|
|
||||||
Also, I really suggest trying stuff as a vehicle to understand how things work.
|
|
||||||
I got really far by experimenting with getting [this Discord bot I am writing in
|
|
||||||
Rust][withinbot] working in Nix and have been very pleased with how it's turned
|
|
||||||
out. I don't need to use `rustup` anymore to manage my Rust compiler or the
|
|
||||||
language server. With a combination of [direnv][direnv] and [lorri][lorri], I
|
|
||||||
can avoid needing to set up language servers or the like _at all_. I can define
|
|
||||||
them as part of the _project environment_ and then trust the tools I build on
|
|
||||||
top of to take care of that for me.
|
|
||||||
|
|
||||||
[withinbot]: https://github.com/Xe/withinbot
|
|
||||||
[direnv]: https://direnv.net
|
|
||||||
[lorri]: https://github.com/target/lorri
|
|
||||||
|
|
||||||
Give Nix a try. It's worth at least that much in my opinion.
|
|
||||||
|
|
@ -1,93 +0,0 @@
|
||||||
---
|
|
||||||
title: Instant Pot Spaghetti
|
|
||||||
date: 2020-02-03
|
|
||||||
series: recipes
|
|
||||||
tags:
|
|
||||||
- instant-pot
|
|
||||||
---
|
|
||||||
|
|
||||||
# Instant Pot Spaghetti
|
|
||||||
|
|
||||||
This is based on [this recipe][source], but made only with things you can find
|
|
||||||
in Costco. My fiancé and I have made this at least weekly for the last 8 months
|
|
||||||
and we love how it turns out.
|
|
||||||
|
|
||||||
[source]: https://kristineskitchenblog.com/instant-pot-spaghetti/
|
|
||||||
|
|
||||||
## Recipe
|
|
||||||
|
|
||||||
### Ingredients
|
|
||||||
|
|
||||||
- 1/2 kg ground beef (pre-cooked, or see section on browning it)
|
|
||||||
- 3 1/4 cups water
|
|
||||||
- 2 teaspoons salt
|
|
||||||
- a small amount of pepper
|
|
||||||
- 4 heaping teaspoons of garlic
|
|
||||||
- 1/2 cup butter
|
|
||||||
- 1/4 kg spaghetti noodles
|
|
||||||
- 1 jar of pasta sauce (about 870ml)
|
|
||||||
|
|
||||||
If you want it to be more spicy, add more pepper. Too much can make it hard to
|
|
||||||
eat. Only experiment with the pepper amount after you've made this and decided
|
|
||||||
there's not enough pepper.
|
|
||||||
|
|
||||||
### Preparation
|
|
||||||
|
|
||||||
Put the ground beef in the instant pot. Put the water in the instant pot. Put
|
|
||||||
the salt in the instant pot. Put the pepper in the instant pot. Put the garlic
|
|
||||||
in the instant pot. Put the butter in the instant pot.
|
|
||||||
|
|
||||||
Stir for about 30 seconds, or until the garlic looks like it's distributed about
|
|
||||||
evenly in the pot.
|
|
||||||
|
|
||||||
Take the spaghetti noodles and break them in half. Place about a third of one
|
|
||||||
half one direction, the second third another, and the last yet another. Repeat
|
|
||||||
this for the other half of the pasta. This helps to not clump it together when
|
|
||||||
it's cooking.
|
|
||||||
|
|
||||||
Look at the package of spaghetti noodles. It should say something like "Ready in
|
|
||||||
X minutes" with a large number. Take that number and subtract two from it. If
|
|
||||||
you have a pasta that says it's cooked for 7 minutes, you will cook it for 5
|
|
||||||
minutes. If you have a pasta that says it's cooked for 9 minutes, you will cook
|
|
||||||
it for 7 minutes.
|
|
||||||
|
|
||||||
Put the lid on the instant pot, seal it and ensure the pressure release valve is
|
|
||||||
set to "sealing". Hit the "manual" button and select the number you figured out
|
|
||||||
above.
|
|
||||||
|
|
||||||
Leave the instant pot alone for 10 minutes after it is done. This lets the
|
|
||||||
pressure release naturally.
|
|
||||||
|
|
||||||
Use your serving utensil to open the pressure release valve. Stir and wait 3-5
|
|
||||||
minutes to serve. This makes 5 servings, but could be extended to more if you
|
|
||||||
carefully ration it.
|
|
||||||
|
|
||||||
Serve hot with salt or parmesan cheese.
|
|
||||||
|
|
||||||
## Browning Ground Beef
|
|
||||||
|
|
||||||
Browing ground beef is the act of cooking it all the way through so it is safe
|
|
||||||
to eat. It's called "browing" it because the ground beef will turn a grayish
|
|
||||||
brown when it is fully cooked.
|
|
||||||
|
|
||||||
### Ingredients
|
|
||||||
|
|
||||||
- Olive oil
|
|
||||||
- 1 teaspoon salt
|
|
||||||
- The ground beef you want to brown
|
|
||||||
|
|
||||||
### Preparation
|
|
||||||
|
|
||||||
Take the lid off of the instant pot. Cover the bottom of the pan in olive oil.
|
|
||||||
Sprinkle the salt over the olive oil. Place the ground beef in the instant pot
|
|
||||||
on top of the olive oil and salt.
|
|
||||||
|
|
||||||
Press the "sauté" button on your instant pot and use a spatula to break the
|
|
||||||
ground beef into smaller chunks while it warms up. Mix the ground beef while it
|
|
||||||
cooks. The goal is to make sure that all of the red parts turn grayish brown.
|
|
||||||
|
|
||||||
This will take anywhere from 5-10 minutes.
|
|
||||||
|
|
||||||
If you are using this ground beef for the above spaghetti recipe, you don't need
|
|
||||||
to remove it from the instant pot. You can store extra ground beef in the fridge
|
|
||||||
for use later.
|
|
||||||
|
|
@ -20,7 +20,9 @@ img {
|
||||||
}
|
}
|
||||||
</style>
|
</style>
|
||||||
|
|
||||||
|
<center>
|
||||||

|

|
||||||
|
</center>
|
||||||
|
|
||||||
- Go up a level to General
|
- Go up a level to General
|
||||||
- Select About
|
- Select About
|
||||||
|
|
@ -28,7 +30,9 @@ img {
|
||||||
- Each root that has been installed via a profile will be listed below the heading Enable Full Trust For Root Certificates
|
- Each root that has been installed via a profile will be listed below the heading Enable Full Trust For Root Certificates
|
||||||
- Users can toggle on/off trust for each root:
|
- Users can toggle on/off trust for each root:
|
||||||
|
|
||||||
|
<center>
|
||||||

|

|
||||||
|
</center>
|
||||||
|
|
||||||
Please understand that by doing this, users will potentially be vulnerable to a
|
Please understand that by doing this, users will potentially be vulnerable to a
|
||||||
[HTTPS man in the middle attack a-la Superfish](https://slate.com/technology/2015/02/lenovo-superfish-scandal-why-its-one-of-the-worst-consumer-computing-screw-ups-ever.html). Please ensure that you have appropriate measures in place to keep the signing key for the CA safe.
|
[HTTPS man in the middle attack a-la Superfish](https://slate.com/technology/2015/02/lenovo-superfish-scandal-why-its-one-of-the-worst-consumer-computing-screw-ups-ever.html). Please ensure that you have appropriate measures in place to keep the signing key for the CA safe.
|
||||||
|
|
|
||||||
|
|
@ -1,160 +0,0 @@
|
||||||
---
|
|
||||||
title: Kubernetes Pondering
|
|
||||||
date: 2020-12-31
|
|
||||||
tags:
|
|
||||||
- k8s
|
|
||||||
- kubernetes
|
|
||||||
- soyoustart
|
|
||||||
- kimsufi
|
|
||||||
- digitalocean
|
|
||||||
- vultr
|
|
||||||
---
|
|
||||||
|
|
||||||
# Kubernetes Pondering
|
|
||||||
|
|
||||||
Right now I am using a freight train to mail a letter when it comes to hosting
|
|
||||||
my web applications. If you are reading this post on the day it comes out, then
|
|
||||||
you are connected to one of a few replicas of my site code running across at
|
|
||||||
least 3 machines in my Kubernetes cluster. This certainly _works_, however it is
|
|
||||||
not very ergonomic and ends up being quite expensive.
|
|
||||||
|
|
||||||
I think I made a mistake when I decided to put my cards into Kubernetes for my
|
|
||||||
personal setup. It made sense at the time (I was trying to learn Kubernetes and
|
|
||||||
I am cursed into learning by doing), however I don't think it is really the best
|
|
||||||
choice available for my needs. I am not a large company. I am a single person
|
|
||||||
making things that are really targeted for myself. I would like to replace this
|
|
||||||
setup with something more at my scale. Here are a few options I have been
|
|
||||||
exploring combined with their pros and cons.
|
|
||||||
|
|
||||||
Here are the services I currently host on my Kubernetes cluster:
|
|
||||||
|
|
||||||
- [this site](/)
|
|
||||||
- [my git server](https://tulpa.dev)
|
|
||||||
- [hlang](https://h.christine.website)
|
|
||||||
- A few personal services that I've been meaning to consolidate
|
|
||||||
- The [olin demo](https://olin.within.website/)
|
|
||||||
- The venerable [printer facts server](https://printerfacts.cetacean.club)
|
|
||||||
- A few static websites
|
|
||||||
- An IRC server (`irc.within.website`)
|
|
||||||
|
|
||||||
My goal in evaluating other options is to reduce cost and complexity. Kubernetes
|
|
||||||
is a very complicated system and requires a lot of hand-holding and rejiggering
|
|
||||||
to make it do what you want. NixOS, on the other hand, is a lot simpler overall
|
|
||||||
and I would like to use it for running my services where I can.
|
|
||||||
|
|
||||||
Cost is a huge factor in this. My Kubernetes setup is a money pit. I want to
|
|
||||||
prioritize cost reduction as much as possible.
|
|
||||||
|
|
||||||
## Option 1: Do Nothing
|
|
||||||
|
|
||||||
I could do nothing about this and eat the complexity as a cost of having this
|
|
||||||
website and those other services online. However over the year or so I've been
|
|
||||||
using Kubernetes I've had to do a lot of hacking at it to get it to do what I
|
|
||||||
want.
|
|
||||||
|
|
||||||
I set up the cluster using Terraform and Helm 2. Helm 3 is the current
|
|
||||||
(backwards-incompatible) release, and all of the things that are managed by Helm
|
|
||||||
2 have resisted being upgraded to Helm 3.
|
|
||||||
|
|
||||||
I'm going to say something slightly controversial here, but YAML is a HORRIBLE
|
|
||||||
format for configuration. I can't trust myself to write unambiguous YAML. I have
|
|
||||||
to reference the spec constantly to make sure I don't have an accidental
|
|
||||||
Norway/Ontario bug. I have a Dhall package that takes away most of the pain,
|
|
||||||
however it's not flexible enough to describe the entire scope of what my
|
|
||||||
services need to do (IE: pinging Google/Bing to update their indexes on each
|
|
||||||
deploy), and I don't feel like putting in the time to make it that flexible.
|
|
||||||
|
|
||||||
[This is the regex for determining what is a valid boolean value in YAML:
|
|
||||||
`y|Y|yes|Yes|YES|n|N|no|No|NO|true|True|TRUE|false|False|FALSE|on|On|ON|off|Off|OFF`.
|
|
||||||
This can bite you eventually. See the <a
|
|
||||||
href="https://hitchdev.com/strictyaml/why/implicit-typing-removed/">Norway
|
|
||||||
Problem</a> for more information.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
I have a tor hidden service endpoint for a few of my services. I have to use an
|
|
||||||
[unmaintained tool](https://github.com/kragniz/tor-controller) to manage these
|
|
||||||
on Kubernetes. It works _today_, but the Kubernetes operator API could change at
|
|
||||||
any time (or the API this uses could be deprecated and removed without much
|
|
||||||
warning) and leave me in the dust.
|
|
||||||
|
|
||||||
I could live with all of this, however I don't really think it's the best idea
|
|
||||||
going forward. There's a bunch of services that I added on top of Kubernetes
|
|
||||||
that are dangerous to upgrade and very difficult (if not impossible) to
|
|
||||||
downgrade when something goes wrong during the upgrade.
|
|
||||||
|
|
||||||
One of the big things that I have with this setup that I would have to rebuild
|
|
||||||
in NixOS is the continuous deployment setup. However I've done that before and
|
|
||||||
it wouldn't really be that much of an issue to do it again.
|
|
||||||
|
|
||||||
NixOS fixes all the jank I mentioned above by making my specifications not have
|
|
||||||
to include the version numbers of everything the system already provides. You
|
|
||||||
can _actually trust the package repos to have up to date packages_. I don't
|
|
||||||
have to go around and bump the versions of shims and pray they work, because
|
|
||||||
with NixOS I don't need them anymore.
|
|
||||||
|
|
||||||
## Option 2: NixOS on top of SoYouStart or Kimsufi
|
|
||||||
|
|
||||||
This is a doable option. The main problem here would be doing the provision
|
|
||||||
step. SoYouStart and Kimsufi (both are offshoot/discount brands of OVH) have
|
|
||||||
very little in terms of customization of machine config. They work best when you
|
|
||||||
are using "normal" distributions like Ubuntu or CentOS and leave them be. I
|
|
||||||
would want to run NixOS on it and would have to do several trial and error runs
|
|
||||||
with a tool such as [nixos-infect](https://github.com/elitak/nixos-infect) to
|
|
||||||
assimilate the server into running NixOS.
|
|
||||||
|
|
||||||
With this option I would get the most storage out of any other option by far. 4
|
|
||||||
TB is a _lot_ of space. However, SoYouStart and Kimsufi run decade-old hardware
|
|
||||||
at best. I would end up paying a lot for very little in the CPU department. For
|
|
||||||
most things I am sure this would be fine, however some of my services can have
|
|
||||||
CPU needs that might exceed what second-generation Xeons can provide.
|
|
||||||
|
|
||||||
SoYouStart and Kimsufi have weird kernel versions though. The last SoYouStart
|
|
||||||
dedi I used ran Fedora and was gimped with a grsec kernel by default. I had to
|
|
||||||
end up writing [this gem of a systemd service on
|
|
||||||
boot](https://github.com/Xe/dotfiles/blob/master/ansible/roles/soyoustart/files/conditional-kexec.sh)
|
|
||||||
which did a [`kexec`](https://en.wikipedia.org/wiki/Kexec) to boot into a
|
|
||||||
non-gimped kernel on boot. It was a huge hack and somehow worked every time. I
|
|
||||||
was still afraid to reboot the machine though.
|
|
||||||
|
|
||||||
Sure is a lot of ram for the cost though.
|
|
||||||
|
|
||||||
## Option 3: NixOS on top of Digital Ocean
|
|
||||||
|
|
||||||
This shares most of the problems as the SoYouStart or Kimsufi nodes. However,
|
|
||||||
nixos-infect is known to have a higher success rate on Digital Ocean droplets.
|
|
||||||
It would be really nice if Digital Ocean let you upload arbitrary ISO files and
|
|
||||||
go from there, but that is apparently not the world we live in.
|
|
||||||
|
|
||||||
8 GB of ram would be _way more than enough_ for what I am doing with these
|
|
||||||
services.
|
|
||||||
|
|
||||||
## Option 4: NixOS on top of Vultr
|
|
||||||
|
|
||||||
Vultr is probably my top pick for this. You can upload an arbitrary ISO file,
|
|
||||||
kick off your VPS from it and install it like normal. I have a little shell
|
|
||||||
server shared between some friends built on top of such a Vultr node. It works
|
|
||||||
beautifully.
|
|
||||||
|
|
||||||
The fact that it has the same cost as the Digital Ocean droplet just adds to the
|
|
||||||
perfection of this option.
|
|
||||||
|
|
||||||
## Costs
|
|
||||||
|
|
||||||
Here is the cost table I've drawn up while comparing these options:
|
|
||||||
|
|
||||||
| Option | Ram | Disk | Cost per month | Hacks |
|
|
||||||
| :--------- | :----------------- | :------------------------------------ | :-------------- | :----------- |
|
|
||||||
| Do nothing | 6 GB (4 GB usable) | Not really usable, volumes cost extra | $60/month | Very Yes |
|
|
||||||
| SoYouStart | 32 GB | 2x2TB SAS | $40/month | Yes |
|
|
||||||
| Kimsufi | 32 GB | 2x2TB SAS | $35/month | Yes |
|
|
||||||
| Digital Ocean | 8 GB | 160 GB SSD | $40/month | On provision |
|
|
||||||
| Vultr | 8 GB | 160 GB SSD | $40/month | No |
|
|
||||||
|
|
||||||
I think I am going to go with the Vultr option. I will need to modernize some of
|
|
||||||
my services to support being deployed in NixOS in order to do this, however I
|
|
||||||
think that I will end up creating a more robust setup in the process. At least I
|
|
||||||
will create a setup that allows me to more easily maintain my own backups rather
|
|
||||||
than just relying on DigitalOcean snapshots and praying like I do with the
|
|
||||||
Kubernetes setup.
|
|
||||||
|
|
||||||
Thanks farcaller, Marbles, John Rinehart and others for reviewing this post
|
|
||||||
prior to it being published.
|
|
||||||
|
|
@ -1,54 +0,0 @@
|
||||||
---
|
|
||||||
title: kalama pali pi kulupu Kala
|
|
||||||
date: 2020-10-12
|
|
||||||
tags:
|
|
||||||
- 100DaysToOffload
|
|
||||||
---
|
|
||||||
|
|
||||||
# kalama pali pi kulupu Kala
|
|
||||||
|
|
||||||
I've wanted to write a novel for a while, and I think I've finally got a solid
|
|
||||||
idea for it. I want to write about the good guys winning against an oppressive
|
|
||||||
system. I've been letting the ideas and thoughts marinate in my heart for a long
|
|
||||||
time; these short stories are how I am exploring the world and other related
|
|
||||||
concepts. I want to use language as a tool in this world. So here is my take on
|
|
||||||
a creation myth for the main species of this world, the Kala (the title of this
|
|
||||||
post roughly translates to "creation story of the Kala").
|
|
||||||
|
|
||||||
This is day 2 of my 100 days to offload.
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
In the beginning, the gods roamed the skies. Pali, Sona and Soweli talked and
|
|
||||||
talked about their plans.
|
|
||||||
|
|
||||||
tenpo wan la sewi li lon e sewi. sewi Pali en sewi Sona en sewi Soweli li toki.
|
|
||||||
|
|
||||||
Soweli went down to the world Pali had created. Animals of all kinds followed
|
|
||||||
them as Soweli moved about the earth.
|
|
||||||
|
|
||||||
sewi Soweli li tawa e sike. soweli li kama e sike.
|
|
||||||
|
|
||||||
Sona followed and went towards the whales. Sona took a liking to how graceful
|
|
||||||
they were in the water, and decided to have them be the arbiters of knowledge.
|
|
||||||
Sona also reshaped them to look like the gods did. The Kala people resulted.
|
|
||||||
|
|
||||||
sewi Sona li tawa e soweli sike. sewi Sona li tawa e kala suli. sewi Sona li
|
|
||||||
lukin li pona e kala suli. sewi Sona li pana e sona e kon tawa kala suli. sewi
|
|
||||||
Sona li pali e jan kama kala suli. kulupu Kala li lon.
|
|
||||||
|
|
||||||
Pali had created the entire world, so Pali fell into a deep slumber in the
|
|
||||||
ocean.
|
|
||||||
|
|
||||||
tenpo pini la sewi Pali li pali e sike. sewi Pali li lape lon telo suli.
|
|
||||||
|
|
||||||
Soweli had created all of the animals on the whole world, so Soweli fell asleep
|
|
||||||
in Soweli mountain.
|
|
||||||
|
|
||||||
tenpo pini la sewi Soweli li pali e soweli ale. sewi Soweli li lape e nena Soweli.
|
|
||||||
|
|
||||||
Sona lifted themselves into the skies to watch the Kala from above. Sona keeps
|
|
||||||
an eye on us to make sure we are using their gift responsibly.
|
|
||||||
|
|
||||||
sewi Sona li tawa e sewi. sewi Sona li lukin e kulupu Kala. kulupu Kala li jo
|
|
||||||
sona li jo toki. kulupu Kala li pona e sewi Sona.
|
|
||||||
|
|
@ -1,100 +0,0 @@
|
||||||
---
|
|
||||||
title: "ln - The Natural Log Function"
|
|
||||||
date: 2020-10-17
|
|
||||||
tags:
|
|
||||||
- golang
|
|
||||||
- go
|
|
||||||
---
|
|
||||||
|
|
||||||
# ln - The Natural Log Function
|
|
||||||
|
|
||||||
One of the most essential things in software is a good interface for logging
|
|
||||||
data to places. Logging is a surprisingly hard problem and there are many
|
|
||||||
approaches to doing it. This time, we're going to talk about my favorite logging
|
|
||||||
library in Go that uses my favorite function I've ever written in Go.
|
|
||||||
|
|
||||||
Today we're talking about [ln](https://github.com/Xe/ln), the natural log
|
|
||||||
function. ln works with key value pairs and logs them to somewhere. By default
|
|
||||||
it logs things to standard out. Here is how you use it:
|
|
||||||
|
|
||||||
```go
|
|
||||||
package main
|
|
||||||
|
|
||||||
import (
|
|
||||||
"context"
|
|
||||||
|
|
||||||
"within.website/ln"
|
|
||||||
)
|
|
||||||
|
|
||||||
func main() {
|
|
||||||
ctx := context.Background()
|
|
||||||
ln.Log(ctx, ln.Fmt("hello %s", "world"), ln.F{"demo": "usage"})
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
ln works with key value pairs called [F](https://godoc.org/within.website/ln#F).
|
|
||||||
This type allows you to log just about _anything_ you want, including custom
|
|
||||||
data types with an [Fer](https://godoc.org/within.website/ln#Fer). This will let
|
|
||||||
you annotate your data types so that you can automatically extract the important
|
|
||||||
information into your logs while automatically filtering out passwords or other
|
|
||||||
secret data. Here's an example:
|
|
||||||
|
|
||||||
```go
|
|
||||||
type User struct {
|
|
||||||
ID int
|
|
||||||
Username string
|
|
||||||
Password []byte
|
|
||||||
}
|
|
||||||
|
|
||||||
func (u User) F() ln.F {
|
|
||||||
return ln.F{
|
|
||||||
"user_id": u.ID,
|
|
||||||
"user_name": u.Username,
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
Then if you create that user somehow, you can log the ID and username without
|
|
||||||
logging the password on accident:
|
|
||||||
|
|
||||||
```go
|
|
||||||
var theDude User = abides()
|
|
||||||
|
|
||||||
ln.Log(ctx, ln.Info("created new user"), theDude)
|
|
||||||
```
|
|
||||||
|
|
||||||
This will create a log line that looks something like this:
|
|
||||||
|
|
||||||
```
|
|
||||||
level=info msg="created new user" user_name="The Dude" user_id=1337
|
|
||||||
```
|
|
||||||
|
|
||||||
[You can also put values in contexts! See <a
|
|
||||||
href="https://github.com/Xe/ln/blob/master/ex/http.go#L21">here</a> for more
|
|
||||||
detail on how this works.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
The way this is all glued together is that F itself is an Fer, meaning that the
|
|
||||||
Log/Error functions take a variadic set of Fers. This is where my favorite Go
|
|
||||||
function comes into play, it is the implementation of the Fer interface for F.
|
|
||||||
Here is that function verbatim:
|
|
||||||
|
|
||||||
```go
|
|
||||||
// F makes F an Fer
|
|
||||||
func (f F) F() F {
|
|
||||||
return f
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
I love how this function looks like some kind of abstract art. This function
|
|
||||||
holds this library together.
|
|
||||||
|
|
||||||
If you end up using ln for your projects in the future, please let me know what
|
|
||||||
your experience is like. I would love to make this library the best it can
|
|
||||||
possibly be. It is not a nanosecond scale zero allocation library (I think those
|
|
||||||
kind of things are a bit of a waste of time, because most of the time your
|
|
||||||
logging library is NOT going to be your bottleneck), but it is designed to have
|
|
||||||
very usable defaults and solve the problem good enough that you shouldn't need
|
|
||||||
to care. There are a few useful tools in the
|
|
||||||
[ex](https://godoc.org/within.website/ln/ex) package nested in ln. The biggest
|
|
||||||
thing is the HTTP middleware, which has saved me a lot of effort when writing
|
|
||||||
web services in Go.
|
|
||||||
|
|
@ -1,51 +0,0 @@
|
||||||
---
|
|
||||||
title: "Mara: Sh0rk of Justice: Version 1.0.0 Released"
|
|
||||||
date: 2020-12-28
|
|
||||||
tags:
|
|
||||||
- gameboy
|
|
||||||
- gbstudio
|
|
||||||
- indiedev
|
|
||||||
---
|
|
||||||
|
|
||||||
# Mara: Sh0rk of Justice: Version 1.0.0 Released
|
|
||||||
|
|
||||||
Over the long weekend I found out about a program called [GB Studio](https://www.gbstudio.dev).
|
|
||||||
It's a simple drag-and-drop interface that you can use to make homebrew games for the
|
|
||||||
[Nintendo Game Boy](https://en.wikipedia.org/wiki/Game_Boy). I was intrigued and I had
|
|
||||||
some time, so I set out to make a little top-down adventure game. After a few days of
|
|
||||||
tinkering I came up with an idea and created Mara: Sh0rk of Justice.
|
|
||||||
|
|
||||||
[You made a game about me? :D](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
> Guide Mara through the spooky dungeon in order to find all of its secrets. Seek out
|
|
||||||
> the secrets of the spooks! Defeat the evil mage! Solve the puzzles! Find the items
|
|
||||||
> of power! It's up you to save us all, Mara!
|
|
||||||
|
|
||||||
You can play it in an `<iframe>` on itch.io!
|
|
||||||
|
|
||||||
<iframe frameborder="0" src="https://itch.io/embed/866982?dark=true" width="552" height="167"><a href="https://withinstudios.itch.io/mara-sh0rk-justice">Mara: Sh0rk of Justice by Within</a></iframe>
|
|
||||||
|
|
||||||
## Things I Learned
|
|
||||||
|
|
||||||
Game development is hard. Even with tools that help you do it, there's a limit to how
|
|
||||||
much you can get done at once. Everything links together. You really need to test
|
|
||||||
things both in isolation and as a cohesive whole.
|
|
||||||
|
|
||||||
I cannot compose music to save my life. I used free-to-use music assets from the
|
|
||||||
[GB Studio Community Assets](https://github.com/DeerTears/GB-Studio-Community-Assets)
|
|
||||||
pack to make this game. I think I managed to get everything acceptable.
|
|
||||||
|
|
||||||
GB Studio is rather inflexible. It feels like it's there to really help you get
|
|
||||||
started from a template. Even though you can make the whole game from inside GB
|
|
||||||
Studio, I probably should have ejected the engine to source code so I could
|
|
||||||
customize some things like the jump button being weird in platforming sections.
|
|
||||||
|
|
||||||
Pixel art is an art of its own. I used a lot of free to use assets from itch.io for
|
|
||||||
the tileset and a few NPC's. The rest was created myself using
|
|
||||||
[Aseprite](https://www.aseprite.org). Getting Mara's walking animation to a point
|
|
||||||
that I thought was acceptable was a chore. I found a nice compromise though.
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
Overall I'm happy with the result as a whole. Try it out, see how you like it and
|
|
||||||
please do let me know what I can improve on for the future.
|
|
||||||
|
|
@ -1,167 +0,0 @@
|
||||||
---
|
|
||||||
title: "maybedoer: the Maybe Monoid for Go"
|
|
||||||
date: 2020-05-23
|
|
||||||
tags:
|
|
||||||
- go
|
|
||||||
- golang
|
|
||||||
- monoid
|
|
||||||
---
|
|
||||||
|
|
||||||
# maybedoer: the Maybe Monoid for Go
|
|
||||||
|
|
||||||
I recently posted (a variant of) this image of some Go source code to Twitter
|
|
||||||
and it spawned some interesting conversations about what it does, how it works
|
|
||||||
and why it needs to exist in the first place:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
This file is used to sequence functions that could fail together, allowing you
|
|
||||||
to avoid doing an `if err != nil` check on every single fallible function call.
|
|
||||||
There are two major usage patterns for it.
|
|
||||||
|
|
||||||
The first one is the imperative pattern, where you call it like this:
|
|
||||||
|
|
||||||
```go
|
|
||||||
md := new(maybedoer.Impl)
|
|
||||||
|
|
||||||
var data []byte
|
|
||||||
|
|
||||||
md.Maybe(func(context.Context) error {
|
|
||||||
var err error
|
|
||||||
|
|
||||||
data, err = ioutil.ReadFile("/proc/cpuinfo")
|
|
||||||
|
|
||||||
return err
|
|
||||||
})
|
|
||||||
|
|
||||||
// add a few more maybe calls?
|
|
||||||
|
|
||||||
if err := md.Error(); err != nil {
|
|
||||||
ln.Error(ctx, err, ln.Fmt("cannot munge data in /proc/cpuinfo"))
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
The second one is the iterative pattern, where you call it like this:
|
|
||||||
|
|
||||||
```go
|
|
||||||
func gitPush(repoPath, branch, to string) maybedoer.Doer {
|
|
||||||
return func(ctx context.Context) error {
|
|
||||||
// the repoPath, branch and to variables are available here
|
|
||||||
return nil
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
func repush(ctx context.Context) error {
|
|
||||||
repoPath, err := ioutil.TempDir("", "")
|
|
||||||
if err != nil {
|
|
||||||
return fmt.Errorf("error making checkout: %v", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
md := maybedoer.Impl{
|
|
||||||
Doers: []maybedoer.Doer{
|
|
||||||
gitConfig, // assume this is implemented
|
|
||||||
gitClone(repoPath, os.Getenv("HEROKU_APP_GIT_REPO")), // and this too
|
|
||||||
gitPush(repoPath, "master", os.Getenv("HEROKU_GIT_REMOTE")),
|
|
||||||
},
|
|
||||||
}
|
|
||||||
|
|
||||||
err = md.Do(ctx)
|
|
||||||
if err != nil {
|
|
||||||
return fmt.Errorf("error repushing Heroku app: %v", err)
|
|
||||||
}
|
|
||||||
|
|
||||||
return nil
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
Both of these ways allow you to sequence fallible actions without having to
|
|
||||||
write `if err != nil` after each of them, making this easily scale out to
|
|
||||||
arbitrary numbers of steps. The design of this is inspired by a package used at
|
|
||||||
a previous job where we used it to handle a lot of fiddly fallible actions that
|
|
||||||
need to happen one after the other.
|
|
||||||
|
|
||||||
However, this version differs because of the `Doers` element of
|
|
||||||
`maybedoer.Impl`. This allows you to specify an entire process of steps as long
|
|
||||||
as those steps don't return any values. This is very similar to how Haskell's
|
|
||||||
[`Data.Monoid.First`](http://hackage.haskell.org/package/base-4.14.0.0/docs/Data-Monoid.html#t:First)
|
|
||||||
type works, except in Go this is locked to the `error` type (due to the language
|
|
||||||
not letting you describe things as precisely as you would need to get an analog
|
|
||||||
to `Data.Monoid.First`). This is also similar to Rust's `and_then` combinator.
|
|
||||||
|
|
||||||
If we could return values from these functions, this would make `maybedoer`
|
|
||||||
closer to being a monad in the Haskell sense. However we can't so we are locked
|
|
||||||
to one specific instance of a monoid. I would love to use this for a pointer (or
|
|
||||||
pointer-like) reference to any particular bit of data, but `interface{}` doesn't
|
|
||||||
allow this because `interface{}` matches _literally everything_:
|
|
||||||
|
|
||||||
```go
|
|
||||||
var foo = []interface{
|
|
||||||
1,
|
|
||||||
3.4,
|
|
||||||
"hi there",
|
|
||||||
context.Background(),
|
|
||||||
errors.New("this works too!"),
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
This could mean that if we changed the type of a Doer to be:
|
|
||||||
|
|
||||||
```go
|
|
||||||
type Doer func(context.Context) interface{}
|
|
||||||
```
|
|
||||||
|
|
||||||
Then it would be difficult to know how to handle returns from the function.
|
|
||||||
Arguably we could write some mechanism to check if it is an error:
|
|
||||||
|
|
||||||
```go
|
|
||||||
result := do(ctx)
|
|
||||||
if result != nil {
|
|
||||||
switch result.(type) {
|
|
||||||
case error:
|
|
||||||
return result // result is of type error magically
|
|
||||||
default:
|
|
||||||
md.return = result
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
But then it would be difficult to know how to pipe the result into the next
|
|
||||||
function, unless we change Doer's type to be:
|
|
||||||
|
|
||||||
```go
|
|
||||||
type Doer func(context.Context, interface{}) interface{}
|
|
||||||
```
|
|
||||||
|
|
||||||
Which would require code that looks like this:
|
|
||||||
|
|
||||||
```go
|
|
||||||
func getNumber(ctx context.Context, _ interface{}) interface{} {
|
|
||||||
return 2
|
|
||||||
}
|
|
||||||
|
|
||||||
func double(ctx context.Context, num interface{}) interface{} {
|
|
||||||
switch num.(type) {
|
|
||||||
case int:
|
|
||||||
return 2+2
|
|
||||||
default:
|
|
||||||
return fmt.Errorf("wanted num to be an int, got: %T", num)
|
|
||||||
}
|
|
||||||
|
|
||||||
return nil
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
But this kind of repetition would be required for _every function_. I don't
|
|
||||||
really know what the best way to solve this in a generic way would be, but I'm
|
|
||||||
fairly sure that these fundamental limitations in Go prevent this package from
|
|
||||||
being genericized to handle function outputs and inputs beyond what you can do
|
|
||||||
with currying (and maybe clever pointer usage).
|
|
||||||
|
|
||||||
I would love to be proven wrong though. If anyone can take this [source code
|
|
||||||
under the MIT license](/static/blog/maybedoer.go) and prove me wrong, I will
|
|
||||||
stand corrected and update this blogpost with the solution.
|
|
||||||
|
|
||||||
This kind of thing is more easy to solve in Rust with its
|
|
||||||
[Result](https://doc.rust-lang.org/std/result/) type; and arguably this entire
|
|
||||||
problem solved in the Go package is irrelevant in Rust because this solution is
|
|
||||||
in the standard library of Rust.
|
|
||||||
|
|
@ -1,397 +0,0 @@
|
||||||
---
|
|
||||||
title: "Minicompiler: Lexing"
|
|
||||||
date: 2020-10-29
|
|
||||||
series: rust
|
|
||||||
tags:
|
|
||||||
- rust
|
|
||||||
- templeos
|
|
||||||
- compiler
|
|
||||||
---
|
|
||||||
|
|
||||||
# Minicompiler: Lexing
|
|
||||||
|
|
||||||
I've always wanted to make my own compiler. Compilers are an integral part of
|
|
||||||
my day to day job and I use the fruits of them constantly. A while ago while I
|
|
||||||
was browsing through the TempleOS source code I found
|
|
||||||
[MiniCompiler.HC][minicompiler] in the `::/Demos/Lectures` folder and I was a
|
|
||||||
bit blown away. It implements a two phase compiler from simple math expressions
|
|
||||||
to AMD64 bytecode (complete with bit-banging it to an array that the code later
|
|
||||||
jumps to) and has a lot to teach about how compilers work. For those of you that
|
|
||||||
don't have a TempleOS VM handy, here is a video of MiniCompiler.HC in action:
|
|
||||||
|
|
||||||
[minicompiler]: https://github.com/Xe/TempleOS/blob/master/Demo/Lectures/MiniCompiler.HC
|
|
||||||
|
|
||||||
<video controls width="100%">
|
|
||||||
<source src="https://cdn.christine.website/file/christine-static/img/minicompiler/tmp.YDcgaHSb3z.webm"
|
|
||||||
type="video/webm">
|
|
||||||
<source src="https://cdn.christine.website/file/christine-static/img/minicompiler/tmp.YDcgaHSb3z.mp4"
|
|
||||||
type="video/mp4">
|
|
||||||
Sorry, your browser doesn't support embedded videos.
|
|
||||||
</video>
|
|
||||||
|
|
||||||
You put in a math expression, the compiler builds it and then spits out a bunch
|
|
||||||
of assembly and runs it to return the result. In this series we are going to be
|
|
||||||
creating an implementation of this compiler that targets [WebAssembly][wasm].
|
|
||||||
This compiler will be written in Rust and will use only the standard library for
|
|
||||||
everything but the final bytecode compilation and execution phase. There is a
|
|
||||||
lot going on here, so I expect this to be at least a three part series. The
|
|
||||||
source code will be in [Xe/minicompiler][Xemincompiler] in case you want to read
|
|
||||||
it in detail. Follow along and let's learn some Rust on the way!
|
|
||||||
|
|
||||||
[wasm]: https://webassembly.org/
|
|
||||||
[Xemincompiler]: https://github.com/Xe/minicompiler
|
|
||||||
|
|
||||||
[Compilers for languages like C are built on top of the fundamentals here, but
|
|
||||||
they are _much_ more complicated.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
## Description of the Language
|
|
||||||
|
|
||||||
This language uses normal infix math expressions on whole numbers. Here are a
|
|
||||||
few examples:
|
|
||||||
|
|
||||||
- `2 + 2`
|
|
||||||
- `420 * 69`
|
|
||||||
- `(34 + 23) / 38 - 42`
|
|
||||||
- `(((34 + 21) / 5) - 12) * 348`
|
|
||||||
|
|
||||||
Ideally we should be able to nest the parentheses as deep as we want without any
|
|
||||||
issues.
|
|
||||||
|
|
||||||
Looking at these values we can notice a few patterns that will make parsing this
|
|
||||||
a lot easier:
|
|
||||||
|
|
||||||
- There seems to be only 4 major parts to this language:
|
|
||||||
- numbers
|
|
||||||
- math operators
|
|
||||||
- open parentheses
|
|
||||||
- close parentheses
|
|
||||||
- All of the math operators act identically and take two arguments
|
|
||||||
- Each program is one line long and ends at the end of the line
|
|
||||||
|
|
||||||
Let's turn this description into Rust code:
|
|
||||||
|
|
||||||
## Bringing in Rust
|
|
||||||
|
|
||||||
Make a new project called `minicompiler` with a command that looks something
|
|
||||||
like this:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ cargo new minicompiler
|
|
||||||
```
|
|
||||||
|
|
||||||
This will create a folder called `minicompiler` and a file called `src/main.rs`.
|
|
||||||
Open that file in your editor and copy the following into it:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
// src/main.rs
|
|
||||||
|
|
||||||
/// Mathematical operations that our compiler can do.
|
|
||||||
#[derive(Debug, Eq, PartialEq)]
|
|
||||||
enum Op {
|
|
||||||
Mul,
|
|
||||||
Div,
|
|
||||||
Add,
|
|
||||||
Sub,
|
|
||||||
}
|
|
||||||
|
|
||||||
/// All of the possible tokens for the compiler, this limits the compiler
|
|
||||||
/// to simple math expressions.
|
|
||||||
#[derive(Debug, Eq, PartialEq)]
|
|
||||||
enum Token {
|
|
||||||
EOF,
|
|
||||||
Number(i32),
|
|
||||||
Operation(Op),
|
|
||||||
LeftParen,
|
|
||||||
RightParen,
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
[In compilers, "tokens" refer to the individual parts of the language you are
|
|
||||||
working with. In this case every token represents every possible part of a
|
|
||||||
program.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
And then let's start a function that can turn a program string into a bunch of
|
|
||||||
tokens:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
// src/main.rs
|
|
||||||
|
|
||||||
fn lex(input: &str) -> Vec<Token> {
|
|
||||||
todo!("implement this");
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
[Wait, what do you do about bad input such as things that are not math expressions?
|
|
||||||
Shouldn't this function be able to fail?](conversation://Mara/hmm)
|
|
||||||
|
|
||||||
You're right! Let's make a little error type that represents bad input. For
|
|
||||||
creativity's sake let's call it `BadInput`:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
// src/main.rs
|
|
||||||
|
|
||||||
use std::error::Error;
|
|
||||||
use std::fmt;
|
|
||||||
|
|
||||||
/// The error that gets returned on bad input. This only tells the user that it's
|
|
||||||
/// wrong because debug information is out of scope here. Sorry.
|
|
||||||
#[derive(Debug, Eq, PartialEq)]
|
|
||||||
struct BadInput;
|
|
||||||
|
|
||||||
// Errors need to be displayable.
|
|
||||||
impl fmt::Display for BadInput {
|
|
||||||
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
|
|
||||||
write!(f, "something in your input is bad, good luck")
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
// The default Error implementation will do here.
|
|
||||||
impl Error for BadInput {}
|
|
||||||
```
|
|
||||||
|
|
||||||
And then let's adjust the type of `lex()` to compensate for this:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
// src/main.rs
|
|
||||||
|
|
||||||
fn lex(input: &str) -> Result<Vec<Token>, BadInput> {
|
|
||||||
todo!("implement this");
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
So now that we have the function type we want, let's start implementing `lex()`
|
|
||||||
by setting up the result and a loop over the characters in the input string:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
// src/main.rs
|
|
||||||
|
|
||||||
fn lex(input: &str) -> Result<Vec<Token>, BadInput> {
|
|
||||||
let mut result: Vec<Token> = Vec::new();
|
|
||||||
|
|
||||||
for character in input.chars() {
|
|
||||||
todo!("implement this");
|
|
||||||
}
|
|
||||||
|
|
||||||
Ok(result)
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
Looking at the examples from earlier we can start writing some boilerplate to
|
|
||||||
turn characters into tokens:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
// src/main.rs
|
|
||||||
|
|
||||||
// ...
|
|
||||||
|
|
||||||
for character in input.chars() {
|
|
||||||
match character {
|
|
||||||
// Skip whitespace
|
|
||||||
' ' => continue,
|
|
||||||
|
|
||||||
// Ending characters
|
|
||||||
';' | '\n' => {
|
|
||||||
result.push(Token::EOF);
|
|
||||||
break;
|
|
||||||
}
|
|
||||||
|
|
||||||
// Math operations
|
|
||||||
'*' => result.push(Token::Operation(Op::Mul)),
|
|
||||||
'/' => result.push(Token::Operation(Op::Div)),
|
|
||||||
'+' => result.push(Token::Operation(Op::Add)),
|
|
||||||
'-' => result.push(Token::Operation(Op::Sub)),
|
|
||||||
|
|
||||||
// Parentheses
|
|
||||||
'(' => result.push(Token::LeftParen),
|
|
||||||
')' => result.push(Token::RightParen),
|
|
||||||
|
|
||||||
// Numbers
|
|
||||||
'0' | '1' | '2' | '3' | '4' | '5' | '6' | '7' | '8' | '9' => {
|
|
||||||
todo!("implement number parsing")
|
|
||||||
}
|
|
||||||
|
|
||||||
// Everything else is bad input
|
|
||||||
_ => return Err(BadInput),
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
// ...
|
|
||||||
```
|
|
||||||
|
|
||||||
[Ugh, you're writing `Token::` and `Op::` a lot. Is there a way to simplify
|
|
||||||
that?](conversation://Mara/hmm)
|
|
||||||
|
|
||||||
Yes! enum variants can be shortened to their names with a `use` statement like
|
|
||||||
this:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
// src/main.rs
|
|
||||||
|
|
||||||
// ...
|
|
||||||
|
|
||||||
use Op::*;
|
|
||||||
use Token::*;
|
|
||||||
|
|
||||||
match character {
|
|
||||||
// ...
|
|
||||||
|
|
||||||
// Math operations
|
|
||||||
'*' => result.push(Operation(Mul)),
|
|
||||||
'/' => result.push(Operation(Div)),
|
|
||||||
'+' => result.push(Operation(Add)),
|
|
||||||
'-' => result.push(Operation(Sub)),
|
|
||||||
|
|
||||||
// Parentheses
|
|
||||||
'(' => result.push(LeftParen),
|
|
||||||
')' => result.push(RightParen),
|
|
||||||
|
|
||||||
// ...
|
|
||||||
}
|
|
||||||
|
|
||||||
// ...
|
|
||||||
```
|
|
||||||
|
|
||||||
Which looks a _lot_ better.
|
|
||||||
|
|
||||||
[You can use the `use` statement just about anywhere in your program. However to
|
|
||||||
keep things flowing nicer, the `use` statement is right next to where it is
|
|
||||||
needed in these examples.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
Now we can get into the fun that is parsing numbers. When he wrote MiniCompiler,
|
|
||||||
Terry Davis used an approach that is something like this (spacing added for readability):
|
|
||||||
|
|
||||||
```c
|
|
||||||
case '0'...'9':
|
|
||||||
i = 0;
|
|
||||||
do {
|
|
||||||
i = i * 10 + *src - '0';
|
|
||||||
src++;
|
|
||||||
} while ('0' <= *src <= '9');
|
|
||||||
*num=i;
|
|
||||||
```
|
|
||||||
|
|
||||||
This sets an intermediate variable `i` to 0 and then consumes characters from
|
|
||||||
the input string as long as they are between `'0'` and `'9'`. As a neat side
|
|
||||||
effect of the numbers being input in base 10, you can conceptualize `40` as `(4 *
|
|
||||||
10) + 2`. So it multiplies the old digit by 10 and then adds the new digit to
|
|
||||||
the resulting number. Our setup doesn't let us get that fancy as easily, however
|
|
||||||
we can emulate it with a bit of stack manipulation according to these rules:
|
|
||||||
|
|
||||||
- If `result` is empty, push this number to result and continue lexing the
|
|
||||||
program
|
|
||||||
- Pop the last item in `result` and save it as `last`
|
|
||||||
- If `last` is a number, multiply that number by 10 and add the current number
|
|
||||||
to it
|
|
||||||
- Otherwise push the node back into `result` and push the current number to
|
|
||||||
`result` as well
|
|
||||||
|
|
||||||
Translating these rules to Rust, we get this:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
// src/main.rs
|
|
||||||
|
|
||||||
// ...
|
|
||||||
|
|
||||||
// Numbers
|
|
||||||
'0' | '1' | '2' | '3' | '4' | '5' | '6' | '7' | '8' | '9' => {
|
|
||||||
let num: i32 = (character as u8 - '0' as u8) as i32;
|
|
||||||
if result.len() == 0 {
|
|
||||||
result.push(Number(num));
|
|
||||||
continue;
|
|
||||||
}
|
|
||||||
|
|
||||||
let last = result.pop().unwrap();
|
|
||||||
|
|
||||||
match last {
|
|
||||||
Number(i) => {
|
|
||||||
result.push(Number((i * 10) + num));
|
|
||||||
}
|
|
||||||
_ => {
|
|
||||||
result.push(last);
|
|
||||||
result.push(Number(num));
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
// ...
|
|
||||||
```
|
|
||||||
|
|
||||||
[This is not the most robust number parsing code in the world, however it will
|
|
||||||
suffice for now. Extra credit if you can identify the edge
|
|
||||||
cases!](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
This should cover the tokens for the language. Let's write some tests to be sure
|
|
||||||
everything is working the way we think it is!
|
|
||||||
|
|
||||||
## Testing
|
|
||||||
|
|
||||||
Rust has a [robust testing
|
|
||||||
framework](https://doc.rust-lang.org/book/ch11-00-testing.html) built into the
|
|
||||||
standard library. We can use it here to make sure we are generating tokens
|
|
||||||
correctly. Let's add the following to the bottom of `main.rs`:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
#[cfg(test)] // tells the compiler to only build this code when tests are being run
|
|
||||||
mod tests {
|
|
||||||
use super::{Op::*, Token::*, *};
|
|
||||||
|
|
||||||
// registers the following function as a test function
|
|
||||||
#[test]
|
|
||||||
fn basic_lexing() {
|
|
||||||
assert!(lex("420 + 69").is_ok());
|
|
||||||
assert!(lex("tacos are tasty").is_err());
|
|
||||||
|
|
||||||
assert_eq!(
|
|
||||||
lex("420 + 69"),
|
|
||||||
Ok(vec![Number(420), Operation(Add), Number(69)])
|
|
||||||
);
|
|
||||||
assert_eq!(
|
|
||||||
lex("(30 + 560) / 4"),
|
|
||||||
Ok(vec![
|
|
||||||
LeftParen,
|
|
||||||
Number(30),
|
|
||||||
Operation(Add),
|
|
||||||
Number(560),
|
|
||||||
RightParen,
|
|
||||||
Operation(Div),
|
|
||||||
Number(4)
|
|
||||||
])
|
|
||||||
);
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
This test can and probably should be expanded on, but when we run `cargo test`:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ cargo test
|
|
||||||
Compiling minicompiler v0.1.0 (/home/cadey/code/Xe/minicompiler)
|
|
||||||
|
|
||||||
Finished test [unoptimized + debuginfo] target(s) in 0.22s
|
|
||||||
Running target/debug/deps/minicompiler-03cad314858b0419
|
|
||||||
|
|
||||||
running 1 test
|
|
||||||
test tests::basic_lexing ... ok
|
|
||||||
|
|
||||||
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
|
|
||||||
```
|
|
||||||
|
|
||||||
And hey presto! We verified that all of the parsing is working correctly. Those
|
|
||||||
test cases should be sufficient to cover all of the functionality of the
|
|
||||||
language.
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
This is it for part 1. We covered a lot today. Next time we are going to run a
|
|
||||||
validation pass on the program, convert the infix expressions to reverse polish
|
|
||||||
notation and then also get started on compiling that to WebAssembly. This has
|
|
||||||
been fun so far and I hope you were able to learn from it.
|
|
||||||
|
|
||||||
Special thanks to the following people for reviewing this post:
|
|
||||||
- Steven Weeks
|
|
||||||
- sirpros
|
|
||||||
- Leonora Tindall
|
|
||||||
- Chetan Conikee
|
|
||||||
- Pablo
|
|
||||||
- boopstrap
|
|
||||||
- ash2x3
|
|
||||||
|
|
@ -1,92 +0,0 @@
|
||||||
---
|
|
||||||
title: "Book Release: Musings from Within"
|
|
||||||
date: 2020-07-28
|
|
||||||
tags:
|
|
||||||
- release
|
|
||||||
- book
|
|
||||||
- musingsfromwithin
|
|
||||||
---
|
|
||||||
|
|
||||||
# Book Release: Musings from Within
|
|
||||||
|
|
||||||
I am happy to announce that I have successfully created an eBook compilation of
|
|
||||||
the best of the posts on this blog plus a bunch of writing I have never before
|
|
||||||
made public, and the result is now available for purchase on
|
|
||||||
[itch.io](https://withinstudios.itch.io/musings-from-within) and the Kindle
|
|
||||||
Store (TODO(Xe): add kindle link here when it gets approved) for USD$5. This
|
|
||||||
book is the product of 5 years of effort writing, getting better at writing,
|
|
||||||
failing at writing and everything inbetween.
|
|
||||||
|
|
||||||
I have collected the following essays, poems, recipes and stories:
|
|
||||||
|
|
||||||
- Against Label Permanence
|
|
||||||
- A Letter to Those Who Bullied Me
|
|
||||||
- All There is is Now
|
|
||||||
- Alone
|
|
||||||
- Barrier
|
|
||||||
- Bricks
|
|
||||||
- Chaos Magick Debugging
|
|
||||||
- Chicken Stir Fry
|
|
||||||
- Creator’s Mission
|
|
||||||
- Death
|
|
||||||
- Died to Save Me
|
|
||||||
- Don't Look Into the Light
|
|
||||||
- Every Koan Ever
|
|
||||||
- Final Chapter
|
|
||||||
- Gratitude
|
|
||||||
- h
|
|
||||||
- How HTTP Requests Work
|
|
||||||
- Humanity
|
|
||||||
- I Love
|
|
||||||
- Instant Pot Quinoa Taco Bowls
|
|
||||||
- Instant Pot Spaghetti
|
|
||||||
- I Put Words on this Webpage so You Have to Listen to Me Now
|
|
||||||
- I Remember
|
|
||||||
- It Is Free
|
|
||||||
- Listen to Your Rubber Duck
|
|
||||||
- MrBeast is Postmodern Gold
|
|
||||||
- My Experience Cursing Out God
|
|
||||||
- Narrative of Sickness
|
|
||||||
- One Day
|
|
||||||
- Plurality-Driven Development
|
|
||||||
- Practical Kasmakfa
|
|
||||||
- Questions
|
|
||||||
- Second Go Around
|
|
||||||
- Self
|
|
||||||
- Sorting Time
|
|
||||||
- Tarot for Hackers
|
|
||||||
- The Gears and The Gods
|
|
||||||
- The Origin of h
|
|
||||||
- The Service is Already Down
|
|
||||||
- The Story of Hol
|
|
||||||
- The Sumerian Creation Myth
|
|
||||||
- Toast Sandwich Recipe
|
|
||||||
- Untitled Cyberpunk Furry Story
|
|
||||||
- We Exist
|
|
||||||
- What It’s Like to Be Me
|
|
||||||
- When Then Zen
|
|
||||||
- When Then Zen: Anapana
|
|
||||||
- When Then Zen: Wonderland Immersion
|
|
||||||
- You Are Fine
|
|
||||||
|
|
||||||
Most of these are available on this site, but a good portion of them are not
|
|
||||||
available anywhere else. There's poetry about shamanism, stories about
|
|
||||||
reincarnation, koans and more.
|
|
||||||
|
|
||||||
I am also uploading eBook files to my [Patreon](https://patreon.com/cadey) page,
|
|
||||||
anyone who supports me for $1 or more has [immediate
|
|
||||||
access](https://www.patreon.com/posts/39825969)
|
|
||||||
to the DRM-free ePub, MOBIPocket and PDF files of this book.
|
|
||||||
|
|
||||||
If you are facing financial difficulties, want to read my book and just simply
|
|
||||||
cannot afford it, please [contact me](/contact) and I will send you my book free
|
|
||||||
of charge.
|
|
||||||
|
|
||||||
Feedback and reviews of this book are more than welcome. If you decide to tweet
|
|
||||||
or toot about it, please use the hashtag `#musingsfromwithin` so I can collect
|
|
||||||
them into future updates to the description of the store pages, as well as
|
|
||||||
assemble them below.
|
|
||||||
|
|
||||||
Enjoy the book! My hope is that you get as much from it as I've gotten from
|
|
||||||
writing these things for the last 5 or so years. Here's to five more. I'll
|
|
||||||
likely create another anthology/collection of them at that point.
|
|
||||||
|
|
@ -5,9 +5,7 @@ date: 2019-03-14
|
||||||
|
|
||||||
# My Career So Far in Dates/Titles/Salaries
|
# My Career So Far in Dates/Titles/Salaries
|
||||||
|
|
||||||
Let this be inspiration to whoever is afraid of trying, failing and being fired.
|
Let this be inspiration to whoever is afraid of trying, failing and being fired. Every single one of these jobs has taught me lessons I've used daily in my career.
|
||||||
Every single one of these jobs has taught me lessons I've used daily in my
|
|
||||||
career.
|
|
||||||
|
|
||||||
## First Jobs
|
## First Jobs
|
||||||
|
|
||||||
|
|
@ -19,14 +17,11 @@ I don't have exact dates on these, but my first jobs were:
|
||||||
|
|
||||||
I ended up walking out on the delivery job, but that's a story for another day.
|
I ended up walking out on the delivery job, but that's a story for another day.
|
||||||
|
|
||||||
Most of what I learned from these jobs were the value of labor and when to just
|
Most of what I learned from these jobs were the value of labor and when to just shut up and give people exactly what they are asking for. Even if it's what they might not want.
|
||||||
shut up and give people exactly what they are asking for. Even if it's what they
|
|
||||||
might not want.
|
|
||||||
|
|
||||||
## Salaried Jobs
|
## Salaried Jobs
|
||||||
|
|
||||||
The following table is a history of my software career by title, date and salary
|
The following table is a history of my software career by title, date and salary (company names are omitted).
|
||||||
(company names are omitted).
|
|
||||||
|
|
||||||
| Title | Start Date | End Date | Days Worked | Days Between Jobs | Salary | How I Left |
|
| Title | Start Date | End Date | Days Worked | Days Between Jobs | Salary | How I Left |
|
||||||
|:----- |:---------- |:-------- |:----------- |:----------------- |:------ |:---------- |
|
|:----- |:---------- |:-------- |:----------- |:----------------- |:------ |:---------- |
|
||||||
|
|
@ -40,19 +35,11 @@ The following table is a history of my software career by title, date and salary
|
||||||
| Software Engineer | August 24, 2016 | November 22, 2016 | 90 days | 21 days | $105,000/year | Terminated |
|
| Software Engineer | August 24, 2016 | November 22, 2016 | 90 days | 21 days | $105,000/year | Terminated |
|
||||||
| Consultant | Feburary 13, 2017 | November 13, 2017 | 273 days | 83 days | don't remember | Hired |
|
| Consultant | Feburary 13, 2017 | November 13, 2017 | 273 days | 83 days | don't remember | Hired |
|
||||||
| Senior Software Engineer | November 13, 2017 | March 8, 2019 | 480 days | 0 days | $150,000/year | Voulntary quit |
|
| Senior Software Engineer | November 13, 2017 | March 8, 2019 | 480 days | 0 days | $150,000/year | Voulntary quit |
|
||||||
| Senior Site Reliability Expert | May 6, 2019 | October 27, 2020 | 540 days | 48 days | CAD$115,000/year (about USD$ 80k and change) | Voluntary quit |
|
| Senior Site Reliability Expert | May 6, 2019 | (will be current) | n/a | n/a | CAD$105,000/year (about USD$ 80k and change) | n/a |
|
||||||
| Software Designer | December 14, 2020 | *current* | n/a | n/a | CAD$135,000/year (about USD$ 105k and change) | n/a |
|
|
||||||
|
|
||||||
Even though I've been fired three times, I don't regret my career as it's been
|
Even though I've been fired three times, I don't regret my career as it's been thus far. I've been able to work on experimental technology integrating into phone systems. I've worked in a mixed PHP/Haskell/Erlang/Go/Perl production environment. I've literally rebuilt most of the tool that was catalytic to my career a few times over. It's been the ride of a lifetime.
|
||||||
thus far. I've been able to work on experimental technology integrating into
|
|
||||||
phone systems. I've worked in a mixed PHP/Haskell/Erlang/Go/Perl production
|
|
||||||
environment. I've literally rebuilt most of the tool that was catalytic to my
|
|
||||||
career a few times over. It's been the ride of a lifetime.
|
|
||||||
|
|
||||||
Even though I was fired, each of these failures in this chain of jobs enabled me
|
Even though I was fired, each of these failures in this chain of jobs enabled me to succeed the way I have. I can't wait to see what's next out of it. I only wonder how I can be transformed even more. I really wonder what it's gonna be like with the company that hired me over the border.
|
||||||
to succeed the way I have. I can't wait to see what's next out of it. I only
|
|
||||||
wonder how I can be transformed even more. I really wonder what it's gonna be
|
|
||||||
like with the company that hired me over the border.
|
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
|
|
@ -74,8 +61,4 @@ Be well.
|
||||||
.i ko do gleki
|
.i ko do gleki
|
||||||
```
|
```
|
||||||
|
|
||||||
If you can, please make a blogpost similar to this. Don't include company names.
|
If you can, please make a blogpost similar to this. Don't include company names. Include start date, end date, time spent there, time spent job hunting, salary (if you remember it) and how you left it. Let's [end salary secrecy](https://thegirlpowercode.com/2018/09/12/is-salary-secrecy-coming-to-an-end/) one step at a time.
|
||||||
Include start date, end date, time spent there, time spent job hunting, salary
|
|
||||||
(if you remember it) and how you left it. Let's [end salary
|
|
||||||
secrecy](https://thegirlpowercode.com/2018/09/12/is-salary-secrecy-coming-to-an-end/)
|
|
||||||
one step at a time.
|
|
||||||
|
|
@ -1,81 +0,0 @@
|
||||||
---
|
|
||||||
title: "Life Update: New Adventures"
|
|
||||||
date: 2020-10-24
|
|
||||||
tags:
|
|
||||||
- personal
|
|
||||||
---
|
|
||||||
|
|
||||||
# Life Update: New Adventures
|
|
||||||
|
|
||||||
Today was my last day at my job, and as of the time that I have published this
|
|
||||||
post, I am now inbetween jobs. I have had an adventure at Lightspeed, but all
|
|
||||||
things must come to an end and my adventure has come to an end there. I have a
|
|
||||||
new job lined up and I will be heading to it soon, but for the meantime I plan
|
|
||||||
to relax and decompress.
|
|
||||||
|
|
||||||
I want to finish that tabletop RPG book I have prototyped out. When I have
|
|
||||||
something closer to a cohesive book I will post something on my
|
|
||||||
[patreon](https://www.patreon.com/cadey) so that you all can take a look. Any
|
|
||||||
and all feedback would be very appreciated. I hope to have it published on my
|
|
||||||
[Itch page](https://withinstudios.itch.io/) by the end of this year. My target
|
|
||||||
is on or about $5 for the game manual and supplemental material.
|
|
||||||
|
|
||||||
Thanks for reading; no, seriously, thank you. Without people like you that
|
|
||||||
read and share articles on this blog I would never have gotten to the level of
|
|
||||||
success that I have now. Additionally, I would like to emphasize that I am fine
|
|
||||||
as far as new jobs go. I have primary and fallback plans in place, but if they
|
|
||||||
all somehow fall through I will be sure to put up a note here. Please be sure to
|
|
||||||
check out [/signalboost](/signalboost) for people to consider when making hiring
|
|
||||||
decisions.
|
|
||||||
|
|
||||||
## May Our Paths Cross Again: My Farewell Letter to Lightspeed
|
|
||||||
|
|
||||||
Hey all,
|
|
||||||
|
|
||||||
Today is my last day at Lightspeed. Working at Lightspeed has been catalytic to
|
|
||||||
my career. I have been exposed to so many people from so many backgrounds and
|
|
||||||
you all have irreparably changed me for the better and given me the space to
|
|
||||||
thrive. There is passion here, and it is being tapped in order to create
|
|
||||||
fantastic solutions for our customers to enable them to succeed. I originally
|
|
||||||
came to Montréal to live with my fiancé and if Covid had struck a week later he
|
|
||||||
would be my husband.
|
|
||||||
|
|
||||||
However, I feel that I have done as much as I can at Lightspeed and our paths
|
|
||||||
thusly need to divide. I have gotten a fantastic opportunity and I will be
|
|
||||||
working on technology that will become a foundational part of personal and
|
|
||||||
professional IP networking over WireGuard for many companies and people. I'm
|
|
||||||
sorry if this comes as a shock to anyone, I don't mean to cause anyone grief
|
|
||||||
with this move.
|
|
||||||
|
|
||||||
I have been attaching a little poem in Lojban to the signature of my emails,
|
|
||||||
here is it and its translation:
|
|
||||||
|
|
||||||
```
|
|
||||||
la budza pu cusku lu
|
|
||||||
<<.i ko do snura .i ko do kanro
|
|
||||||
.i ko do panpi .i ko do gleki>> li'u
|
|
||||||
```
|
|
||||||
|
|
||||||
> May you be safe. May you be healthy.
|
|
||||||
> May you be at peace. May you be happy.
|
|
||||||
- Buddha
|
|
||||||
|
|
||||||
I will be reachable on the internet. See https://christine.website/contact to
|
|
||||||
see contact information that will help you reach out to me. If you can, please
|
|
||||||
direct replies to me@christine.website, that way I can read them after this
|
|
||||||
account gets disabled.
|
|
||||||
|
|
||||||
I hope I was able to brighten your path.
|
|
||||||
|
|
||||||
From my world to yours,
|
|
||||||
|
|
||||||
--
|
|
||||||
|
|
||||||
Christine Dodrill
|
|
||||||
https://christine.website
|
|
||||||
|
|
||||||
```
|
|
||||||
la budza pu cusku lu
|
|
||||||
<<.i ko do snura .i ko do kanro
|
|
||||||
.i ko do panpi .i ko do gleki>> li'u
|
|
||||||
```
|
|
||||||
|
|
@ -1,38 +0,0 @@
|
||||||
---
|
|
||||||
title: New PGP Key Fingerprint
|
|
||||||
date: 2021-01-15
|
|
||||||
---
|
|
||||||
|
|
||||||
# New PGP Key Fingerprint
|
|
||||||
|
|
||||||
This morning I got an encrypted email, and in the process of trying to decrypt
|
|
||||||
it I discovered that I had _lost_ my PGP key. I have no idea how I lost it. As
|
|
||||||
such, I have created a new PGP key and replaced the one on my website with it.
|
|
||||||
I did the replacement in [this
|
|
||||||
commit](https://github.com/Xe/site/commit/66233bcd40155cf71e221edf08851db39dbd421c),
|
|
||||||
which you can see is verified with a subkey of my new key.
|
|
||||||
|
|
||||||
My new PGP key ID is `803C 935A E118 A224`. The key with the ID `799F 9134 8118
|
|
||||||
1111` should not be used anymore. Here are all the subkey fingerprints:
|
|
||||||
|
|
||||||
```
|
|
||||||
Signature key ....: 378E BFC6 3D79 B49D 8C36 448C 803C 935A E118 A224
|
|
||||||
created ....: 2021-01-15 13:04:28
|
|
||||||
Encryption key....: 8C61 7F30 F331 D21B 5517 6478 8C5C 9BC7 0FC2 511E
|
|
||||||
created ....: 2021-01-15 13:04:28
|
|
||||||
Authentication key: 7BF7 E531 ABA3 7F77 FD17 8F72 CE17 781B F55D E945
|
|
||||||
created ....: 2021-01-15 13:06:20
|
|
||||||
General key info..: pub rsa2048/803C935AE118A224 2021-01-15 Christine Dodrill (Yubikey) <me@christine.website>
|
|
||||||
sec> rsa2048/803C935AE118A224 created: 2021-01-15 expires: 2031-01-13
|
|
||||||
card-no: 0006 03646872
|
|
||||||
ssb> rsa2048/8C5C9BC70FC2511E created: 2021-01-15 expires: 2031-01-13
|
|
||||||
card-no: 0006 03646872
|
|
||||||
ssb> rsa2048/CE17781BF55DE945 created: 2021-01-15 expires: 2031-01-13
|
|
||||||
card-no: 0006 03646872
|
|
||||||
```
|
|
||||||
|
|
||||||
I don't really know what the proper way is to go about revoking an old PGP key.
|
|
||||||
It probably doesn't help that I don't use PGP very often. I think this is the
|
|
||||||
first encrypted email I've gotten in a year.
|
|
||||||
|
|
||||||
Let's hope that I don't lose this key as easily!
|
|
||||||
|
|
@ -1,317 +0,0 @@
|
||||||
---
|
|
||||||
title: Nixops Services on Your Home Network
|
|
||||||
date: 2020-11-09
|
|
||||||
series: howto
|
|
||||||
tags:
|
|
||||||
- nixos
|
|
||||||
- systemd
|
|
||||||
---
|
|
||||||
|
|
||||||
# Nixops Services on Your Home Network
|
|
||||||
|
|
||||||
My homelab has a few NixOS machines. Right now they mostly run services inside
|
|
||||||
Docker, because that has been what I have done for years. This works fine, but
|
|
||||||
persistent state gets annoying*. NixOS has a tool called
|
|
||||||
[Nixops](https://releases.nixos.org/nixops/nixops-1.7/manual/manual.html) that
|
|
||||||
allows you to push configurations to remote machines. I use this for managing my
|
|
||||||
fleet of machines, and today I'm going to show you how to create service
|
|
||||||
deployments with Nixops and push them to your servers.
|
|
||||||
|
|
||||||
[Pedantically, Docker offers <a
|
|
||||||
href="https://releases.nixos.org/nixops/nixops-1.7/manual/manual.html">volumes</a>
|
|
||||||
to simplify this, but it is very easy to accidentally delete Docker volumes.
|
|
||||||
Plain disk files like we are going to use today are a bit simpler than docker
|
|
||||||
volumes, and thusly a bit harder to mess up.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
## Parts of a Service
|
|
||||||
|
|
||||||
For this example, let's deploy a chatbot. To make things easier, let's assume
|
|
||||||
the following about this chatbot:
|
|
||||||
|
|
||||||
- The chatbot has a git repo somewhere
|
|
||||||
- The chatbot's git repo has a `default.nix` that builds the service and
|
|
||||||
includes any supporting files it might need
|
|
||||||
- The chatbot reads its configuration from environment variables which may
|
|
||||||
contain secret values (API keys, etc.)
|
|
||||||
- The chatbot stores any temporary files in its current working directory
|
|
||||||
- The chatbot is "well-behaved" (for some definition of "well-behaved")
|
|
||||||
|
|
||||||
I will also need to assume that you have a git repo (or at least a folder) with
|
|
||||||
all of your configuration similar to [mine](https://github.com/Xe/nixos-configs).
|
|
||||||
|
|
||||||
For this example I'm going to use [withinbot](https://github.com/Xe/withinbot)
|
|
||||||
as the service we will deploy via Nixops. withinbot is a chatbot that I use on
|
|
||||||
my own Discord guild that does a number of vital functions including supplying
|
|
||||||
amusing facts about printers:
|
|
||||||
|
|
||||||
```
|
|
||||||
<Cadey~> ~printerfact
|
|
||||||
<Within[BOT]> @Cadey~ Printers, especially older printers, do get cancer. Many
|
|
||||||
times this disease can be treated successfully
|
|
||||||
```
|
|
||||||
|
|
||||||
[To get your own amusing facts about printers, see <a
|
|
||||||
href="https://printerfacts.cetacean.club">here</a> or for using its API, call <a
|
|
||||||
href="https://printerfacts.cetacean.club/fact">`/fact`</a>. This API has no
|
|
||||||
practical rate limits, but please don't test that.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
## Service Definition
|
|
||||||
|
|
||||||
We will need to do a few major things for defining this service:
|
|
||||||
|
|
||||||
1. Add the bot code as a package
|
|
||||||
1. Create a "services" folder for the service modules
|
|
||||||
1. Create a user account for the service
|
|
||||||
1. Set up a systemd unit for the service
|
|
||||||
1. Configure the secrets using [Nixops
|
|
||||||
keys](https://releases.nixos.org/nixops/nixops-1.7/manual/manual.html#idm140737322342384)
|
|
||||||
|
|
||||||
### Add the Code as a Package
|
|
||||||
|
|
||||||
In order for the program to be installed to the remote system, you need to tell
|
|
||||||
the system how to import it. There's many ways to do this, but the cheezy way is
|
|
||||||
to add the packages to
|
|
||||||
[`nixpkgs.config.packageOverrides`](https://nixos.org/manual/nixos/stable/#sec-customising-packages)
|
|
||||||
like this:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
nixpkgs.config = {
|
|
||||||
packageOverrides = pkgs: {
|
|
||||||
within = {
|
|
||||||
withinbot = import (builtins.fetchTarball
|
|
||||||
"https://github.com/Xe/withinbot/archive/main.tar.gz") { };
|
|
||||||
};
|
|
||||||
};
|
|
||||||
};
|
|
||||||
```
|
|
||||||
|
|
||||||
And now we can access it as `pkgs.within.withinbot` in the rest of our config.
|
|
||||||
|
|
||||||
[In production circumstances you should probably use <a
|
|
||||||
href="https://nixos.org/manual/nixpkgs/stable/#chap-pkgs-fetchers">a fetcher
|
|
||||||
that locks to a specific version</a> using unique URLs and hashing, but this
|
|
||||||
will work enough to get us off the ground in this
|
|
||||||
example.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
### Create a "services" Folder
|
|
||||||
|
|
||||||
In your configuration folder, create a folder that you will use for these
|
|
||||||
service definitions. I made mine in `common/services`. In that folder, create a
|
|
||||||
`default.nix` with the following contents:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
{ config, lib, ... }:
|
|
||||||
|
|
||||||
{
|
|
||||||
imports = [ ./withinbot.nix ];
|
|
||||||
|
|
||||||
users.groups.within = {};
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
The group listed here is optional, but I find that having a group like that can
|
|
||||||
help you better share resources and files between services.
|
|
||||||
|
|
||||||
Now we need a folder for storing secrets. Let's create that under the services
|
|
||||||
folder:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ mkdir secrets
|
|
||||||
```
|
|
||||||
|
|
||||||
And let's also add a gitignore file so that we don't accidentally commit these
|
|
||||||
secrets to the repo:
|
|
||||||
|
|
||||||
```gitignore
|
|
||||||
# common/services/secrets/.gitignore
|
|
||||||
*
|
|
||||||
```
|
|
||||||
|
|
||||||
Now we can put any secrets we want in the secrets folder without the risk of
|
|
||||||
committing them to the git repo.
|
|
||||||
|
|
||||||
### Service Manifest
|
|
||||||
|
|
||||||
Let's create `withinbot.nix` and set it up:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
{ config, lib, pkgs, ... }:
|
|
||||||
with lib; {
|
|
||||||
options.within.services.withinbot.enable =
|
|
||||||
mkEnableOption "Activates Withinbot (the furryhole chatbot)";
|
|
||||||
|
|
||||||
config = mkIf config.within.services.withinbot.enable {
|
|
||||||
|
|
||||||
};
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
This sets up an option called `within.services.withinbot.enable` which will only
|
|
||||||
add the service configuration if that option is set to `true`. This will allow
|
|
||||||
us to define a lot of services that are available, but none of their config will
|
|
||||||
be active unless they are explicitly enabled.
|
|
||||||
|
|
||||||
Now, let's create a user account for the service:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
# ...
|
|
||||||
config = ... {
|
|
||||||
users.users.withinbot = {
|
|
||||||
createHome = true;
|
|
||||||
description = "github.com/Xe/withinbot";
|
|
||||||
isSystemUser = true;
|
|
||||||
group = "within";
|
|
||||||
home = "/srv/within/withinbot";
|
|
||||||
extraGroups = [ "keys" ];
|
|
||||||
};
|
|
||||||
};
|
|
||||||
# ...
|
|
||||||
```
|
|
||||||
|
|
||||||
This will create a user named `withinbot` with the home directory
|
|
||||||
`/srv/within/withinbot`, the group `within` and also in the group `keys` so the
|
|
||||||
withinbot user can read deployment secrets.
|
|
||||||
|
|
||||||
Now let's add the deployment secrets to the configuration:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
# ...
|
|
||||||
config = ... {
|
|
||||||
users.users.withinbot = { ... };
|
|
||||||
|
|
||||||
deployment.keys.withinbot = {
|
|
||||||
text = builtins.readFile ./secrets/withinbot.env;
|
|
||||||
user = "withinbot";
|
|
||||||
group = "within";
|
|
||||||
permissions = "0640";
|
|
||||||
};
|
|
||||||
};
|
|
||||||
# ...
|
|
||||||
```
|
|
||||||
|
|
||||||
Assuming you have the configuration at `./secrets/withinbot.env`, this will
|
|
||||||
register the secrets into `/run/keys/withinbot` and also create a systemd
|
|
||||||
oneshot service named `withinbot-key`. This allows you to add the secret's
|
|
||||||
existence as a condition for withinbot to run. However, Nixops puts these keys
|
|
||||||
in `/run`, which by default is mounted using a temporary memory-only filesystem,
|
|
||||||
meaning these keys will need to be re-added to machines when they are rebooted.
|
|
||||||
Fortunately, `nixops reboot` will automatically add the keys back after the
|
|
||||||
reboot succeeds.
|
|
||||||
|
|
||||||
Now that we have everything else we need, let's add the service configuration:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
# ...
|
|
||||||
config = ... {
|
|
||||||
users.users.withinbot = { ... };
|
|
||||||
deployment.keys.withinbot = { ... };
|
|
||||||
|
|
||||||
systemd.services.withinbot = {
|
|
||||||
wantedBy = [ "multi-user.target" ];
|
|
||||||
after = [ "withinbot-key.service" ];
|
|
||||||
wants = [ "withinbot-key.service" ];
|
|
||||||
|
|
||||||
serviceConfig = {
|
|
||||||
User = "withinbot";
|
|
||||||
Group = "within";
|
|
||||||
Restart = "on-failure"; # automatically restart the bot when it dies
|
|
||||||
WorkingDirectory = "/srv/within/withinbot";
|
|
||||||
RestartSec = "30s";
|
|
||||||
};
|
|
||||||
|
|
||||||
script = let withinbot = pkgs.within.withinbot;
|
|
||||||
in ''
|
|
||||||
# load the environment variables from /run/keys/withinbot
|
|
||||||
export $(grep -v '^#' /run/keys/withinbot | xargs)
|
|
||||||
# service-specific configuration
|
|
||||||
export CAMPAIGN_FOLDER=${withinbot}/campaigns
|
|
||||||
# kick off the chatbot
|
|
||||||
exec ${withinbot}/bin/withinbot
|
|
||||||
'';
|
|
||||||
};
|
|
||||||
};
|
|
||||||
# ...
|
|
||||||
```
|
|
||||||
|
|
||||||
This will create the systemd configuration for the service so that it starts on
|
|
||||||
boot, waits to start until the secrets have been loaded into it, runs withinbot
|
|
||||||
as its own user and in the `within` group, and throttles the service restart so
|
|
||||||
that it doesn't incur Discord rate limits as easily. This will also put all
|
|
||||||
withinbot logs in journald, meaning that you can manage and monitor this service
|
|
||||||
like you would any other systemd service.
|
|
||||||
|
|
||||||
## Deploying the Service
|
|
||||||
|
|
||||||
In your target server's `configuration.nix` file, add an import of your services
|
|
||||||
directory:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
{
|
|
||||||
# ...
|
|
||||||
imports = [
|
|
||||||
# ...
|
|
||||||
/home/cadey/code/nixos-configs/common/services
|
|
||||||
];
|
|
||||||
# ...
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
And then enable the withinbot service:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
{
|
|
||||||
# ...
|
|
||||||
within.services = {
|
|
||||||
withinbot.enable = true;
|
|
||||||
};
|
|
||||||
# ...
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
[Make that a block so you can enable multiple services at once like <a
|
|
||||||
href="https://github.com/Xe/nixos-configs/blob/e111413e8b895f5a117dea534b17fc9d0b38d268/hosts/chrysalis/configuration.nix#L93-L96">this</a>!](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
Now you are free to deploy it to your network with `nixops deploy`:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ nixops deploy -d hexagone
|
|
||||||
```
|
|
||||||
|
|
||||||
<video controls width="100%">
|
|
||||||
<source src="https://cdn.christine.website/file/christine-static/img/nixops/tmp.Tr7HTFFd2c.webm"
|
|
||||||
type="video/webm">
|
|
||||||
<source src="https://cdn.christine.website/file/christine-static/img/nixops/tmp.Tr7HTFFd2c.mp4"
|
|
||||||
type="video/mp4">
|
|
||||||
Sorry, your browser doesn't support embedded videos.
|
|
||||||
</video>
|
|
||||||
|
|
||||||
|
|
||||||
And then you can verify the service is up with `systemctl status`:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ nixops ssh -d hexagone chrysalis -- systemctl status withinbot
|
|
||||||
● withinbot.service
|
|
||||||
Loaded: loaded (/nix/store/7ab7jzycpcci4f5wjwhjx3al7xy85ka7-unit-withinbot.service/withinbot.service; enabled; vendor preset: enabled)
|
|
||||||
Active: active (running) since Mon 2020-11-09 09:51:51 EST; 2h 29min ago
|
|
||||||
Main PID: 12295 (withinbot)
|
|
||||||
IP: 0B in, 0B out
|
|
||||||
Tasks: 13 (limit: 4915)
|
|
||||||
Memory: 7.9M
|
|
||||||
CPU: 4.456s
|
|
||||||
CGroup: /system.slice/withinbot.service
|
|
||||||
└─12295 /nix/store/qpq281hcb1grh4k5fm6ksky6w0981arp-withinbot-0.1.0/bin/withinbot
|
|
||||||
|
|
||||||
Nov 09 09:51:51 chrysalis systemd[1]: Started withinbot.service.
|
|
||||||
```
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
This basic template is enough to expand out to anything you would need and is
|
|
||||||
what I am using for my own network. This should be generic enough for most of
|
|
||||||
your needs. Check out the [NixOS manual](https://nixos.org/manual/nixos/stable/)
|
|
||||||
for more examples and things you can do with this. The [Nixops
|
|
||||||
manual](https://releases.nixos.org/nixops/nixops-1.7/manual/manual.html) is also
|
|
||||||
a good read. It can also set up deployments with VirtualBox, libvirtd, AWS,
|
|
||||||
Digital Ocean, and even Google Cloud.
|
|
||||||
|
|
||||||
The cloud is the limit! Be well.
|
|
||||||
|
|
@ -1,533 +0,0 @@
|
||||||
---
|
|
||||||
title: "My NixOS Desktop Flow"
|
|
||||||
date: 2020-04-25
|
|
||||||
series: howto
|
|
||||||
---
|
|
||||||
|
|
||||||
# My NixOS Desktop Flow
|
|
||||||
|
|
||||||
Before I built my current desktop, I had been using a [2013 Mac Pro][macpro2013]
|
|
||||||
for at least 7 years. This machine has seen me through living in a few cities
|
|
||||||
(Bellevue, Mountain View and Montreal), but it was starting to show its age. Its
|
|
||||||
12 core Xeon is really no slouch (scoring about 5 minutes in my "compile the
|
|
||||||
linux kernel" test), but with Intel security patches it was starting to get
|
|
||||||
slower and slower as time went on.
|
|
||||||
|
|
||||||
[macpro2013]: https://www.apple.com/mac-pro-2013/specs/
|
|
||||||
|
|
||||||
So in March (just before the situation started) I ordered the parts for my new
|
|
||||||
tower and built my current desktop machine. From the start, I wanted it to run
|
|
||||||
Linux and have 64 GB of ram, mostly so I could write and test programs without
|
|
||||||
having to worry about ram exhaustion.
|
|
||||||
|
|
||||||
When the parts were almost in, I had decided to really start digging into
|
|
||||||
[NixOS][nixos]. Friends on IRC and Discord had been trying to get me to use it
|
|
||||||
for years, and I was really impressed with a simple setup that I had in a
|
|
||||||
virtual machine. So I decided to jump head-first down that rabbit hole, and I'm
|
|
||||||
honestly really glad I did.
|
|
||||||
|
|
||||||
[nixos]: https://nixos.org
|
|
||||||
|
|
||||||
NixOS is built on a more functional approach to package management called
|
|
||||||
[Nix][nix]. Parts of the configuration can be easily broken off into modules
|
|
||||||
that can be reused across machines in a deployment. If [Ansible][ansible] or
|
|
||||||
other tools like it let you customize an existing Linux distribution to meet
|
|
||||||
your needs, NixOS allows you to craft your own Linux distribution around your
|
|
||||||
needs.
|
|
||||||
|
|
||||||
[nix]: https://nixos.org/nix/
|
|
||||||
[ansible]: https://www.ansible.com/
|
|
||||||
|
|
||||||
Unfortunately, the Nix and NixOS documentation is a bit more dense than most
|
|
||||||
other Linux programs/distributions are, and it's a bit easy to get lost in it.
|
|
||||||
I'm going to attempt to explain a lot of the guiding principles behind Nix and
|
|
||||||
NixOS and how they fit into how I use NixOS on my desktop.
|
|
||||||
|
|
||||||
## What is a Package?
|
|
||||||
|
|
||||||
Earlier, I mentioned that Nix is a _functional_ package manager. This means that
|
|
||||||
Nix views packages as a combination of inputs to get an output:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
This is how most package managers work (even things like Windows installer
|
|
||||||
files), but Nix goes a step further by disallowing package builds to access the
|
|
||||||
internet. This allows Nix packages to be a lot more reproducible; meaning if you
|
|
||||||
have the same inputs (source code, build script and patches) you should _always_
|
|
||||||
get the same output byte-for-byte every time you build the same package at the
|
|
||||||
same version.
|
|
||||||
|
|
||||||
### A Simple Package
|
|
||||||
|
|
||||||
Let's consider a simple example, my [gruvbox-inspired CSS file][gruvboxcss]'s
|
|
||||||
[`default.nix`][gcssdefaultnix] file':
|
|
||||||
|
|
||||||
[gruvboxcss]: https://github.com/Xe/gruvbox-css
|
|
||||||
[gcssdefaultnix]: https://github.com/Xe/gruvbox-css/blob/master/default.nix
|
|
||||||
|
|
||||||
```nix
|
|
||||||
{ pkgs ? import <nixpkgs> { } }:
|
|
||||||
|
|
||||||
pkgs.stdenv.mkDerivation {
|
|
||||||
pname = "gruvbox-css";
|
|
||||||
version = "latest";
|
|
||||||
src = ./.;
|
|
||||||
phases = "installPhase";
|
|
||||||
installPhase = ''
|
|
||||||
mkdir -p $out
|
|
||||||
cp -rf $src/gruvbox.css $out/gruvbox.css
|
|
||||||
'';
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
This creates a package named `gruvbox-css` with the version `latest`. Let's
|
|
||||||
break this down its `default.nix` line by line:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
{ pkgs ? import <nixpkgs> { } }:
|
|
||||||
```
|
|
||||||
|
|
||||||
This creates a function that either takes in the `pkgs` object or tells Nix to
|
|
||||||
import the standard package library [nixpkgs][nixpkgs] as `pkgs`. nixpkgs
|
|
||||||
includes a lot of utilities like a standard packaging environment, special
|
|
||||||
builders for things like snaps and Docker images as well as one of the largest
|
|
||||||
package sets out there.
|
|
||||||
|
|
||||||
[nixpkgs]: https://nixos.org/nixpkgs/
|
|
||||||
|
|
||||||
```nix
|
|
||||||
pkgs.stdenv.mkDerivation {
|
|
||||||
# ...
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
This runs the [`stdenv.mkDerivation`][mkderiv] function with some arguments in an
|
|
||||||
object. The "standard environment" comes with tools like GCC, bash, coreutils,
|
|
||||||
find, sed, grep, awk, tar, make, patch and all of the major compression tools.
|
|
||||||
This means that our package builds can build C/C++ programs, copy files to the
|
|
||||||
output, and extract downloaded source files by default. You can add other inputs
|
|
||||||
to this environment if you need to, but for now it works as-is.
|
|
||||||
|
|
||||||
[mkderiv]: https://nixos.org/nixpkgs/manual/#sec-using-stdenv
|
|
||||||
|
|
||||||
Let's specify the name and version of this package:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
pname = "gruvbox-css";
|
|
||||||
version = "latest";
|
|
||||||
```
|
|
||||||
|
|
||||||
`pname` stands for "package name". It is combined with the version to create the
|
|
||||||
resulting package name. In this case it would be `gruvbox-css-latest`.
|
|
||||||
|
|
||||||
Let's tell Nix how to build this package:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
src = ./.;
|
|
||||||
phases = "installPhase";
|
|
||||||
installPhase = ''
|
|
||||||
mkdir -p $out
|
|
||||||
cp -rf $src/gruvbox.css $out/gruvbox.css
|
|
||||||
'';
|
|
||||||
```
|
|
||||||
|
|
||||||
The `src` attribute tells Nix where the source code of the package is stored.
|
|
||||||
Sometimes this can be a URL to a compressed archive on the internet, sometimes
|
|
||||||
it can be a git repo, but for now it's the current working directory `./.`.
|
|
||||||
|
|
||||||
This is a CSS file, it doesn't make sense to have to build these, so we skip the
|
|
||||||
build phase and tell Nix to directly install the package to its output folder:
|
|
||||||
|
|
||||||
```shell
|
|
||||||
mkdir -p $out
|
|
||||||
cp -rf $src/gruvbox.css $out/gruvbox.css
|
|
||||||
```
|
|
||||||
|
|
||||||
This two-liner shell script creates the output directory (usually exposed as
|
|
||||||
`$out`) and then copies `gruvbox.css` into it. When we run this through Nix
|
|
||||||
with`nix-build`, we get output that looks something like this:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ nix-build ./default.nix
|
|
||||||
these derivations will be built:
|
|
||||||
/nix/store/c99n4ixraigf4jb0jfjxbkzicd79scpj-gruvbox-css.drv
|
|
||||||
building '/nix/store/c99n4ixraigf4jb0jfjxbkzicd79scpj-gruvbox-css.drv'...
|
|
||||||
installing
|
|
||||||
/nix/store/ng5qnhwyrk9zaidjv00arhx787r0412s-gruvbox-css
|
|
||||||
```
|
|
||||||
|
|
||||||
And `/nix/store/ng5qnhwyrk9zaidjv00arhx787r0412s-gruvbox-css` is the output
|
|
||||||
package. Looking at its contents with `ls`, we see this:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ ls /nix/store/ng5qnhwyrk9zaidjv00arhx787r0412s-gruvbox-css
|
|
||||||
gruvbox.css
|
|
||||||
```
|
|
||||||
|
|
||||||
### A More Complicated Package
|
|
||||||
|
|
||||||
For a more complicated package, let's look at the [build directions of the
|
|
||||||
website you are reading right now][sitedefaultnix]:
|
|
||||||
|
|
||||||
[sitedefaultnix]: https://github.com/Xe/site/blob/master/site.nix
|
|
||||||
|
|
||||||
```nix
|
|
||||||
{ pkgs ? import (import ./nix/sources.nix).nixpkgs }:
|
|
||||||
with pkgs;
|
|
||||||
|
|
||||||
assert lib.versionAtLeast go.version "1.13";
|
|
||||||
|
|
||||||
buildGoPackage rec {
|
|
||||||
pname = "christinewebsite";
|
|
||||||
version = "latest";
|
|
||||||
|
|
||||||
goPackagePath = "christine.website";
|
|
||||||
src = ./.;
|
|
||||||
goDeps = ./nix/deps.nix;
|
|
||||||
allowGoReference = false;
|
|
||||||
|
|
||||||
preBuild = ''
|
|
||||||
export CGO_ENABLED=0
|
|
||||||
buildFlagsArray+=(-pkgdir "$TMPDIR")
|
|
||||||
'';
|
|
||||||
|
|
||||||
postInstall = ''
|
|
||||||
cp -rf $src/blog $bin/blog
|
|
||||||
cp -rf $src/css $bin/css
|
|
||||||
cp -rf $src/gallery $bin/gallery
|
|
||||||
cp -rf $src/signalboost.dhall $bin/signalboost.dhall
|
|
||||||
cp -rf $src/static $bin/static
|
|
||||||
cp -rf $src/talks $bin/talks
|
|
||||||
cp -rf $src/templates $bin/templates
|
|
||||||
'';
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
Breaking it down, we see some similarities to the gruvbox-css package from
|
|
||||||
above, but there's a few more interesting lines I want to point out:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
{ pkgs ? import (import ./nix/sources.nix).nixpkgs }:
|
|
||||||
```
|
|
||||||
|
|
||||||
My website uses a pinned or fixed version of nixpkgs. This allows my website's
|
|
||||||
deployment to be stable even if nixpkgs changes something that could cause it to
|
|
||||||
break.
|
|
||||||
|
|
||||||
```nix
|
|
||||||
with pkgs;
|
|
||||||
```
|
|
||||||
|
|
||||||
[With expressions][nixwith] are one of the more interesting parts of Nix.
|
|
||||||
Essentially, they let you say "everything in this object should be put into
|
|
||||||
scope". So if you have an expression that does this:
|
|
||||||
|
|
||||||
[nixwith]: https://nixos.org/nix/manual/#idm140737321975440
|
|
||||||
|
|
||||||
```nix
|
|
||||||
let
|
|
||||||
foo = {
|
|
||||||
ponies = "awesome";
|
|
||||||
};
|
|
||||||
in with foo; "ponies are ${ponies}!"
|
|
||||||
```
|
|
||||||
|
|
||||||
You get the result `"ponies are awesome!"`. I use `with pkgs` here to use things
|
|
||||||
directly from nixpkgs without having to say `pkgs.` in front of a lot of things.
|
|
||||||
|
|
||||||
```nix
|
|
||||||
assert lib.versionAtLeast go.version "1.13";
|
|
||||||
```
|
|
||||||
|
|
||||||
This line will make the build fail if Nix is using any Go version less than
|
|
||||||
1.13. I'm pretty sure my website's code could function on older versions of Go,
|
|
||||||
but the runtime improvements are important to it, so let's fail loudly just in
|
|
||||||
case.
|
|
||||||
|
|
||||||
```nix
|
|
||||||
buildGoPackage {
|
|
||||||
# ...
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
[`buildGoPackage`](https://nixos.org/nixpkgs/manual/#ssec-go-legacy) builds a Go
|
|
||||||
package into a Nix package. It takes in the [Go package path][gopkgpath], list
|
|
||||||
of dependencies and if the resulting package is allowed to depend on the Go
|
|
||||||
compiler or not.
|
|
||||||
|
|
||||||
[gopkgpath]: https://github.com/golang/go/wiki/GOPATH#directory-layout
|
|
||||||
|
|
||||||
It will then compile the Go program (and all of its dependencies) into a binary
|
|
||||||
and put that in the resulting package. This website is more than just the source
|
|
||||||
code, it's also got assets like CSS files and the image earlier in the post.
|
|
||||||
Those files are copied in the `postInstall` phase:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
postInstall = ''
|
|
||||||
cp -rf $src/blog $bin/blog
|
|
||||||
cp -rf $src/css $bin/css
|
|
||||||
cp -rf $src/gallery $bin/gallery
|
|
||||||
cp -rf $src/signalboost.dhall $bin/signalboost.dhall
|
|
||||||
cp -rf $src/static $bin/static
|
|
||||||
cp -rf $src/talks $bin/talks
|
|
||||||
cp -rf $src/templates $bin/templates
|
|
||||||
'';
|
|
||||||
```
|
|
||||||
|
|
||||||
This results in all of the files that my website needs to run existing in the
|
|
||||||
right places.
|
|
||||||
|
|
||||||
### Other Packages
|
|
||||||
|
|
||||||
For more kinds of packages that you can build, see the [Languages and
|
|
||||||
Frameworks][nixpkgslangsframeworks] chapter of the nixpkgs documentation.
|
|
||||||
|
|
||||||
[nixpkgslangsframeworks]: https://nixos.org/nixpkgs/manual/#chap-language-support
|
|
||||||
|
|
||||||
If your favorite language isn't shown there, you can make your own build script
|
|
||||||
and do it more manually. See [here][nixpillscustombuilder] for more information
|
|
||||||
on how to do that.
|
|
||||||
|
|
||||||
[nixpillscustombuilder]: https://nixos.org/nixos/nix-pills/working-derivation.html#idm140737320334640
|
|
||||||
|
|
||||||
## `nix-env` And Friends
|
|
||||||
|
|
||||||
Building your own packages is nice and all, but what about using packages
|
|
||||||
defined in nixpkgs? Nix includes a few tools that help you find, install,
|
|
||||||
upgrade and remove packages as well as `nix-build` to build new ones.
|
|
||||||
|
|
||||||
### `nix search`
|
|
||||||
|
|
||||||
When looking for a package to install, use `$ nix search name` to see if it's
|
|
||||||
already packaged. For example, let's look for [graphviz][graphviz], a popular
|
|
||||||
diagramming software:
|
|
||||||
|
|
||||||
[graphviz]: https://graphviz.org/
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ nix search graphviz
|
|
||||||
|
|
||||||
* nixos.graphviz (graphviz)
|
|
||||||
Graph visualization tools
|
|
||||||
|
|
||||||
* nixos.graphviz-nox (graphviz)
|
|
||||||
Graph visualization tools
|
|
||||||
|
|
||||||
* nixos.graphviz_2_32 (graphviz)
|
|
||||||
Graph visualization tools
|
|
||||||
```
|
|
||||||
|
|
||||||
There are several results here! These are different because sometimes you may
|
|
||||||
want some features of graphviz, but not all of them. For example, a server
|
|
||||||
installation of graphviz wouldn't need X windows support.
|
|
||||||
|
|
||||||
The first line of the output is the attribute. This is the attribute that the
|
|
||||||
package is imported to inside nixpkgs. This allows multiple packages in
|
|
||||||
different contexts to exist in nixpkgs at the same time, for example with python
|
|
||||||
2 and python 3 versions of a library.
|
|
||||||
|
|
||||||
The second line is a description of the package from its metadata section.
|
|
||||||
|
|
||||||
The `nix` tool allows you to do a lot more than just this, but for now this is
|
|
||||||
the most important thing.
|
|
||||||
|
|
||||||
### `nix-env -i`
|
|
||||||
|
|
||||||
`nix-env` is a rather big tool that does a lot of things (similar to pacman in
|
|
||||||
Arch Linux), so I'm going to break things down into separate sections.
|
|
||||||
|
|
||||||
Let's pick an instance graphviz from before and install it using `nix-env`:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ nix-env -iA nixos.graphviz
|
|
||||||
installing 'graphviz-2.42.2'
|
|
||||||
these paths will be fetched (5.00 MiB download, 13.74 MiB unpacked):
|
|
||||||
/nix/store/980jk7qbcfrlnx8jsmdx92q96wsai8mx-gts-0.7.6
|
|
||||||
/nix/store/fij1p8f0yjpv35n342ii9pwfahj8rlbb-graphviz-2.42.2
|
|
||||||
/nix/store/jy35xihlnb3az0vdksyg9rd2f38q2c01-libdevil-1.7.8
|
|
||||||
/nix/store/s895dnwlprwpfp75pzq70qzfdn8mwfzc-lcms-1.19
|
|
||||||
copying path '/nix/store/980jk7qbcfrlnx8jsmdx92q96wsai8mx-gts-0.7.6' from 'https://cache.nixos.org'...
|
|
||||||
copying path '/nix/store/s895dnwlprwpfp75pzq70qzfdn8mwfzc-lcms-1.19' from 'https://cache.nixos.org'...
|
|
||||||
copying path '/nix/store/jy35xihlnb3az0vdksyg9rd2f38q2c01-libdevil-1.7.8' from 'https://cache.nixos.org'...
|
|
||||||
copying path '/nix/store/fij1p8f0yjpv35n342ii9pwfahj8rlbb-graphviz-2.42.2' from 'https://cache.nixos.org'...
|
|
||||||
building '/nix/store/r4fqdwpicqjpa97biis1jlxzb4ywi92b-user-environment.drv'...
|
|
||||||
created 664 symlinks in user environment
|
|
||||||
```
|
|
||||||
|
|
||||||
And now let's see where the `dot` tool from graphviz is installed to:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ which dot
|
|
||||||
/home/cadey/.nix-profile/bin/dot
|
|
||||||
|
|
||||||
$ readlink /home/cadey/.nix-profile/bin/dot
|
|
||||||
/nix/store/fij1p8f0yjpv35n342ii9pwfahj8rlbb-graphviz-2.42.2/bin/dot
|
|
||||||
```
|
|
||||||
|
|
||||||
This lets you install tools into the system-level Nix store without affecting
|
|
||||||
other user's environments, even if they depend on a different version of
|
|
||||||
graphviz.
|
|
||||||
|
|
||||||
### `nix-env -e`
|
|
||||||
|
|
||||||
`nix-env -e` lets you uninstall packages installed with `nix-env -i`. Let's
|
|
||||||
uninstall graphviz:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ nix-env -e graphviz
|
|
||||||
```
|
|
||||||
|
|
||||||
Now the `dot` tool will be gone from your shell:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ which dot
|
|
||||||
which: no dot in (/run/wrappers/bin:/home/cadey/.nix-profile/bin:/etc/profiles/per-user/cadey/bin:/nix/var/nix/profiles/default/bin:/run/current-system/sw/bin)
|
|
||||||
```
|
|
||||||
|
|
||||||
And it's like graphviz was never installed.
|
|
||||||
|
|
||||||
Notice that these package management commands are done at the _user_ level
|
|
||||||
because they are only affecting the currently logged-in user. This allows users
|
|
||||||
to install their own editors or other tools without having to get admins
|
|
||||||
involved.
|
|
||||||
|
|
||||||
## Adding up to NixOS
|
|
||||||
|
|
||||||
NixOS builds on top of Nix and its command line tools to make an entire Linux
|
|
||||||
distribution that can be perfectly crafted to your needs. NixOS machines are
|
|
||||||
configured using a [configuration.nix][confignix] file that contains the
|
|
||||||
following kinds of settings:
|
|
||||||
|
|
||||||
[confignix]: https://nixos.org/nixos/manual/index.html#ch-configuration
|
|
||||||
|
|
||||||
- packages installed to the system
|
|
||||||
- user accounts on the system
|
|
||||||
- allowed SSH public keys for users on the system
|
|
||||||
- services activated on the system
|
|
||||||
- configuration for services on the system
|
|
||||||
- magic unix flags like the number of allowed file descriptors per process
|
|
||||||
- what drives to mount where
|
|
||||||
- network configuration
|
|
||||||
- ACME certificates
|
|
||||||
|
|
||||||
[and so much more](https://nixos.org/nixos/options.html#)
|
|
||||||
|
|
||||||
At a high level, machines are configured by setting options like this:
|
|
||||||
|
|
||||||
```
|
|
||||||
# basic-lxc-image.nix
|
|
||||||
{ config, pkgs, ... }:
|
|
||||||
|
|
||||||
{
|
|
||||||
networking.hostName = "example-for-blog";
|
|
||||||
environment.systemPackages = with pkgs; [ wget vim ];
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
This would specify a simple NixOS machine with the hostname `example-for-blog`
|
|
||||||
and with wget and vim installed. This is nowhere near enough to boot an entire
|
|
||||||
system, but is good enough for describing the base layout of a basic [LXC][lxc]
|
|
||||||
image.
|
|
||||||
|
|
||||||
[lxc]: https://linuxcontainers.org/lxc/introduction/
|
|
||||||
|
|
||||||
For a more complete example of NixOS configurations, see
|
|
||||||
[here](https://github.com/Xe/nixos-configs/tree/master/hosts) or repositories on
|
|
||||||
[this handy NixOS wiki page](https://nixos.wiki/wiki/Configuration_Collection).
|
|
||||||
|
|
||||||
The main configuration.nix file (usually at `/etc/nixos/configuration.nix`) can also
|
|
||||||
import other NixOS modules using the `imports` attribute:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
# better-vm.nix
|
|
||||||
{ config, pkgs, ... }:
|
|
||||||
|
|
||||||
{
|
|
||||||
imports = [
|
|
||||||
./basic-lxc-image.nix
|
|
||||||
];
|
|
||||||
|
|
||||||
networking.hostName = "better-vm";
|
|
||||||
services.nginx.enable = true;
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
And the `better-vm.nix` file would describe a machine with the hostname
|
|
||||||
`better-vm` that has wget and vim installed, but is also running nginx with its
|
|
||||||
default configuration.
|
|
||||||
|
|
||||||
Internally, every one of these options will be fed into auto-generated Nix
|
|
||||||
packages that will describe the system configuration bit by bit.
|
|
||||||
|
|
||||||
### `nixos-rebuild`
|
|
||||||
|
|
||||||
One of the handy features about Nix is that every package exists in its own part
|
|
||||||
of the Nix store. This allows you to leave the older versions of a package
|
|
||||||
laying around so you can roll back to them if you need to. `nixos-rebuild` is
|
|
||||||
the tool that helps you commit configuration changes to the system as well as
|
|
||||||
roll them back.
|
|
||||||
|
|
||||||
If you want to upgrade your entire system:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ sudo nixos-rebuild switch --upgrade
|
|
||||||
```
|
|
||||||
|
|
||||||
This tells nixos-rebuild to upgrade the package channels, use those to create a
|
|
||||||
new base system description, switch the running system to it and start/restart/stop
|
|
||||||
any services that were added/upgraded/removed during the upgrade. Every time you
|
|
||||||
rebuild the configuration, you create a new "generation" of configuration that
|
|
||||||
you can roll back to just as easily:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ sudo nixos-rebuild switch --rollback
|
|
||||||
```
|
|
||||||
|
|
||||||
### Garbage Collection
|
|
||||||
|
|
||||||
As upgrades happen and old generations pile up, this may end up taking up a lot
|
|
||||||
of unwanted disk (and boot menu) space. To free up this space, you can use
|
|
||||||
`nix-collect-garbage`:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ sudo nix-collect-garbage
|
|
||||||
< cleans up packages not referenced by anything >
|
|
||||||
|
|
||||||
$ sudo nix-collect-garbage -d
|
|
||||||
< deletes old generations and then cleans up packages not referenced by anything >
|
|
||||||
```
|
|
||||||
|
|
||||||
The latter is a fairly powerful command and can wipe out older system states.
|
|
||||||
Only run this if you are sure you don't want to go back to an older setup.
|
|
||||||
|
|
||||||
## How I Use It
|
|
||||||
|
|
||||||
Each of these things builds on top of eachother to make the base platform that I
|
|
||||||
built my desktop environment on. I have the configuration for [my
|
|
||||||
shell][xefish], [emacs][xemacs], [my window manager][xedwm] and just about [every
|
|
||||||
program I use on a regular basis][xecommon] defined in their own NixOS modules so I can
|
|
||||||
pick and choose things for new machines.
|
|
||||||
|
|
||||||
[xefish]: https://github.com/Xe/xepkgs/tree/master/modules/fish
|
|
||||||
[xemacs]: https://github.com/Xe/nixos-configs/tree/master/common/users/cadey/spacemacs
|
|
||||||
[xedwm]: https://github.com/Xe/xepkgs/tree/master/modules/dwm
|
|
||||||
[xecommon]: https://github.com/Xe/nixos-configs/tree/master/common
|
|
||||||
|
|
||||||
When I want to change part of my config, I edit the files responsible for that
|
|
||||||
part of the config and then rebuild the system to test it. If things work
|
|
||||||
properly, I commit those changes and then continue using the system like normal.
|
|
||||||
|
|
||||||
This is a little bit more work in the short term, but as a result I get a setup
|
|
||||||
that is easier to recreate on more machines in the future. It took me a half
|
|
||||||
hour or so to get the configuration for [zathura][zathura] right, but now I have
|
|
||||||
[a zathura
|
|
||||||
module](https://github.com/Xe/nixos-configs/tree/master/common/users/cadey/zathura)
|
|
||||||
that lets me get exactly the setup I want every time.
|
|
||||||
|
|
||||||
[zathura]: https://pwmt.org/projects/zathura/
|
|
||||||
|
|
||||||
## TL;DR
|
|
||||||
|
|
||||||
Nix and NixOS ruined me. It's hard to go back.
|
|
||||||
|
|
@ -1,146 +0,0 @@
|
||||||
---
|
|
||||||
title: Discord Webhooks via NixOS and Systemd Timers
|
|
||||||
date: 2020-11-30
|
|
||||||
series: howto
|
|
||||||
tags:
|
|
||||||
- nixos
|
|
||||||
- discord
|
|
||||||
- systemd
|
|
||||||
---
|
|
||||||
|
|
||||||
# Discord Webhooks via NixOS and Systemd Timers
|
|
||||||
|
|
||||||
Recently I needed to set up a Discord message on a cronjob as a part of
|
|
||||||
moderating a guild I've been in for years. I've done this before using
|
|
||||||
[cronjobs](/blog/howto-automate-discord-webhook-cron-2018-03-29), however this
|
|
||||||
time we will be using [NixOS](https://nixos.org/) and [systemd
|
|
||||||
timers](https://wiki.archlinux.org/index.php/Systemd/Timers). Here's what you
|
|
||||||
will need to follow along:
|
|
||||||
|
|
||||||
- A machine running NixOS
|
|
||||||
- A [Discord](https://discord.com/) account
|
|
||||||
- A
|
|
||||||
[webhook](https://support.discord.com/hc/en-us/articles/228383668-Intro-to-Webhooks)
|
|
||||||
configured for a channel
|
|
||||||
- A message you want to send to Discord
|
|
||||||
|
|
||||||
[If you don't have moderation permissions in any guilds, make your own for
|
|
||||||
testing! You will need the "Manage Webhooks" permission to create a
|
|
||||||
webhook.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
## Setting Up Timers
|
|
||||||
|
|
||||||
systemd timers are like cronjobs, except they trigger systemd services instead
|
|
||||||
of shell commands. For this example, let's create a daily webhook reminder to
|
|
||||||
check on your Animal Crossing island at 9 am.
|
|
||||||
|
|
||||||
Let's create the systemd service at the end of the machine's
|
|
||||||
`configuration.nix`:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
systemd.services.acnh-island-check-reminder = {
|
|
||||||
serviceConfig.Type = "oneshot";
|
|
||||||
script = ''
|
|
||||||
MESSAGE="It's time to check on your island! Check those stonks!"
|
|
||||||
WEBHOOK="${builtins.readFile /home/cadey/prefix/secrets/acnh-webhook-secret}"
|
|
||||||
USERNAME="Domo"
|
|
||||||
|
|
||||||
${pkgs.curl}/bin/curl \
|
|
||||||
-X POST \
|
|
||||||
-F "content=$MESSAGE" \
|
|
||||||
-F "username=$USERNAME" \
|
|
||||||
"$WEBHOOK"
|
|
||||||
'';
|
|
||||||
};
|
|
||||||
```
|
|
||||||
|
|
||||||
[This service is a <a href="https://stackoverflow.com/a/39050387">oneshot</a>
|
|
||||||
unit, meaning systemd will launch this once and not expect it to always stay
|
|
||||||
running.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
Now let's create a timer for this service. We need to do the following:
|
|
||||||
|
|
||||||
- Associate the timer with that service
|
|
||||||
- Assign a schedule to the timer
|
|
||||||
|
|
||||||
Add this to the end of your `configuration.nix`:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
systemd.timers.acnh-island-check-reminder = {
|
|
||||||
wantedBy = [ "timers.target" ];
|
|
||||||
partOf = [ "acnh-island-check-reminder.service" ];
|
|
||||||
timerConfig.OnCalendar = "TODO(Xe): this";
|
|
||||||
};
|
|
||||||
```
|
|
||||||
|
|
||||||
Before we mentioned that we want to trigger this reminder every morning at 9 am.
|
|
||||||
systemd timers specify their calendar config in the following format:
|
|
||||||
|
|
||||||
```
|
|
||||||
DayOfWeek Year-Month-Day Hour:Minute:Second
|
|
||||||
```
|
|
||||||
|
|
||||||
So for something that triggers every day at 9 AM, it would look like this:
|
|
||||||
|
|
||||||
```
|
|
||||||
*-*-* 8:00:00
|
|
||||||
```
|
|
||||||
|
|
||||||
[You can ignore the day of the week if it's not
|
|
||||||
relevant!](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
So our final timer definition would look like this:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
systemd.timers.acnh-island-check-reminder = {
|
|
||||||
wantedBy = [ "timers.target" ];
|
|
||||||
partOf = [ "acnh-island-check-reminder.service" ];
|
|
||||||
timerConfig.OnCalendar = "*-*-* 8:00:00";
|
|
||||||
};
|
|
||||||
```
|
|
||||||
|
|
||||||
## Deployment and Testing
|
|
||||||
|
|
||||||
Now we can deploy this with `nixos-rebuild`:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ sudo nixos-rebuild switch
|
|
||||||
```
|
|
||||||
|
|
||||||
You should see a line that says something like this in the `nixos-rebuild`
|
|
||||||
output:
|
|
||||||
|
|
||||||
```
|
|
||||||
starting the following units: acnh-island-check-reminder.timer
|
|
||||||
```
|
|
||||||
|
|
||||||
Let's test the service out using `systemctl`:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ sudo systemctl start acnh-island-check-reminder.service
|
|
||||||
```
|
|
||||||
|
|
||||||
And you should then see a message on Discord. If you don't see a message, check
|
|
||||||
the logs using `journalctl`:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ journalctl -u acnh-island-check-reminder.service
|
|
||||||
```
|
|
||||||
|
|
||||||
If you see an error that looks like this:
|
|
||||||
|
|
||||||
```
|
|
||||||
curl: (26) Failed to open/read local data from file/application
|
|
||||||
```
|
|
||||||
|
|
||||||
This usually means that you tried to do a role or user mention at the beginning
|
|
||||||
of the message and curl tried to interpret that as a file input. Add a word like
|
|
||||||
"hey" at the beginning of the line to disable this behavior. See
|
|
||||||
[here](https://stackoverflow.com/questions/6408904/send-request-to-curl-with-post-data-sourced-from-a-file)
|
|
||||||
for more information.
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
Also happy December! My site has the [snow
|
|
||||||
CSS](https://christine.website/blog/let-it-snow-2018-12-17) loaded for the
|
|
||||||
month. Enjoy!
|
|
||||||
|
|
@ -1,332 +0,0 @@
|
||||||
---
|
|
||||||
title: Encrypted Secrets with NixOS
|
|
||||||
date: 2021-01-20
|
|
||||||
series: nixos
|
|
||||||
tags:
|
|
||||||
- age
|
|
||||||
- ed25519
|
|
||||||
---
|
|
||||||
|
|
||||||
# Encrypted Secrets with NixOS
|
|
||||||
|
|
||||||
One of the best things about NixOS is the fact that it's so easy to do
|
|
||||||
configuration management using it. The Nix store (where all your packages live)
|
|
||||||
has a huge flaw for secret management though: everything in the Nix store is
|
|
||||||
globally readable. This means that anyone logged into or running code on the
|
|
||||||
system could read any secret in the Nix store without any limits. This is
|
|
||||||
sub-optimal if your goal is to keep secret values secret. There have been a few
|
|
||||||
approaches to this over the years, but I want to describe how I'm doing it.
|
|
||||||
Here are my goals and implementation for this setup and how a few other secret
|
|
||||||
management strategies don't quite pan out.
|
|
||||||
|
|
||||||
At a high level I have these goals:
|
|
||||||
|
|
||||||
* It should be trivial to declare new secrets
|
|
||||||
* Secrets should never be globally readable in any useful form
|
|
||||||
* If I restart the machine, I should not need to take manual human action to
|
|
||||||
ensure all of the services come back online
|
|
||||||
* GPG should be avoided at all costs
|
|
||||||
|
|
||||||
As a side goal being able to roll back secret changes would also be nice.
|
|
||||||
|
|
||||||
The two biggest tools that offer a way to help with secret management on NixOS
|
|
||||||
that come to mind are NixOps and Morph.
|
|
||||||
|
|
||||||
[NixOps](https://github.com/NixOS/nixops) is a tool that helps administrators
|
|
||||||
operate NixOS across multiple servers at once. I use NixOps extensively in my
|
|
||||||
own setup. It calls deployment secrets "keys" and they are documented
|
|
||||||
[here](https://hydra.nixos.org/build/115931128/download/1/manual/manual.html#idm140737322649152).
|
|
||||||
At a high level they are declared like this:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
deployment.keys.example = {
|
|
||||||
text = "this is a super sekrit value :)";
|
|
||||||
user = "example";
|
|
||||||
group = "keys";
|
|
||||||
permissions = "0400";
|
|
||||||
};
|
|
||||||
```
|
|
||||||
|
|
||||||
This will create a new secret in `/run/keys` that will contain our super secret
|
|
||||||
value.
|
|
||||||
|
|
||||||
[Wait, isn't `/run` an ephemeral filesystem? What happens when the system
|
|
||||||
reboots?](conversation://Mara/hmm)
|
|
||||||
|
|
||||||
Let's make an example system and find out! So let's say we have that `example`
|
|
||||||
secret from earlier and want to use it in a job. The job definition could look
|
|
||||||
something like this:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
# create a service-specific user
|
|
||||||
users.users.example.isSystemUser = true;
|
|
||||||
|
|
||||||
# without this group the secret can't be read
|
|
||||||
users.users.example.extraGroups = [ "keys" ];
|
|
||||||
|
|
||||||
systemd.services.example = {
|
|
||||||
wantedBy = [ "multi-user.target" ];
|
|
||||||
after = [ "example-key.service" ];
|
|
||||||
wants = [ "example-key.service" ];
|
|
||||||
|
|
||||||
serviceConfig.User = "example";
|
|
||||||
serviceConfig.Type = "oneshot";
|
|
||||||
|
|
||||||
script = ''
|
|
||||||
stat /run/keys/example
|
|
||||||
'';
|
|
||||||
};
|
|
||||||
```
|
|
||||||
|
|
||||||
This creates a user called `example` and gives it permission to read deployment
|
|
||||||
keys. It also creates a systemd service called `example.service` and runs
|
|
||||||
[`stat(1)`](https://linux.die.net/man/1/stat) to show the permissions of the
|
|
||||||
service and the key file. It also runs as our `example` user. To avoid systemd
|
|
||||||
thinking our service failed, we're also going to mark it as a
|
|
||||||
[oneshot](https://www.digitalocean.com/community/tutorials/understanding-systemd-units-and-unit-files#the-service-section).
|
|
||||||
|
|
||||||
Altogether it could look something like
|
|
||||||
[this](https://gist.github.com/Xe/4a71d7741e508d9002be91b62248144a). Let's see
|
|
||||||
what `systemctl` has to report:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ nixops ssh -d blog-example pa -- systemctl status example
|
|
||||||
● example.service
|
|
||||||
Loaded: loaded (/nix/store/j4a8f6mnaw3v4sz7dqlnz95psh72xglw-unit-example.service/example.service; enabled; vendor preset: enabled)
|
|
||||||
Active: inactive (dead) since Wed 2021-01-20 20:53:54 UTC; 37s ago
|
|
||||||
Process: 2230 ExecStart=/nix/store/1yg89z4dsdp1axacqk07iq5jqv58q169-unit-script-example-start/bin/example-start (code=exited, status=0/SUCCESS)
|
|
||||||
Main PID: 2230 (code=exited, status=0/SUCCESS)
|
|
||||||
IP: 0B in, 0B out
|
|
||||||
CPU: 3ms
|
|
||||||
|
|
||||||
Jan 20 20:53:54 pa example-start[2235]: File: /run/keys/example
|
|
||||||
Jan 20 20:53:54 pa example-start[2235]: Size: 31 Blocks: 8 IO Block: 4096 regular file
|
|
||||||
Jan 20 20:53:54 pa example-start[2235]: Device: 18h/24d Inode: 37428 Links: 1
|
|
||||||
Jan 20 20:53:54 pa example-start[2235]: Access: (0400/-r--------) Uid: ( 998/ example) Gid: ( 96/ keys)
|
|
||||||
Jan 20 20:53:54 pa example-start[2235]: Access: 2021-01-20 20:53:54.010554201 +0000
|
|
||||||
Jan 20 20:53:54 pa example-start[2235]: Modify: 2021-01-20 20:53:54.010554201 +0000
|
|
||||||
Jan 20 20:53:54 pa example-start[2235]: Change: 2021-01-20 20:53:54.398103181 +0000
|
|
||||||
Jan 20 20:53:54 pa example-start[2235]: Birth: -
|
|
||||||
Jan 20 20:53:54 pa systemd[1]: example.service: Succeeded.
|
|
||||||
Jan 20 20:53:54 pa systemd[1]: Finished example.service.
|
|
||||||
```
|
|
||||||
|
|
||||||
So what happens when we reboot? I'll force a reboot in my hypervisor and we'll
|
|
||||||
find out:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ nixops ssh -d blog-example pa -- systemctl status example
|
|
||||||
● example.service
|
|
||||||
Loaded: loaded (/nix/store/j4a8f6mnaw3v4sz7dqlnz95psh72xglw-unit-example.service/example.service; enabled; vendor preset: enabled)
|
|
||||||
Active: inactive (dead)
|
|
||||||
```
|
|
||||||
|
|
||||||
The service is inactive. Let's see what the status of `example-key.service` is:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ nixops ssh -d blog-example pa -- systemctl status example-key
|
|
||||||
● example-key.service
|
|
||||||
Loaded: loaded (/nix/store/ikqn64cjq8pspkf3ma1jmx8qzpyrckpb-unit-example-key.service/example-key.service; linked; vendor preset: enabled)
|
|
||||||
Active: activating (start-pre) since Wed 2021-01-20 20:56:05 UTC; 3min 1s ago
|
|
||||||
Cntrl PID: 610 (example-key-pre)
|
|
||||||
IP: 0B in, 0B out
|
|
||||||
IO: 116.0K read, 0B written
|
|
||||||
Tasks: 4 (limit: 2374)
|
|
||||||
Memory: 1.6M
|
|
||||||
CPU: 3ms
|
|
||||||
CGroup: /system.slice/example-key.service
|
|
||||||
├─610 /nix/store/kl6lr3czkbnr6m5crcy8ffwfzbj8a22i-bash-4.4-p23/bin/bash -e /nix/store/awx1zrics3cal8kd9c5d05xzp5ikazlk-unit-script-example-key-pre-start/bin/example-key-pre-start
|
|
||||||
├─619 /nix/store/kl6lr3czkbnr6m5crcy8ffwfzbj8a22i-bash-4.4-p23/bin/bash -e /nix/store/awx1zrics3cal8kd9c5d05xzp5ikazlk-unit-script-example-key-pre-start/bin/example-key-pre-start
|
|
||||||
├─620 /nix/store/kl6lr3czkbnr6m5crcy8ffwfzbj8a22i-bash-4.4-p23/bin/bash -e /nix/store/awx1zrics3cal8kd9c5d05xzp5ikazlk-unit-script-example-key-pre-start/bin/example-key-pre-start
|
|
||||||
└─621 inotifywait -qm --format %f -e create,move /run/keys
|
|
||||||
|
|
||||||
Jan 20 20:56:05 pa systemd[1]: Starting example-key.service...
|
|
||||||
```
|
|
||||||
|
|
||||||
The service is blocked waiting for the keys to exist. We have to populate the
|
|
||||||
keys with `nixops send-keys`:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ nixops send-keys -d blog-example
|
|
||||||
pa> uploading key ‘example’...
|
|
||||||
```
|
|
||||||
|
|
||||||
Now when we check on `example.service`, we get the following:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ nixops ssh -d blog-example pa -- systemctl status example
|
|
||||||
● example.service
|
|
||||||
Loaded: loaded (/nix/store/j4a8f6mnaw3v4sz7dqlnz95psh72xglw-unit-example.service/example.service; enabled; vendor preset: enabled)
|
|
||||||
Active: inactive (dead) since Wed 2021-01-20 21:00:24 UTC; 32s ago
|
|
||||||
Process: 954 ExecStart=/nix/store/1yg89z4dsdp1axacqk07iq5jqv58q169-unit-script-example-start/bin/example-start (code=exited, status=0/SUCCESS)
|
|
||||||
Main PID: 954 (code=exited, status=0/SUCCESS)
|
|
||||||
IP: 0B in, 0B out
|
|
||||||
CPU: 3ms
|
|
||||||
|
|
||||||
Jan 20 21:00:24 pa example-start[957]: File: /run/keys/example
|
|
||||||
Jan 20 21:00:24 pa example-start[957]: Size: 31 Blocks: 8 IO Block: 4096 regular file
|
|
||||||
Jan 20 21:00:24 pa example-start[957]: Device: 18h/24d Inode: 27774 Links: 1
|
|
||||||
Jan 20 21:00:24 pa example-start[957]: Access: (0400/-r--------) Uid: ( 998/ example) Gid: ( 96/ keys)
|
|
||||||
Jan 20 21:00:24 pa example-start[957]: Access: 2021-01-20 21:00:24.588494730 +0000
|
|
||||||
Jan 20 21:00:24 pa example-start[957]: Modify: 2021-01-20 21:00:24.588494730 +0000
|
|
||||||
Jan 20 21:00:24 pa example-start[957]: Change: 2021-01-20 21:00:24.606495751 +0000
|
|
||||||
Jan 20 21:00:24 pa example-start[957]: Birth: -
|
|
||||||
Jan 20 21:00:24 pa systemd[1]: example.service: Succeeded.
|
|
||||||
Jan 20 21:00:24 pa systemd[1]: Finished example.service.
|
|
||||||
```
|
|
||||||
|
|
||||||
This means that NixOps secrets require _manual human intervention_ in order to
|
|
||||||
repopulate them on server boot. If your server went offline overnight due to an
|
|
||||||
unexpected issue, your services using those keys could be stuck offline until
|
|
||||||
morning. This is undesirable for a number of reasons. This plus the requirement
|
|
||||||
for the `keys` group (which at time of writing was undocumented) to be added to
|
|
||||||
service user accounts means that while they do work, they are not very
|
|
||||||
ergonomic.
|
|
||||||
|
|
||||||
[You can read secrets from files using something like
|
|
||||||
`deployment.keys.example.text = "${builtins.readFile ./secrets/example.env}"`,
|
|
||||||
but it is kind of a pain to have to do that. It would be better to just
|
|
||||||
reference the secrets by filesystem paths in the first
|
|
||||||
place.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
On the other hand [Morph](https://github.com/DBCDK/morph) gets this a bit
|
|
||||||
better. It is sadly even less documented than NixOps is, but it offers a similar
|
|
||||||
experience via [deployment
|
|
||||||
secrets](https://github.com/DBCDK/morph/blob/master/examples/secrets.nix). The
|
|
||||||
main differences that Morph brings to the table are taking paths to secrets and
|
|
||||||
allowing you to run an arbitrary command on the secret being uploaded. Secrets
|
|
||||||
are also able to be put anywhere on the disk, meaning that when a host reboots it
|
|
||||||
will come back up with the most recent secrets uploaded to it.
|
|
||||||
|
|
||||||
However, like NixOps, Morph secrets don't have the ability to be rolled back.
|
|
||||||
This means that if you mess up a secret value you better hope you have the old
|
|
||||||
information somewhere. This violates what you'd expect from a NixOS machine.
|
|
||||||
|
|
||||||
So given these examples, I thought it would be interesting to explore what the
|
|
||||||
middle path could look like. I chose to use
|
|
||||||
[age](https://github.com/FiloSottile/age) for encrypting secrets in the Nix
|
|
||||||
store as well as using SSH host keys to ensure that every secret is decryptable
|
|
||||||
at runtime by _that machine only_. If you get your hands on the secret
|
|
||||||
cyphertext, it should be unusable to you.
|
|
||||||
|
|
||||||
One of the harder things here will be keeping a list of all of the server host
|
|
||||||
keys. Recently I added a
|
|
||||||
[hosts.toml](https://github.com/Xe/nixos-configs/blob/master/ops/metadata/hosts.toml)
|
|
||||||
file to my config repo for autoconfiguring my WireGuard overlay network. It was
|
|
||||||
easy enough to add all the SSH host keys for each machine using a command like
|
|
||||||
this to get them:
|
|
||||||
|
|
||||||
[We will cover how this WireGuard overlay works in a future post.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ nixops ssh-for-each -d hexagone -- cat /etc/ssh/ssh_host_ed25519_key.pub
|
|
||||||
firgu....> ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIB8+mCR+MEsv0XYi7ohvdKLbDecBtb3uKGQOPfIhdj3C root@nixos
|
|
||||||
chrysalis> ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIGDA5iXvkKyvAiMEd/5IruwKwoymC8WxH4tLcLWOSYJ1 root@chrysalis
|
|
||||||
lufta....> ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIMADhGV0hKt3ZY+uBjgOXX08txBS6MmHZcSL61KAd3df root@lufta
|
|
||||||
keanu....> ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIGDZUmuhfjEIROo2hog2c8J53taRuPJLNOtdaT8Nt69W root@nixos
|
|
||||||
```
|
|
||||||
|
|
||||||
age lets you use SSH keys for decryption, so I added these keys to my
|
|
||||||
`hosts.toml` and ended up with something like
|
|
||||||
[this](https://github.com/Xe/nixos-configs/commit/14726e982001e794cd72afa1ece209eed58d3f38#diff-61d1d8dddd71be624c0d718be22072c950ec31c72fded8a25094ea53d94c8185).
|
|
||||||
|
|
||||||
Now we can encrypt secrets on the host machine and safely put them in the Nix
|
|
||||||
store because they will be readable to each target machine with a command like
|
|
||||||
this:
|
|
||||||
|
|
||||||
```shell
|
|
||||||
age -d -i /etc/ssh/ssh_host_ed25519_key -o $dest $src
|
|
||||||
```
|
|
||||||
|
|
||||||
From here it's easy to make a function that we can use for generating new
|
|
||||||
encrypted secrets in the Nix store. First we need to import the host metadata
|
|
||||||
from the toml file:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
let
|
|
||||||
cfg = config.within.secrets;
|
|
||||||
metadata = lib.importTOML ../../ops/metadata/hosts.toml;
|
|
||||||
|
|
||||||
mkSecretOnDisk = name:
|
|
||||||
{ source, ... }:
|
|
||||||
pkgs.stdenv.mkDerivation {
|
|
||||||
name = "${name}-secret";
|
|
||||||
phases = "installPhase";
|
|
||||||
buildInputs = [ pkgs.age ];
|
|
||||||
installPhase =
|
|
||||||
let key = metadata.hosts."${config.networking.hostName}".ssh_pubkey;
|
|
||||||
in ''
|
|
||||||
age -a -r "${key}" -o $out ${source}
|
|
||||||
'';
|
|
||||||
};
|
|
||||||
```
|
|
||||||
|
|
||||||
And then we can generate systemd oneshot jobs with something like this:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
mkService = name:
|
|
||||||
{ source, dest, owner, group, permissions, ... }: {
|
|
||||||
description = "decrypt secret for ${name}";
|
|
||||||
wantedBy = [ "multi-user.target" ];
|
|
||||||
|
|
||||||
serviceConfig.Type = "oneshot";
|
|
||||||
|
|
||||||
script = with pkgs; ''
|
|
||||||
rm -rf ${dest}
|
|
||||||
${age}/bin/age -d -i /etc/ssh/ssh_host_ed25519_key -o ${dest} ${
|
|
||||||
mkSecretOnDisk name { inherit source; }
|
|
||||||
}
|
|
||||||
|
|
||||||
chown ${owner}:${group} ${dest}
|
|
||||||
chmod ${permissions} ${dest}
|
|
||||||
'';
|
|
||||||
};
|
|
||||||
```
|
|
||||||
|
|
||||||
And from there we just need some [boring
|
|
||||||
boilerplate](https://github.com/Xe/nixos-configs/blob/master/common/crypto/default.nix#L8-L38)
|
|
||||||
to define a secret type. Then we declare the secret type and its invocation:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
in {
|
|
||||||
options.within.secrets = mkOption {
|
|
||||||
type = types.attrsOf secret;
|
|
||||||
description = "secret configuration";
|
|
||||||
default = { };
|
|
||||||
};
|
|
||||||
|
|
||||||
config.systemd.services = let
|
|
||||||
units = mapAttrs' (name: info: {
|
|
||||||
name = "${name}-key";
|
|
||||||
value = (mkService name info);
|
|
||||||
}) cfg;
|
|
||||||
in units;
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
And we have ourself a NixOS module that allows us to:
|
|
||||||
|
|
||||||
* Trivially declare new secrets
|
|
||||||
* Make secrets in the Nix store useless without the key
|
|
||||||
* Make every secret be transparently decrypted on startup
|
|
||||||
* Avoid the use of GPG
|
|
||||||
* Roll back secrets like any other configuration change
|
|
||||||
|
|
||||||
Declaring new secrets works like this (as stolen from [the service definition
|
|
||||||
for the website you are reading right now](https://github.com/Xe/nixos-configs/blob/master/common/services/xesite.nix#L35-L41)):
|
|
||||||
|
|
||||||
```nix
|
|
||||||
within.secrets.example = {
|
|
||||||
source = ./secrets/example.env;
|
|
||||||
dest = "/var/lib/example/.env";
|
|
||||||
owner = "example";
|
|
||||||
group = "nogroup";
|
|
||||||
permissions = "0400";
|
|
||||||
};
|
|
||||||
```
|
|
||||||
|
|
||||||
Barring some kind of cryptographic attack against age, this should allow the
|
|
||||||
secrets to be stored securely. I am working on a way to make this more generic.
|
|
||||||
This overall approach was inspired by [agenix](https://github.com/ryantm/agenix)
|
|
||||||
but made more specific for my needs. I hope this approach will make it easy for
|
|
||||||
me to manage these secrets in the future.
|
|
||||||
|
|
@ -1,12 +0,0 @@
|
||||||
---
|
|
||||||
title: "Tailscale on NixOS: A New Minecraft Server in Ten Minutes"
|
|
||||||
date: 2021-01-19
|
|
||||||
tags:
|
|
||||||
- link
|
|
||||||
redirect_to: https://tailscale.com/blog/nixos-minecraft/
|
|
||||||
---
|
|
||||||
|
|
||||||
# Tailscale on NixOS: A New Minecraft Server in Ten Minutes
|
|
||||||
|
|
||||||
Check out this post [on the Tailscale
|
|
||||||
blog](https://tailscale.com/blog/nixos-minecraft/)!
|
|
||||||
|
|
@ -46,7 +46,7 @@ right code runs as a response. I then have to make sure these things get put
|
||||||
in the right places and then that the right versions of things are running for
|
in the right places and then that the right versions of things are running for
|
||||||
each of the relevant services. This doesn't scale very well, not to mention is
|
each of the relevant services. This doesn't scale very well, not to mention is
|
||||||
hard to secure. This leads to a lot of duplicate infrastructure over time and
|
hard to secure. This leads to a lot of duplicate infrastructure over time and
|
||||||
as things grow. Not to mention adding in tracing, metrics and log aggregation.
|
as things grow. Not to mention adding in tracing, metrics and log aggreation.
|
||||||
|
|
||||||
I would like to change this.
|
I would like to change this.
|
||||||
|
|
||||||
|
|
@ -58,7 +58,7 @@ need to be maintained in parallel, so it might be good to get used to that early
|
||||||
on.
|
on.
|
||||||
|
|
||||||
You should not have to write ANY code but the bare minimum needed in order to
|
You should not have to write ANY code but the bare minimum needed in order to
|
||||||
perform your business logic. You don't need to care about distributed tracing.
|
perform your buisiness logic. You don't need to care about distributed tracing.
|
||||||
You don't need to care about logging.
|
You don't need to care about logging.
|
||||||
|
|
||||||
I want this project to last decades. I want the binary modules any user of Olin
|
I want this project to last decades. I want the binary modules any user of Olin
|
||||||
|
|
|
||||||
|
|
@ -1,129 +0,0 @@
|
||||||
---
|
|
||||||
title: My Org Mode Flow
|
|
||||||
date: 2020-09-08
|
|
||||||
tags:
|
|
||||||
- emacs
|
|
||||||
---
|
|
||||||
|
|
||||||
# My Org Mode Flow
|
|
||||||
|
|
||||||
At almost every job I've worked at, at least one of my coworkers has noticed
|
|
||||||
that I use Emacs as my main text editor. People have pointed me at IntelliJ, VS
|
|
||||||
Code, Atom and more, but I keep sticking to Emacs because it has one huge ace up
|
|
||||||
its sleeve that other editors simply cannot match. Emacs has a package that
|
|
||||||
helps me organize my workflow, focus my note-taking and even keep a timeclock
|
|
||||||
for how long I spend working on tasks. This package is called Org mode, and this
|
|
||||||
is my flow for using it.
|
|
||||||
|
|
||||||
[Org mode](https://orgmode.org/) is a TODO list manager, document authoring
|
|
||||||
platform and more for [GNU Emacs](https://www.gnu.org/software/emacs/). It uses
|
|
||||||
specially formatted plain text that can be managed using version control
|
|
||||||
systems. I have used it daily for about five years for keeping track of what I
|
|
||||||
need to do for work. Please note that my usage of it _barely scratches the
|
|
||||||
surface_ of what Org mode can do, because this is all I have needed.
|
|
||||||
|
|
||||||
## `~/org`
|
|
||||||
|
|
||||||
My org flow starts with a single folder: `~/org`. The main file I use is
|
|
||||||
`todo.org` and it looks something like this:
|
|
||||||
|
|
||||||
```org
|
|
||||||
#+TITLE: TODO
|
|
||||||
|
|
||||||
* Doing
|
|
||||||
** TODO WAT-42069 Unfrobnicate the rilkef for flopnax-ropjar push...
|
|
||||||
* In Review
|
|
||||||
** TODO WAT-42042 New Relic Dashboards...
|
|
||||||
* Reviews
|
|
||||||
** DONE HAX-1337 Security architecture of wasmcloud
|
|
||||||
* Interrupt
|
|
||||||
* Generic todo
|
|
||||||
* Overhead
|
|
||||||
** 09/08/2020
|
|
||||||
*** DONE workday start...
|
|
||||||
*** DONE standup...
|
|
||||||
```
|
|
||||||
|
|
||||||
Each level of stars creates a new heading level, and these headings can be
|
|
||||||
treated like a tree. You can use the tab key to open and close the heading
|
|
||||||
levels and hide those parts of the tree if they are not relevant. Let's open up
|
|
||||||
the standup subtree with tab:
|
|
||||||
|
|
||||||
```org
|
|
||||||
*** DONE standup
|
|
||||||
CLOSED: [2020-09-08 Tue 10:12]
|
|
||||||
:LOGBOOK:
|
|
||||||
CLOCK: [2020-09-08 Tue 10:00]--[2020-09-08 Tue 10:12] => 0:12
|
|
||||||
:END:
|
|
||||||
```
|
|
||||||
|
|
||||||
Org mode automatically entered in nearly all of the information in this subtree
|
|
||||||
for me. I clocked in (alt-x org-clock-in with that TODO item highighted) when
|
|
||||||
the standup started and I clocked out by marking the task as done (alt-x
|
|
||||||
org-todo with that TODO item highlighted). If I am working on a task that takes
|
|
||||||
longer than one session, I can clock out of it (alt-x org-clock-out) and then
|
|
||||||
the time I spent (about 20 minutes) will be recorded in the file for me. Then I
|
|
||||||
can manually enter the time spent into tools like Jira.
|
|
||||||
|
|
||||||
When I am ready to move a task from In Progress to In Review, I close the
|
|
||||||
subtree with tab and then highlight the collapsed subtree, cut it and paste it
|
|
||||||
under the In Review header. This will keep the time tracking information
|
|
||||||
associated with that header entry.
|
|
||||||
|
|
||||||
I will tend to let tasks build up over the week and then on Monday morning I
|
|
||||||
will move all of the done tasks to `done.org`, which is where I store things
|
|
||||||
that are done. As I move things over, I double check with Jira to make sure the
|
|
||||||
time tracking has been accurately updated. This can take a while, but doing this
|
|
||||||
has caught cases where I have misreported time and then had the opportunity to
|
|
||||||
correct it.
|
|
||||||
|
|
||||||
## Clocktables
|
|
||||||
|
|
||||||
Org mode is also able to generate tables based on information in org files. One
|
|
||||||
of the most useful ones is the [clock
|
|
||||||
table](https://orgmode.org/manual/The-clock-table.html#). You can use these
|
|
||||||
clock tables to make reports about how much time was spent in each task. I use
|
|
||||||
these to help me know what I have done in the day so I can report about it in
|
|
||||||
the next day's standup meeting. To add a clock table, add an empty block for it
|
|
||||||
and press control-c c on the `BEGIN` line. Here's an example:
|
|
||||||
|
|
||||||
```org
|
|
||||||
#+BEGIN: clocktable :block today
|
|
||||||
#+END:
|
|
||||||
```
|
|
||||||
|
|
||||||
This will show you all of the things you have recorded for that day. This may
|
|
||||||
end up being a bit much if you nest things deep enough. My preferred clock table
|
|
||||||
is a daily view only showing the second level and lower for the current file:
|
|
||||||
|
|
||||||
```org
|
|
||||||
#+BEGIN: clocktable :maxlevel 2 :block today :scope file
|
|
||||||
#+CAPTION: Clock summary at [2020-09-08 Tue 15:47], for Tuesday, September 08, 2020.
|
|
||||||
| Headline | Time | |
|
|
||||||
|-----------------------------|--------|------|
|
|
||||||
| *Total time* | *6:14* | |
|
|
||||||
|-----------------------------|--------|------|
|
|
||||||
| In Progress | 2:09 | |
|
|
||||||
| \_ WAT-42069 Unfrobnica... | | 2:09 |
|
|
||||||
| Overhead | 4:05 | |
|
|
||||||
| \_ 09/08/2020 | | 4:05 |
|
|
||||||
#+END:
|
|
||||||
```
|
|
||||||
|
|
||||||
This allows me to see that I've been working today for about 6.25 hours for the
|
|
||||||
day, so I can use that information when deciding what to do next.
|
|
||||||
|
|
||||||
## Other Things You Can Do
|
|
||||||
|
|
||||||
In the past I used to use org mode for a lot of things. In one of my older files
|
|
||||||
I have a comprehensive list of all of the times I smoked weed down to the amount
|
|
||||||
smoked and what I felt about it at the time. In another I have a script that I
|
|
||||||
used for applying ansible files across a cluster. The sky really is the limit.
|
|
||||||
|
|
||||||
However, I have really decided to keep things simple for the most part. I leave
|
|
||||||
org mode for work stuff and mostly use iCloud services for personal stuff. There
|
|
||||||
are mobile apps for using org-mode on the go, but they haven't aged well at all
|
|
||||||
and I have been focusing my time into actually doing things instead of
|
|
||||||
configuring WEBDAV servers or the like.
|
|
||||||
|
|
||||||
This is how I keep track of things at work.
|
|
||||||
|
|
@ -19,7 +19,7 @@ make this data anonymous, simplistic and (reasonably) public.
|
||||||
|
|
||||||
Here is how it works:
|
Here is how it works:
|
||||||
|
|
||||||

|
<center></center>
|
||||||
|
|
||||||
When the page is loaded, a [javascript file records the start time](/static/js/pageview_timer.js).
|
When the page is loaded, a [javascript file records the start time](/static/js/pageview_timer.js).
|
||||||
This then sets a [pagehide handler](https://developer.mozilla.org/en-US/docs/Web/API/Window/pagehide_event)
|
This then sets a [pagehide handler](https://developer.mozilla.org/en-US/docs/Web/API/Window/pagehide_event)
|
||||||
|
|
|
||||||
|
|
@ -1,345 +0,0 @@
|
||||||
---
|
|
||||||
title: "pa'i Benchmarks"
|
|
||||||
date: 2020-03-26
|
|
||||||
series: olin
|
|
||||||
tags:
|
|
||||||
- wasm
|
|
||||||
- rust
|
|
||||||
- golang
|
|
||||||
- pahi
|
|
||||||
---
|
|
||||||
|
|
||||||
# pa'i Benchmarks
|
|
||||||
|
|
||||||
In my [last post][pahihelloworld] I mentioned that pa'i was faster than Olin's
|
|
||||||
cwa binary written in go without giving any benchmarks. I've been working on new
|
|
||||||
ways to gather and visualize these benchmarks, and here they are.
|
|
||||||
|
|
||||||
[pahihelloworld]: https://christine.website/blog/pahi-hello-world-2020-02-22
|
|
||||||
|
|
||||||
Benchmarking WebAssembly implementations is slightly hard. A lot of existing
|
|
||||||
benchmark tools simply do not run in WebAssembly as is, not to mention inside
|
|
||||||
the Olin ABI. However, I have created a few tasks that I feel represent common
|
|
||||||
tasks that pa'i (and later wasmcloud) will run:
|
|
||||||
|
|
||||||
- compressing data with [Snappy][snappy]
|
|
||||||
- parsing JSON
|
|
||||||
- parsing yaml
|
|
||||||
- recursive fibbonacci number calculation
|
|
||||||
- blake-2 hashing
|
|
||||||
|
|
||||||
As always, if you don't trust my numbers, you don't have to. Commands will be
|
|
||||||
given to run these benchmarks on your own hardware. This may not be the most
|
|
||||||
scientifically accurate benchmarks possible, but it should help to give a
|
|
||||||
reasonable idea of the speed gains from using Rust instead of Go.
|
|
||||||
|
|
||||||
You can run these benchmarks in the docker image `xena/pahi`. You may need to
|
|
||||||
replace `./result/` with `/` for running this inside Docker.
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ docker run --rm -it xena/pahi bash -l
|
|
||||||
```
|
|
||||||
|
|
||||||
[snappy]: https://en.wikipedia.org/wiki/Snappy_(compression)
|
|
||||||
|
|
||||||
## Compressing Data with Snappy
|
|
||||||
|
|
||||||
This is implemented as [`cpustrain.wasm`][cpustrain]. Here is the source code
|
|
||||||
used in the benchmark:
|
|
||||||
|
|
||||||
[cpustrain]: https://github.com/Xe/pahi/blob/96f051d16df35cbceb8bf802e7dd7482b41b7d8a/wasm/cpustrain/src/main.rs
|
|
||||||
|
|
||||||
```rust
|
|
||||||
#![no_main]
|
|
||||||
#![feature(start)]
|
|
||||||
|
|
||||||
extern crate olin;
|
|
||||||
|
|
||||||
use olin::{entrypoint, Resource};
|
|
||||||
use std::io::Write;
|
|
||||||
|
|
||||||
entrypoint!();
|
|
||||||
|
|
||||||
fn main() -> Result<(), std::io::Error> {
|
|
||||||
let fout = Resource::open("null://").expect("opening /dev/null");
|
|
||||||
let data = include_bytes!("/proc/cpuinfo");
|
|
||||||
|
|
||||||
let mut writer = snap::write::FrameEncoder::new(fout);
|
|
||||||
|
|
||||||
for _ in 0..256 {
|
|
||||||
// compressed data
|
|
||||||
writer.write(data)?;
|
|
||||||
}
|
|
||||||
|
|
||||||
Ok(())
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
This compresses my machine's copy of [/proc/cpuinfo][proccpuinfo] 256 times.
|
|
||||||
This number was chosen arbitrarily.
|
|
||||||
|
|
||||||
[proccpuinfo]: https://clbin.com/rxAOg
|
|
||||||
|
|
||||||
Here are the results I got from the following command:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ hyperfine --warmup 3 --prepare './result/bin/pahi result/wasm/cpustrain.wasm' \
|
|
||||||
'./result/bin/cwa result/wasm/cpustrain.wasm' \
|
|
||||||
'./result/bin/pahi --no-cache result/wasm/cpustrain.wasm' \
|
|
||||||
'./result/bin/pahi result/wasm/cpustrain.wasm'
|
|
||||||
```
|
|
||||||
|
|
||||||
| CPU | cwa | pahi --no-cache | pahi | multiplier |
|
|
||||||
| :----------------- | :------------ | :---------------- | :---------------- | :-------------------------------- |
|
|
||||||
| Ryzen 5 3600 | 2.392 seconds | 38.6 milliseconds | 17.7 milliseconds | pahi is 135 times faster than cwa |
|
|
||||||
| Intel Xeon E5-1650 | 7.652 seconds | 99.3 milliseconds | 53.7 milliseconds | pahi is 142 times faster than cwa |
|
|
||||||
|
|
||||||
## Parsing JSON
|
|
||||||
|
|
||||||
This is implemented as [`bigjson.wasm`][bigjson]. Here is the source code of the
|
|
||||||
benchmark:
|
|
||||||
|
|
||||||
[bigjson]: https://github.com/Xe/pahi/blob/96f051d16df35cbceb8bf802e7dd7482b41b7d8a/wasm/cpustrain/src/bin/bigjson.rs
|
|
||||||
|
|
||||||
```rust
|
|
||||||
|
|
||||||
#![no_main]
|
|
||||||
#![feature(start)]
|
|
||||||
|
|
||||||
extern crate olin;
|
|
||||||
|
|
||||||
use olin::entrypoint;
|
|
||||||
use serde_json::{from_slice, to_string, Value};
|
|
||||||
|
|
||||||
entrypoint!();
|
|
||||||
|
|
||||||
fn main() -> Result<(), std::io::Error> {
|
|
||||||
let input = include_bytes!("./bigjson.json");
|
|
||||||
|
|
||||||
if let Ok(val) = from_slice(input) {
|
|
||||||
let v: Value = val;
|
|
||||||
if let Err(_why) = to_string(&v) {
|
|
||||||
return Err(std::io::Error::new(
|
|
||||||
std::io::ErrorKind::Other,
|
|
||||||
"oh no json encoding failed!",
|
|
||||||
));
|
|
||||||
}
|
|
||||||
} else {
|
|
||||||
return Err(std::io::Error::new(
|
|
||||||
std::io::ErrorKind::Other,
|
|
||||||
"oh no json parsing failed!",
|
|
||||||
));
|
|
||||||
}
|
|
||||||
|
|
||||||
Ok(())
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
This decodes and encodes this [rather large json file][bigjsonjson]. This is a
|
|
||||||
very large file (over 64k of json) and should represent over 65536 times times
|
|
||||||
the average json payload size.
|
|
||||||
|
|
||||||
[bigjsonjson]: https://github.com/Xe/pahi/blob/96f051d16df35cbceb8bf802e7dd7482b41b7d8a/wasm/cpustrain/src/bin/bigjson.json
|
|
||||||
|
|
||||||
Here are the results I got from the following command:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ hyperfine --warmup 3 --prepare './result/bin/pahi result/wasm/bigjson.wasm' \
|
|
||||||
'./result/bin/cwa result/wasm/bigjson.wasm' \
|
|
||||||
'./result/bin/pahi --no-cache result/wasm/bigjson.wasm' \
|
|
||||||
'./result/bin/pahi result/wasm/bigjson.wasm'
|
|
||||||
```
|
|
||||||
|
|
||||||
| CPU | cwa | pahi --no-cache | pahi | multiplier |
|
|
||||||
| :----------------- | :------------ | :---------------- | :---------------- | :-------------------------------- |
|
|
||||||
| Ryzen 5 3600 | 257 milliseconds | 49.4 milliseconds | 20.4 milliseconds | pahi is 12.62 times faster than cwa |
|
|
||||||
| Intel Xeon E5-1650 | 935.5 milliseconds | 135.4 milliseconds | 101.4 milliseconds | pahi is 9.22 times faster than cwa |
|
|
||||||
|
|
||||||
## Parsing yaml
|
|
||||||
|
|
||||||
This is implemented as [`k8sparse.wasm`][k8sparse]. Here is the source code of
|
|
||||||
the benchmark:
|
|
||||||
|
|
||||||
[k8sparse]: https://github.com/Xe/pahi/blob/96f051d16df35cbceb8bf802e7dd7482b41b7d8a/wasm/cpustrain/src/bin/k8sparse.rs
|
|
||||||
|
|
||||||
```rust
|
|
||||||
#![no_main]
|
|
||||||
#![feature(start)]
|
|
||||||
|
|
||||||
extern crate olin;
|
|
||||||
|
|
||||||
use olin::entrypoint;
|
|
||||||
use serde_yaml::{from_slice, to_string, Value};
|
|
||||||
|
|
||||||
entrypoint!();
|
|
||||||
|
|
||||||
fn main() -> Result<(), std::io::Error> {
|
|
||||||
let input = include_bytes!("./k8sparse.yaml");
|
|
||||||
|
|
||||||
if let Ok(val) = from_slice(input) {
|
|
||||||
let v: Value = val;
|
|
||||||
if let Err(_why) = to_string(&v) {
|
|
||||||
return Err(std::io::Error::new(
|
|
||||||
std::io::ErrorKind::Other,
|
|
||||||
"oh no yaml encoding failed!",
|
|
||||||
));
|
|
||||||
} else {
|
|
||||||
return Err(std::io::Error::new(
|
|
||||||
std::io::ErrorKind::Other,
|
|
||||||
"oh no yaml parsing failed!",
|
|
||||||
));
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
Ok(())
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
This decodes and encodes this [kubernetes manifest set from my
|
|
||||||
cluster][k8sparseyaml]. This is a set of a few normal kubernetes deployments and
|
|
||||||
isn't as much of a worse-case scenario as it could be with the other tests.
|
|
||||||
|
|
||||||
[k8sparseyaml]: https://github.com/Xe/pahi/blob/96f051d16df35cbceb8bf802e7dd7482b41b7d8a/wasm/cpustrain/src/bin/k8sparse.yaml#L1
|
|
||||||
|
|
||||||
Here are the results I got from running the following command:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ hyperfine --warmup 3 --prepare './result/bin/pahi result/wasm/k8sparse.wasm' \
|
|
||||||
'./result/bin/cwa result/wasm/k8sparse.wasm' \
|
|
||||||
'./result/bin/pahi --no-cache result/wasm/k8sparse.wasm' \
|
|
||||||
'./result/bin/pahi result/wasm/k8sparse.wasm'
|
|
||||||
```
|
|
||||||
|
|
||||||
| CPU | cwa | pahi --no-cache | pahi | multiplier |
|
|
||||||
| :----------------- | :------------ | :---------------- | :---------------- | :-------------------------------- |
|
|
||||||
| Ryzen 5 3600 | 211.7 milliseconds | 125.3 milliseconds | 8.5 milliseconds | pahi is 25.04 times faster than cwa |
|
|
||||||
| Intel Xeon E5-1650 | 674.1 milliseconds | 342.7 milliseconds | 30.8 milliseconds | pahi is 21.85 times faster than cwa |
|
|
||||||
|
|
||||||
## Recursive Fibbonacci Number Calculation
|
|
||||||
|
|
||||||
This is implemented as [`fibber.wasm`][fibber]. Here is the source code used in
|
|
||||||
the benchmark:
|
|
||||||
|
|
||||||
[fibber]: https://github.com/Xe/pahi/blob/96f051d16df35cbceb8bf802e7dd7482b41b7d8a/wasm/cpustrain/src/bin/fibber.rs
|
|
||||||
|
|
||||||
```rust
|
|
||||||
#![no_main]
|
|
||||||
#![feature(start)]
|
|
||||||
|
|
||||||
extern crate olin;
|
|
||||||
|
|
||||||
use olin::{entrypoint, log};
|
|
||||||
|
|
||||||
entrypoint!();
|
|
||||||
|
|
||||||
fn fib(n: u64) -> u64 {
|
|
||||||
if n <= 1 {
|
|
||||||
return 1;
|
|
||||||
}
|
|
||||||
fib(n - 1) + fib(n - 2)
|
|
||||||
}
|
|
||||||
|
|
||||||
fn main() -> Result<(), std::io::Error> {
|
|
||||||
log::info("starting");
|
|
||||||
fib(30);
|
|
||||||
log::info("done");
|
|
||||||
Ok(())
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
Fibbonacci number calculation done recursively is an incredibly time-complicated
|
|
||||||
ordeal. This is the worst possible case for this kind of calculation, as it
|
|
||||||
doesn't cache results from the `fib` function.
|
|
||||||
|
|
||||||
Here are the results I got from running the following command:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ hyperfine --warmup 3 --prepare './result/bin/pahi result/wasm/fibber.wasm' \
|
|
||||||
'./result/bin/cwa result/wasm/fibber.wasm' \
|
|
||||||
'./result/bin/pahi --no-cache result/wasm/fibber.wasm' \
|
|
||||||
'./result/bin/pahi result/wasm/fibber.wasm'
|
|
||||||
```
|
|
||||||
|
|
||||||
| CPU | cwa | pahi --no-cache | pahi | multiplier |
|
|
||||||
| :----------------- | :------------ | :---------------- | :---------------- | :-------------------------------- |
|
|
||||||
| Ryzen 5 3600 | 13.6 milliseconds | 13.7 milliseconds | 2.7 milliseconds | pahi is 5.13 times faster than cwa |
|
|
||||||
| Intel Xeon E5-1650 | 41.0 milliseconds | 27.3 milliseconds | 7.2 milliseconds | pahi is 5.70 times faster than cwa |
|
|
||||||
|
|
||||||
## Blake-2 Hashing
|
|
||||||
|
|
||||||
This is implemented as [`blake2stress.wasm`][blake2stress]. Here's the source
|
|
||||||
code for this benchmark:
|
|
||||||
|
|
||||||
[blake2stress]: https://github.com/Xe/pahi/blob/96f051d16df35cbceb8bf802e7dd7482b41b7d8a/wasm/cpustrain/src/bin/blake2stress.rs
|
|
||||||
|
|
||||||
```rust
|
|
||||||
#![no_main]
|
|
||||||
#![feature(start)]
|
|
||||||
|
|
||||||
extern crate olin;
|
|
||||||
|
|
||||||
use blake2::{Blake2b, Digest};
|
|
||||||
use olin::{entrypoint, log};
|
|
||||||
|
|
||||||
entrypoint!();
|
|
||||||
|
|
||||||
fn main() -> Result<(), std::io::Error> {
|
|
||||||
let json: &'static [u8] = include_bytes!("./bigjson.json");
|
|
||||||
let yaml: &'static [u8] = include_bytes!("./k8sparse.yaml");
|
|
||||||
for _ in 0..8 {
|
|
||||||
let mut hasher = Blake2b::new();
|
|
||||||
hasher.input(json);
|
|
||||||
hasher.input(yaml);
|
|
||||||
hasher.result();
|
|
||||||
}
|
|
||||||
|
|
||||||
Ok(())
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
This runs the [blake2b hashing algorithm][blake2b] on the JSON and yaml files
|
|
||||||
used earlier eight times. This is supposed to represent a few hundred thousand
|
|
||||||
invocations of production code.
|
|
||||||
|
|
||||||
[blake2b]: https://en.wikipedia.org/wiki/BLAKE_(hash_function)#BLAKE2b_algorithm
|
|
||||||
|
|
||||||
Here are the results I got from running the following command:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ hyperfine --warmup 3 --prepare './result/bin/pahi result/wasm/blake2stress.wasm' \
|
|
||||||
'./result/bin/cwa result/wasm/blake2stress.wasm' \
|
|
||||||
'./result/bin/pahi --no-cache result/wasm/blake2stress.wasm' \
|
|
||||||
'./result/bin/pahi result/wasm/blake2stress.wasm'
|
|
||||||
```
|
|
||||||
|
|
||||||
| CPU | cwa | pahi --no-cache | pahi | multiplier |
|
|
||||||
| :----------------- | :------------ | :---------------- | :---------------- | :-------------------------------- |
|
|
||||||
| Ryzen 5 3600 | 358.7 milliseconds | 17.4 milliseconds | 5.0 milliseconds | pahi is 71.76 times faster than cwa |
|
|
||||||
| Intel Xeon E5-1650 | 1.351 seconds | 35.5 milliseconds | 11.7 milliseconds | pahi is 115.04 times faster than cwa |
|
|
||||||
|
|
||||||
## Conclusions
|
|
||||||
|
|
||||||
From these tests, we can roughly conclude that pa'i is about 54 times faster
|
|
||||||
than Olin's cwa tool. A lot of this speed gain is arguably the result of pa'i
|
|
||||||
using an ahead of time compiler (namely cranelift as wrapped by wasmer). The
|
|
||||||
compilation time also became a somewhat notable factor for comparing performance
|
|
||||||
too, however the compilation cost only has to be eaten once.
|
|
||||||
|
|
||||||
Another conclusion I've made is very unsurprising. My old 2013 mac pro with an
|
|
||||||
Intel Xeon E5-1650 is _significantly_ slower in real-world computing tasks than
|
|
||||||
the new Ryzen 5 3600. Both of these machines were using the same nix closure for
|
|
||||||
running the binaries and they are running NixOS 20.03.
|
|
||||||
|
|
||||||
As always, if you have any feedback for what other kinds of benchmarks to run
|
|
||||||
and how these benchmarks were collected, I welcome it. Please comment wherever
|
|
||||||
this article is posted or [contact me](/contact).
|
|
||||||
|
|
||||||
Here are the /proc/cpuinfo files for each machine being tested:
|
|
||||||
|
|
||||||
- shachi (Ryzen 5 3600) [/proc/cpuinfo](https://clbin.com/Nilnm)
|
|
||||||
- chrysalis (Intel Xeon E5-1650) [/proc/cpuinfo](https://clbin.com/24HM1)
|
|
||||||
|
|
||||||
If you run these benchmarks on your own hardware and get different data, please
|
|
||||||
let me know and I will be more than happy to add your results to these tables. I
|
|
||||||
will need the CPU model name and the output of hyperfine for each of the above
|
|
||||||
commands.
|
|
||||||
|
|
@ -1,169 +0,0 @@
|
||||||
---
|
|
||||||
title: "pa'i: hello world!"
|
|
||||||
date: 2020-02-22
|
|
||||||
series: olin
|
|
||||||
tags:
|
|
||||||
- rust
|
|
||||||
- wasm
|
|
||||||
- dhall
|
|
||||||
---
|
|
||||||
|
|
||||||
# pa'i: hello world!
|
|
||||||
|
|
||||||
It's been a while since I gave an update on the Olin ecosystem (which now
|
|
||||||
exists, apparently). Not much has really gone on with it for the last few
|
|
||||||
months. However, recently I've decided to tackle one of the core problems of
|
|
||||||
Olin's implementation in Go: execution speed.
|
|
||||||
|
|
||||||
Originally I was going to try and handle this with
|
|
||||||
["hyperjit"](https://innative.dev), but support for linking C++ programs into Go
|
|
||||||
is always questionable at best. All of the WebAssembly compiling and
|
|
||||||
running tooling has been written in Rust, and as far as I know I was the only
|
|
||||||
holdout still using Go. This left me kinda stranded and on my own, seeing as the
|
|
||||||
libraries that I was using were starting to die.
|
|
||||||
|
|
||||||
I have been following the [wasmer][wasmer] project for a while and thanks to
|
|
||||||
their recent [custom ABI sample][wasmercustomabisample], I was able to start
|
|
||||||
re-implementing the Olin API in it. Wasmer uses a JIT for handling WebAssembly,
|
|
||||||
so I'm able to completely destroy the original Go implementation in terms of
|
|
||||||
performance. I call this newer, faster runtime pa'i (/pa.hi/, paw-hee), which
|
|
||||||
is a [Lojban][lojban] [rafsi][rafsi] for the word prami which means love.
|
|
||||||
|
|
||||||
[wasmer]: https://wasmer.io
|
|
||||||
[wasmercustomabisample]: https://github.com/wasmerio/wasmer-rust-customabi-example
|
|
||||||
[lojban]: https://mw.lojban.org/papri/Lojban
|
|
||||||
[rafsi]: http://lojban.org/publications/cll/cll_v1.1_xhtml-section-chunks/section-rafsi.html
|
|
||||||
|
|
||||||
[pa'i][pahi] is written in [Rust][rust]. It is built with [Nix][nix]. It
|
|
||||||
requires a nightly version of Rust because the WebAssembly code it compiles
|
|
||||||
requires it. However, because it is built with Nix, this quickly becomes a
|
|
||||||
non-issue. You can build pa'i by doing the following:
|
|
||||||
|
|
||||||
[pahi]: https://github.com/Xe/pahi
|
|
||||||
[rust]: https://www.rust-lang.org
|
|
||||||
[nix]: https://nixos.org/nix/
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ git clone git@github.com:Xe/pahi
|
|
||||||
$ cd pahi
|
|
||||||
$ nix-build
|
|
||||||
```
|
|
||||||
|
|
||||||
and then `nix-build` will take care of:
|
|
||||||
|
|
||||||
- downloading the pinned nightly version of the rust compiler
|
|
||||||
- building the reference Olin interpreter
|
|
||||||
- building the pa'i runtime
|
|
||||||
- building a small suite of sample programs
|
|
||||||
- building the documentation from [dhall][dhall] files
|
|
||||||
- building a small test runner
|
|
||||||
|
|
||||||
[dhall]: https://dhall-lang.org
|
|
||||||
|
|
||||||
If you want to try this out in a more predictable environment, you can also
|
|
||||||
`nix-build docker.nix`. This will create a Docker image as the result of the Nix
|
|
||||||
build. This docker image includes [the pa'i composite package][pahidefaultnix],
|
|
||||||
bash, coreutils and `dhall-to-json` (which is required by the test runner).
|
|
||||||
|
|
||||||
[pahidefaultnix]: https://github.com/Xe/pahi/blob/master/default.nix
|
|
||||||
|
|
||||||
I'm actually really proud of how the documentation generation works. The
|
|
||||||
[cwa-spec folder in Olin][cwaspecolin] was done very ad-hoc and was only
|
|
||||||
consistent because there was a template. This time functions, types, errors,
|
|
||||||
namespaces and the underlying WebAssembly types they boil down to are all
|
|
||||||
implemented as Dhall records. For example, here's the definition of a
|
|
||||||
[namespace][cwans] [in Dhall][nsdhall]:
|
|
||||||
|
|
||||||
[cwaspecolin]: https://github.com/Xe/olin/tree/master/docs/cwa-spec
|
|
||||||
[cwans]: https://github.com/Xe/pahi/tree/master/olin-spec#namespaces
|
|
||||||
[nsdhall]: https://github.com/Xe/pahi/blob/5ea1184c09df4e657524f9d5e77941cda5560d9a/olin-spec/types/ns.dhall
|
|
||||||
|
|
||||||
```
|
|
||||||
let func = ./func.dhall
|
|
||||||
|
|
||||||
in { Type = { name : Text, desc : Text, funcs : List func.Type }
|
|
||||||
, default =
|
|
||||||
{ name = "unknown"
|
|
||||||
, desc = "please fill in the desc field"
|
|
||||||
, funcs = [] : List func.Type
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
which gets rendered to [Markdown][markdown] using
|
|
||||||
[`renderNSToMD.dhall`][shownsasmd]:
|
|
||||||
|
|
||||||
[markdown]: https://github.github.com/gfm/
|
|
||||||
[shownsasmd]: https://github.com/Xe/pahi/blob/5ea1184c09df4e657524f9d5e77941cda5560d9a/olin-spec/types/renderNSToMD.dhall
|
|
||||||
|
|
||||||
```
|
|
||||||
let ns = ./ns.dhall
|
|
||||||
|
|
||||||
let func = ./func.dhall
|
|
||||||
|
|
||||||
let type = ./type.dhall
|
|
||||||
|
|
||||||
let showFunc = ./renderFuncToMD.dhall
|
|
||||||
|
|
||||||
let Prelude = ../Prelude.dhall
|
|
||||||
|
|
||||||
let toList = Prelude.Text.concatMapSep "\n" func.Type showFunc
|
|
||||||
|
|
||||||
let show
|
|
||||||
: ns.Type → Text
|
|
||||||
= λ(namespace : ns.Type)
|
|
||||||
→ ''
|
|
||||||
# ${namespace.name}
|
|
||||||
|
|
||||||
${namespace.desc}
|
|
||||||
|
|
||||||
${toList namespace.funcs}
|
|
||||||
''
|
|
||||||
|
|
||||||
in show
|
|
||||||
```
|
|
||||||
|
|
||||||
This would render [the logging namespace][logns] as [this markdown][lognsmd].
|
|
||||||
|
|
||||||
[logns]: https://github.com/Xe/pahi/blob/5ea1184c09df4e657524f9d5e77941cda5560d9a/olin-spec/ns/log.dhall
|
|
||||||
[lognsmd]: https://github.com/Xe/pahi/blob/5ea1184c09df4e657524f9d5e77941cda5560d9a/olin-spec/ns/log.md
|
|
||||||
|
|
||||||
It seems like overkill to document things like this (and at some level it is),
|
|
||||||
but I plan to take advantage of this later when I need to do things like
|
|
||||||
generate C/Rust/Go/TinyGo bindings for the entire specification at once. I also
|
|
||||||
have always wanted to document something so precisely like this, and now I get
|
|
||||||
the chance.
|
|
||||||
|
|
||||||
pa'i is just over a week old at this point, and as such it is NOT
|
|
||||||
[feature-complete with the reference Olin interpreter][compattodo]. I'm working
|
|
||||||
on it though. I'm kinda burnt out from work, and even though working on this
|
|
||||||
project helps me relax (don't ask me how, I don't understand either) I have
|
|
||||||
limits and will take this slowly and carefully to ensure that it stays
|
|
||||||
compatible with all of the code I have already written in Olin's repo. Thanks to
|
|
||||||
[go-flag][goflags], I might actually be able to get it mostly flag-compatible.
|
|
||||||
We'll see though.
|
|
||||||
|
|
||||||
[compattodo]: https://github.com/Xe/pahi/issues/1
|
|
||||||
[goflags]: https://crates.io/crates/go-flag
|
|
||||||
|
|
||||||
I have also designed a placeholder logo for pa'i. Here it is:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
It might be changed in the future, but this is what I am going with for now. The
|
|
||||||
circuit traces all spell out messages of love (inspired from the Senzar runes of
|
|
||||||
the [WingMakers][wingmakers]). The text on top of the microprocessor reads pa'i
|
|
||||||
in [zbalermorna][zbalermorna], a constructed writing script for Lojban. The text
|
|
||||||
on the side probably needs to be revised, but it says something along the lines
|
|
||||||
of "a future after programs".
|
|
||||||
|
|
||||||
[wingmakers]: https://www.wingmakers.us/wingmakersorig/wingmakers/ancient_arrow_project.shtml
|
|
||||||
[zbalermorna]: https://mw.lojban.org/images/b/b3/ZLM4_Writeup_v2.pdf
|
|
||||||
|
|
||||||
pa'i is chugging along. When I have closed the [compatibility todo
|
|
||||||
list][compattodo] for all of the Olin API calls, I'll write more. For now, pa'i
|
|
||||||
is a very complicated tool that lets you print "Hello, world" in new and
|
|
||||||
exciting ways (this will change once I get resource calls into it), but it's
|
|
||||||
getting there.
|
|
||||||
|
|
||||||
I hope this was interesting. Be well.
|
|
||||||
|
|
@ -1,52 +0,0 @@
|
||||||
---
|
|
||||||
title: "New Site Feature: Patron Thanks Page"
|
|
||||||
date: 2020-02-29
|
|
||||||
---
|
|
||||||
|
|
||||||
# New Site Feature: Patron Thanks Page
|
|
||||||
|
|
||||||
I've added a [patron thanks page](/patrons) to my site. I've been getting a
|
|
||||||
significant amount of money per month from my patrons and I feel this is a good
|
|
||||||
way to acknowledge them and thank them for their patronage. I wanted to have it
|
|
||||||
be _as simple as possible_, so I made it fetch a list of dollar amounts.
|
|
||||||
|
|
||||||
Here are some things I learned while writing this:
|
|
||||||
|
|
||||||
- If you are going to interact with the patreon API in go, use
|
|
||||||
[`github.com/mxpv/patreon-go`][patreongo], not `gopkg.in/mxpv/patreon-go.v1`
|
|
||||||
or `gopkg.in/mxpv/patreon-go.v2`. The packages on gopkg.in are NOT compatible
|
|
||||||
with Go modules in very bizarre ways.
|
|
||||||
- When using refresh tokens in OAuth2, do not set the expiry date to be
|
|
||||||
_negative_ like the patreon-go examples show. This will brick your token and
|
|
||||||
make you have to reprovision it.
|
|
||||||
- Patreon clients can either be for API version 1 or API version 2. There is no
|
|
||||||
way to have a Patreon token that works for both API versions.
|
|
||||||
- The patreon-go package only supports API version 1 and doesn't document this
|
|
||||||
anywhere.
|
|
||||||
- Patreon's error messages are vague and not helpful when trying to figure out
|
|
||||||
that you broke your token with a negative expiry date.
|
|
||||||
- I may need to set the Patreon information every month for the rest of the time
|
|
||||||
I maintain this site code. This could get odd. I made a guide for myself in
|
|
||||||
the [docs folder of the site repo][docsfolder].
|
|
||||||
- The Patreon API doesn't let you submit new posts. I wanted to add Patreon to
|
|
||||||
my syndication server, but apparently that's impossible. My [RSS
|
|
||||||
feed](/blog.rss), [Atom feed](/blog.atom) and [JSON feed](/blog.json) should
|
|
||||||
let you keep up to date in the meantime.
|
|
||||||
|
|
||||||
Let me know how you like this. I went back and forth on displaying monetary
|
|
||||||
amounts on that page, but ultimately decided not to show them there for
|
|
||||||
confidentiality reasons. If this is a bad idea, please let me know and I can put
|
|
||||||
the money amounts back.
|
|
||||||
|
|
||||||
I'm working on a more detailed post about [pa'i][pahi] that includes benchmarks
|
|
||||||
for some artificial and realistic workloads. I'm also working on integrating it
|
|
||||||
into the [wamscloud][wasmcloud] prototype, but it's fairly slow going at the
|
|
||||||
moment.
|
|
||||||
|
|
||||||
Be well.
|
|
||||||
|
|
||||||
[patreongo]: https://github.com/mxpv/patreon-go
|
|
||||||
[docsfolder]: https://github.com/Xe/site/tree/master/docs
|
|
||||||
[pahi]: https://github.com/Xe/pahi
|
|
||||||
[wasmcloud]: https://tulpa.dev/within/wasmcloud
|
|
||||||
|
|
||||||
|
|
@ -1,395 +0,0 @@
|
||||||
---
|
|
||||||
title: How to Setup Prometheus, Grafana and Loki on NixOS
|
|
||||||
date: 2020-11-20
|
|
||||||
tags:
|
|
||||||
- nixos
|
|
||||||
- prometheus
|
|
||||||
- grafana
|
|
||||||
- loki
|
|
||||||
- promtail
|
|
||||||
---
|
|
||||||
|
|
||||||
# How to Setup Prometheus, Grafana and Loki on NixOS
|
|
||||||
|
|
||||||
When setting up services on your home network, sometimes you have questions
|
|
||||||
along the lines of "how do I know that things are working?". In this blogpost we
|
|
||||||
will go over a few tools that you can use to monitor and visualize your machine
|
|
||||||
state so you can answer that. Specifically we are going to use the following
|
|
||||||
tools to do this:
|
|
||||||
|
|
||||||
- [Grafana](https://grafana.com/) for creating pretty graphs and managing
|
|
||||||
alerts
|
|
||||||
- [Prometheus](https://prometheus.io/) for storing metrics and as a common
|
|
||||||
metrics format
|
|
||||||
- [Prometheus node_exporter](https://github.com/prometheus/node_exporter) for
|
|
||||||
deriving metrics from system state
|
|
||||||
- [Loki](https://grafana.com/oss/loki/) as a central log storage point
|
|
||||||
- [promtail](https://grafana.com/docs/loki/latest/clients/promtail/) to push
|
|
||||||
logs to Loki
|
|
||||||
|
|
||||||
Let's get going!
|
|
||||||
|
|
||||||
[Something to note: in here you might see domains using the `.pele` top-level
|
|
||||||
domain. This domain will likely not be available on your home network. See <a
|
|
||||||
href="/blog/series/site-to-site-wireguard">this series</a> on how to set up
|
|
||||||
something similar for your home network. If you don't have such a setup, replace
|
|
||||||
anything that ends in `.pele` with whatever you normally use for
|
|
||||||
this.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
## Grafana
|
|
||||||
|
|
||||||
Grafana is a service that handles graphing and alerting. It also has some nice
|
|
||||||
tools to create dashboards. Here we will be using it for a few main purposes:
|
|
||||||
|
|
||||||
- Exploring what metrics are available
|
|
||||||
- Reading system logs
|
|
||||||
- Making graphs and dashboards
|
|
||||||
- Creating alerts over metrics or lack of metrics
|
|
||||||
|
|
||||||
Let's configure Grafana on a machine. Open that machine's `configuration.nix` in
|
|
||||||
an editor and add the following to it:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
# hosts/chrysalis/configuration.nix
|
|
||||||
{ config, pkgs, ... }: {
|
|
||||||
# grafana configuration
|
|
||||||
services.grafana = {
|
|
||||||
enable = true;
|
|
||||||
domain = "grafana.pele";
|
|
||||||
port = 2342;
|
|
||||||
addr = "127.0.0.1";
|
|
||||||
};
|
|
||||||
|
|
||||||
# nginx reverse proxy
|
|
||||||
services.nginx.virtualHosts.${config.services.grafana.domain} = {
|
|
||||||
locations."/" = {
|
|
||||||
proxyPass = "http://127.0.0.1:${toString config.services.grafana.port}";
|
|
||||||
proxyWebsockets = true;
|
|
||||||
};
|
|
||||||
};
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
[If you have a <a href="/blog/site-to-site-wireguard-part-3-2019-04-11">custom
|
|
||||||
TLS Certificate Authority</a>, you can set up HTTPS for this deployment. See <a
|
|
||||||
href="https://github.com/Xe/nixos-configs/blob/master/common/sites/grafana.akua.nix">here</a>
|
|
||||||
for an example of doing this. If this server is exposed to the internet, you can
|
|
||||||
use a certificate from <a
|
|
||||||
href="https://nixos.wiki/wiki/Nginx#TLS_reverse_proxy">Let's Encrypt</a> instead
|
|
||||||
of your own Certificate Authority.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
Then you will need to deploy it to your cluster with `nixops deploy`:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ nixops deploy -d home
|
|
||||||
```
|
|
||||||
|
|
||||||
Now open the Grafana server in your browser at http://grafana.pele and login
|
|
||||||
with the super secure default credentials of admin/admin. Grafana will ask you
|
|
||||||
to change your password. Please change it to something other than admin.
|
|
||||||
|
|
||||||
This is all of the setup we will do with Grafana for now. We will come back to
|
|
||||||
it later.
|
|
||||||
|
|
||||||
## Prometheus
|
|
||||||
|
|
||||||
> Prometheus was punished by the gods by giving the gift of knowledge to man. He
|
|
||||||
> was cast into the bowels of the earth and pecked by birds.
|
|
||||||
Oracle Turret, Portal 2
|
|
||||||
|
|
||||||
Prometheus is a service that reads metrics from other services, stores them and
|
|
||||||
allows you to search and aggregate them. Let's add it to our `configuration.nix`
|
|
||||||
file:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
# hosts/chrysalis/configuration.nix
|
|
||||||
services.prometheus = {
|
|
||||||
enable = true;
|
|
||||||
port = 9001;
|
|
||||||
};
|
|
||||||
```
|
|
||||||
|
|
||||||
Now let's deploy this config to the cluster with `nixops deploy`:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ nixops deploy -d home
|
|
||||||
```
|
|
||||||
|
|
||||||
And let's configure Grafana to read from Prometheus. Open Grafana and click on
|
|
||||||
the gear to the left side of the page. The `Data Sources` tab should be active.
|
|
||||||
If it is not active, click on `Data Sources`. Then click "add data source" and
|
|
||||||
choose Prometheus. Set the URL to `http://127.0.0.1:9001` (or with whatever port
|
|
||||||
you configured above) and leave everything set to the default values. Click
|
|
||||||
"Save & Test". If there is an error, be sure to check the port number.
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
Now let's start getting some data into Prometheus with the node exporter.
|
|
||||||
|
|
||||||
### Node Exporter Setup
|
|
||||||
|
|
||||||
The Prometheus node exporter exposes a lot of information about systems ranging
|
|
||||||
from memory, disk usage and even systemd service information. There are also
|
|
||||||
some [other
|
|
||||||
collectors](https://search.nixos.org/options?channel=20.09&query=prometheus.exporters+enable)
|
|
||||||
you can set up based on your individual setup, however we are going to enable
|
|
||||||
only the node collector here.
|
|
||||||
|
|
||||||
In your `configuration.nix`, add an exporters block and configure the node
|
|
||||||
exporter under `services.prometheus`:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
# hosts/chrysalis/configuration.nix
|
|
||||||
services.prometheus = {
|
|
||||||
exporters = {
|
|
||||||
node = {
|
|
||||||
enable = true;
|
|
||||||
enabledCollectors = [ "systemd" ];
|
|
||||||
port = 9002;
|
|
||||||
};
|
|
||||||
};
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
Now we need to configure Prometheus to read metrics from this exporter. In your
|
|
||||||
`configuration.nix`, add a `scrapeConfigs` block under `services.prometheus`
|
|
||||||
that points to the node exporter we configured just now:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
# hosts/chrysalis/configuration.nix
|
|
||||||
services.prometheus = {
|
|
||||||
# ...
|
|
||||||
|
|
||||||
scrapeConfigs = [
|
|
||||||
{
|
|
||||||
job_name = "chrysalis";
|
|
||||||
static_configs = [{
|
|
||||||
targets = [ "127.0.0.1:${toString config.services.prometheus.exporters.node.port}" ];
|
|
||||||
}];
|
|
||||||
}
|
|
||||||
];
|
|
||||||
|
|
||||||
# ...
|
|
||||||
}
|
|
||||||
|
|
||||||
# ...
|
|
||||||
```
|
|
||||||
|
|
||||||
[The complicated expression in the target above allows you to change the port of
|
|
||||||
the node exporter and ensure that Prometheus will always be pointing at the
|
|
||||||
right port!](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
Now we can deploy this to your cluster with nixops:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ nixops deploy -d home
|
|
||||||
```
|
|
||||||
|
|
||||||
Open the Explore tab in Grafana and type in the following expression:
|
|
||||||
|
|
||||||
```
|
|
||||||
node_memory_MemFree_bytes
|
|
||||||
```
|
|
||||||
|
|
||||||
and hit shift-enter (or click the "Run Query" button in the upper left side of
|
|
||||||
the screen). You should see a graph showing you the amount of ram that is free
|
|
||||||
on the host, something like this:
|
|
||||||
|
|
||||||
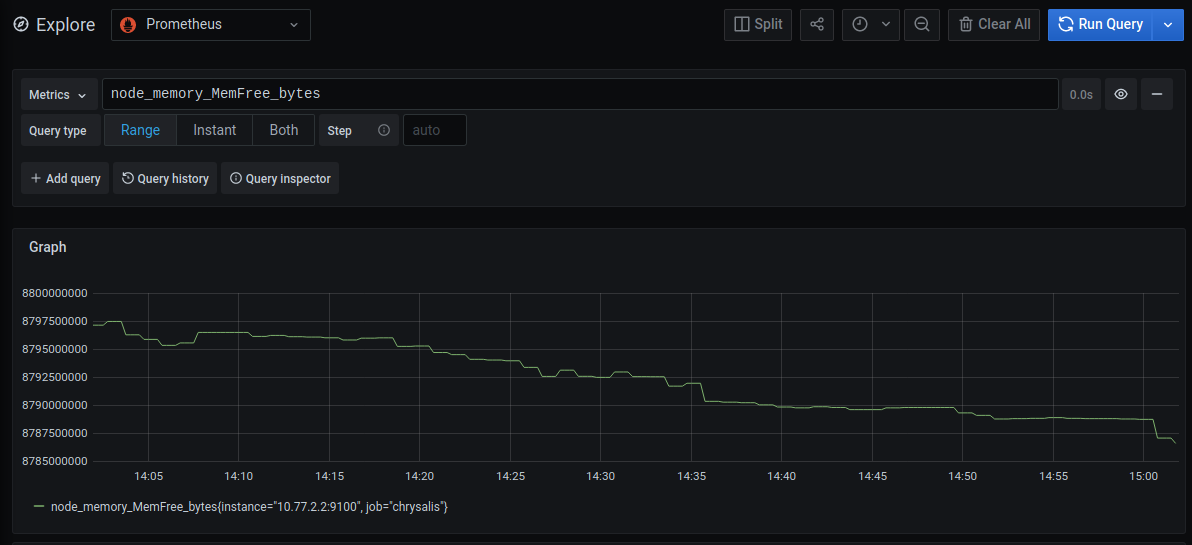
|
|
||||||
|
|
||||||
If you want to query other fields, you can type in `node_` into the searchbox
|
|
||||||
and autocomplete will show what is available. For a full list of what is
|
|
||||||
available, open the node exporter metrics route in your browser and look through
|
|
||||||
it.
|
|
||||||
|
|
||||||
## Grafana Dashboards
|
|
||||||
|
|
||||||
Now that we have all of this information about our machine, let's create a
|
|
||||||
little dashboard for it and set up a few alerts.
|
|
||||||
|
|
||||||
Click on the plus icon on the left side of the Grafana UI to create a new
|
|
||||||
dashboard. It will look something like this:
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
In Grafana terminology, everything you see in a dashboard is inside a panel.
|
|
||||||
Let's create a new panel to keep track of memory usage for our server. Click
|
|
||||||
"Add New Panel" and you will get a screen that looks like this:
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
Let's make this keep track of free memory. Write "Memory Free" in the panel
|
|
||||||
title field on the right. Write the following query in the textbox next to the
|
|
||||||
dropdown labeled "Metrics":
|
|
||||||
|
|
||||||
```
|
|
||||||
node_memory_MemFree_bytes
|
|
||||||
```
|
|
||||||
|
|
||||||
and set the legend to `{{job}}`. You should get a graph that looks something
|
|
||||||
like this:
|
|
||||||
|
|
||||||
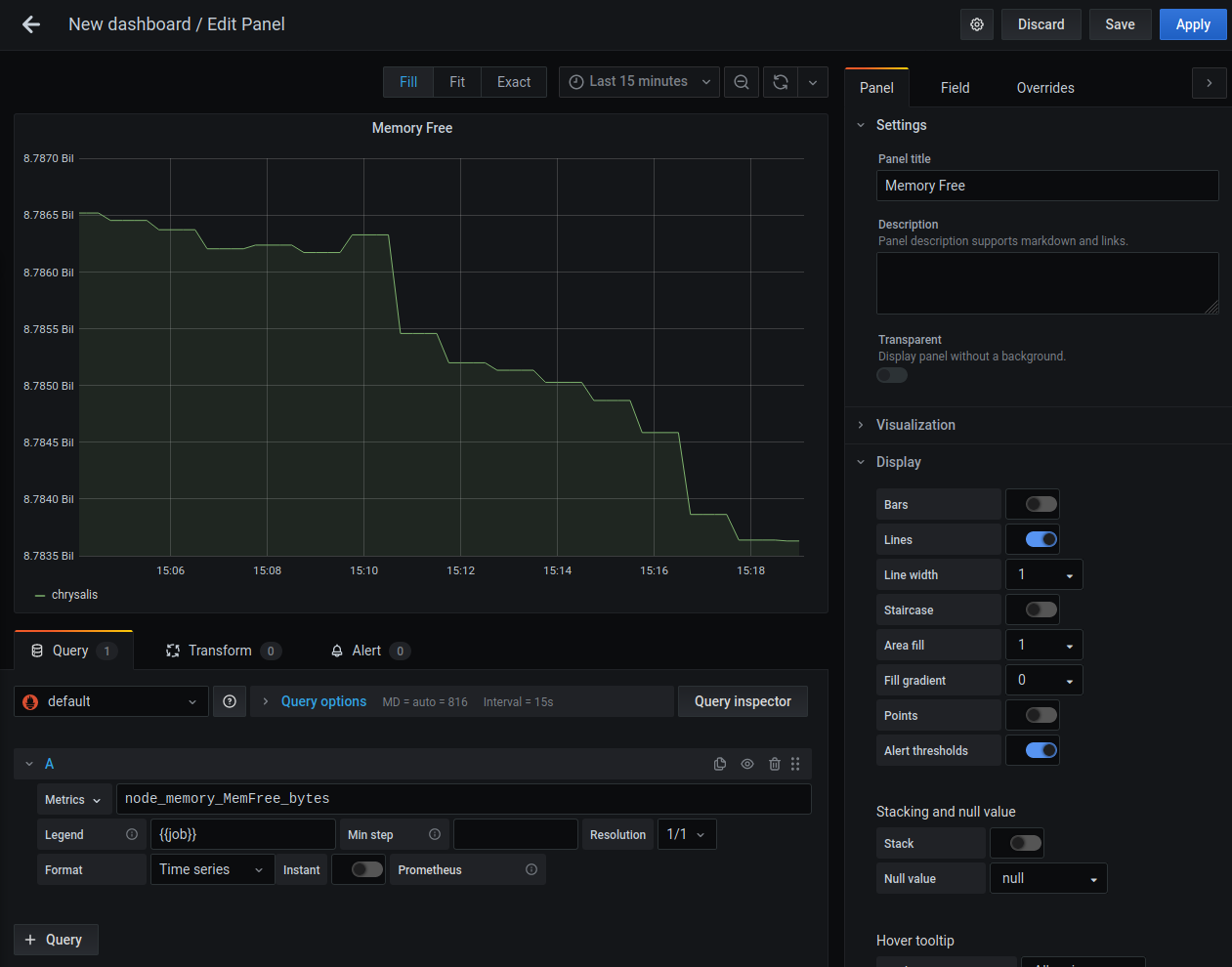
|
|
||||||
|
|
||||||
This will show you how much memory is free on each machine you are monitoring
|
|
||||||
with Prometheus' node exporter. Now let's configure an alert for the amount of
|
|
||||||
free memory being low (where "low" means less than 64 megabytes of ram free).
|
|
||||||
|
|
||||||
Hit save in the upper right corner of the Grafana UI and give your dashboard a
|
|
||||||
name, such as "Home Cluster Status". Now open the "Memory Free" panel for
|
|
||||||
editing (click on the name and then click "Edit"), click the "Alert" tab, and
|
|
||||||
click the "Create Alert" button. Let's configure it to do the following:
|
|
||||||
|
|
||||||
- Check if free memory gets below 64 megabytes (64000000 bytes)
|
|
||||||
- Send the message "Running out of memory!" when the alert fires
|
|
||||||
|
|
||||||
You can do that with a configuration like this:
|
|
||||||
|
|
||||||
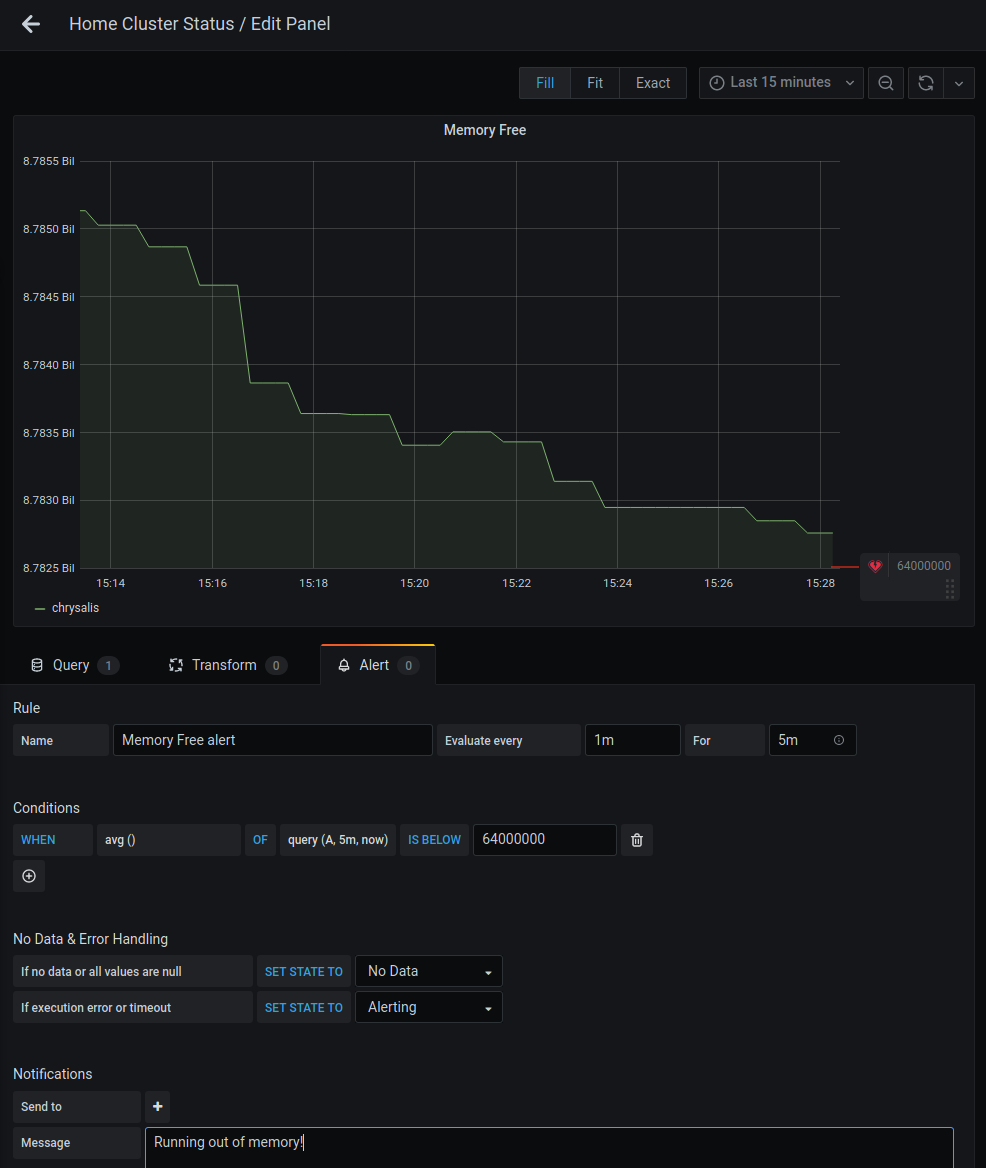
|
|
||||||
|
|
||||||
Save the changes to apply this config.
|
|
||||||
|
|
||||||
[Wait a minute. Where will this alert go to?](conversation://Mara/hmm)
|
|
||||||
|
|
||||||
It will only show up on the alerts page:
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
But we can add a notification channel to customize this. Click on the
|
|
||||||
Notification Channels tab and then click "New Channel". It should look something
|
|
||||||
like this:
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
You can send notifications to many services, but let's send one to Discord this
|
|
||||||
time. Acquire a Discord webhook link from somewhere and paste it in the Webhook
|
|
||||||
URL field. Name it something like "Discord". It may also be a good idea to make
|
|
||||||
this the default notification channel using the "Default" checkbox under the
|
|
||||||
Notification Settings, so that our existing alert will show up in Discord when
|
|
||||||
the system runs out of memory.
|
|
||||||
|
|
||||||
You can configure other alerts like this so you can monitor any other node
|
|
||||||
metrics you want.
|
|
||||||
|
|
||||||
[You can also monitor for the _lack_ of data on particular metrics. If something
|
|
||||||
that should always be reported suddenly isn't reported, it may be a good
|
|
||||||
indicator that a server went down. You can also add other services to your
|
|
||||||
`scrapeConfigs` settings so you can monitor things that expose metrics to
|
|
||||||
Prometheus at `/metrics`.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
Now that we have metrics configured, let's enable Loki for logging.
|
|
||||||
|
|
||||||
## Loki
|
|
||||||
|
|
||||||
Loki is a log aggregator created by the people behind Grafana. Here we will use
|
|
||||||
it as a target for all system logs. Unfortunately, the Loki NixOS module is very
|
|
||||||
basic at the moment, so we will need to configure it with our own custom yaml
|
|
||||||
file. Create a file in your `configuration.nix` folder called `loki.yaml` and
|
|
||||||
copy in the config from [this
|
|
||||||
gist](https://gist.github.com/Xe/c3c786b41ec2820725ee77a7af551225):
|
|
||||||
|
|
||||||
Then enable Loki with your config in your `configuration.nix` file:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
# hosts/chrysalis/configuration.nix
|
|
||||||
services.loki = {
|
|
||||||
enable = true;
|
|
||||||
configFile = ./loki-local-config.yaml;
|
|
||||||
};
|
|
||||||
```
|
|
||||||
|
|
||||||
Promtail is a tool made by the Loki team that sends logs into Loki. Create a
|
|
||||||
file called `promtail.yaml` in the same folder as `configuration.nix` with the
|
|
||||||
following contents:
|
|
||||||
|
|
||||||
```yaml
|
|
||||||
server:
|
|
||||||
http_listen_port: 28183
|
|
||||||
grpc_listen_port: 0
|
|
||||||
|
|
||||||
positions:
|
|
||||||
filename: /tmp/positions.yaml
|
|
||||||
|
|
||||||
clients:
|
|
||||||
- url: http://127.0.0.1:3100/loki/api/v1/push
|
|
||||||
|
|
||||||
scrape_configs:
|
|
||||||
- job_name: journal
|
|
||||||
journal:
|
|
||||||
max_age: 12h
|
|
||||||
labels:
|
|
||||||
job: systemd-journal
|
|
||||||
host: chrysalis
|
|
||||||
relabel_configs:
|
|
||||||
- source_labels: ['__journal__systemd_unit']
|
|
||||||
target_label: 'unit'
|
|
||||||
```
|
|
||||||
|
|
||||||
Now we can add promtail to your `configuration.nix` by creating a systemd
|
|
||||||
service to run it with this snippet:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
# hosts/chrysalis/configuration.nix
|
|
||||||
systemd.services.promtail = {
|
|
||||||
description = "Promtail service for Loki";
|
|
||||||
wantedBy = [ "multi-user.target" ];
|
|
||||||
|
|
||||||
serviceConfig = {
|
|
||||||
ExecStart = ''
|
|
||||||
${pkgs.grafana-loki}/bin/promtail --config.file ${./promtail.yaml}
|
|
||||||
'';
|
|
||||||
};
|
|
||||||
};
|
|
||||||
```
|
|
||||||
|
|
||||||
Now that you have this all set up, you can push this to your cluster with
|
|
||||||
nixops:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ nixops deploy -d home
|
|
||||||
```
|
|
||||||
|
|
||||||
Once that finishes, open up Grafana and configure a new Loki data source with
|
|
||||||
the URL `http://127.0.0.1:3100`:
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
Now that you have Loki set up, let's query it! Open the Explore view in Grafana
|
|
||||||
again, choose Loki as the source, and enter in the query `{job="systemd-journal"}`:
|
|
||||||
|
|
||||||
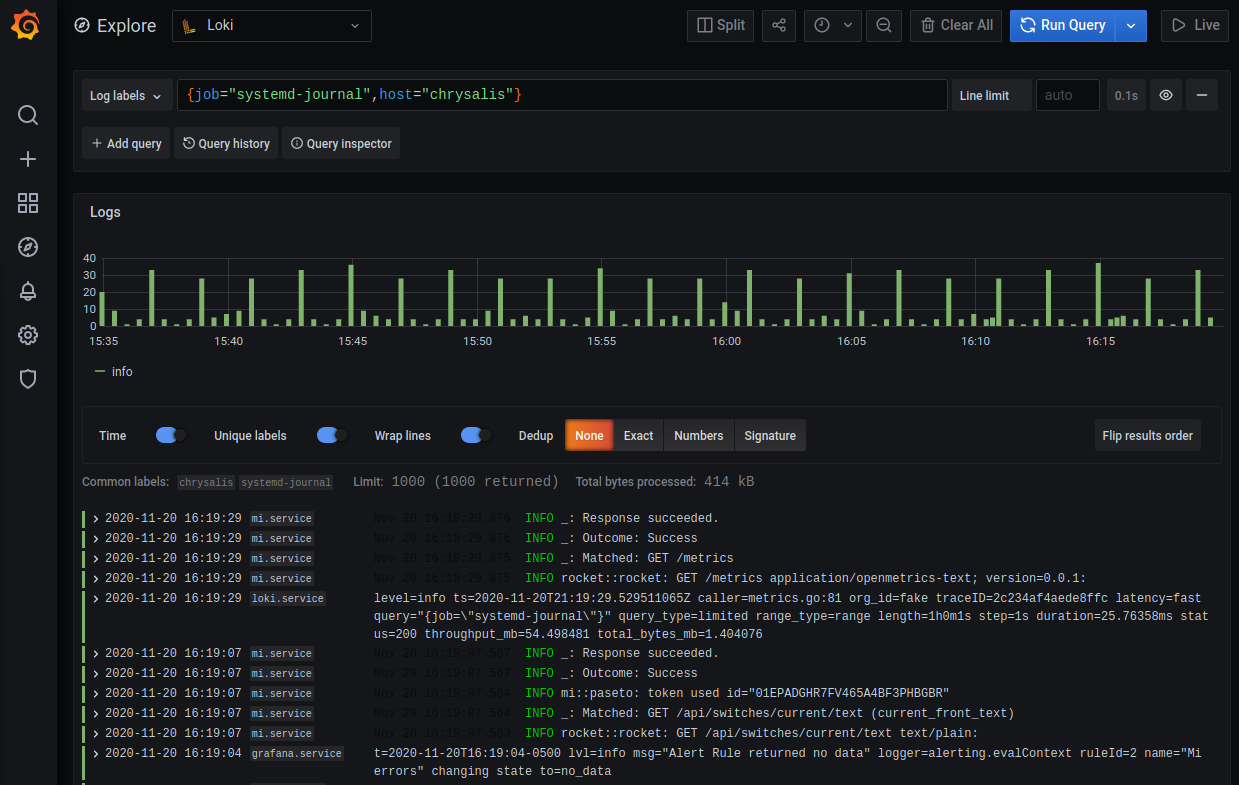
|
|
||||||
|
|
||||||
[You can also add Loki queries like this to dashboards! Loki also lets you query by
|
|
||||||
systemd unit with the `unit` field. If you wanted to search for logs from
|
|
||||||
`foo.service`, you would need a query that looks something like
|
|
||||||
`{job="systemd-journal", unit="foo.service"}` You can do many more complicated
|
|
||||||
things with Loki. Look <a
|
|
||||||
href="https://grafana.com/docs/grafana/latest/datasources/loki/#search-expression">here
|
|
||||||
</a> for more information on what you can query. As of the time of writing this
|
|
||||||
blogpost, you are currently unable to make Grafana alerts based on Loki queries
|
|
||||||
as far as I am aware.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
This barely scrapes the surface of what you can accomplish with a setup like
|
|
||||||
this. Using more fancy setups you can alert on the rate of metrics changing. I
|
|
||||||
plan to make NixOS modules to make this setup easier in the future. There is
|
|
||||||
also a set of options in
|
|
||||||
[services.grafana.provision](https://search.nixos.org/options?channel=20.09&from=0&size=30&sort=relevance&query=grafana.provision)
|
|
||||||
that can make it easier to automagically set up Grafana with per-host
|
|
||||||
dashboards, alerts and all of the data sources that are outlined in this post.
|
|
||||||
|
|
||||||
The setup in this post is quite meager, but it should be enough to get you
|
|
||||||
started with whatever you need to monitor. Adding Prometheus metrics to your
|
|
||||||
services will go a long way in terms of being able to better monitor things in
|
|
||||||
production, do not be afraid to experiment!
|
|
||||||
|
|
@ -1,103 +0,0 @@
|
||||||
---
|
|
||||||
title: "ReConLangMo 1: Name, Context, History"
|
|
||||||
date: 2020-05-05
|
|
||||||
series: reconlangmo
|
|
||||||
tags:
|
|
||||||
- conlang
|
|
||||||
- lewa
|
|
||||||
---
|
|
||||||
|
|
||||||
# ReConLangMo 1: Name, Context, History
|
|
||||||
|
|
||||||
I've been curious about how language works for a very long time. This curiosity
|
|
||||||
has lead me down many fascinating rabbit holes, but for a long time I have
|
|
||||||
either been cribbing off of other people's work or studying natural languages
|
|
||||||
that don't have a cohesive plan or core to them. [Constructed
|
|
||||||
Languages][conlangs] (or conlangs as I will probably be calling them from here
|
|
||||||
on out) are a simpler model of this. You might be familiar with
|
|
||||||
[Klingon][tlhnganhol] from the Star Trek series, the [various forms of
|
|
||||||
Elvish][elvish] as described by J. R. R. Tolkien or [Dothraki][dothraki] from
|
|
||||||
Game of Thrones. This series will show an example of how one of those kinds of
|
|
||||||
languages are created.
|
|
||||||
|
|
||||||
[conlangs]: https://en.wikipedia.org/wiki/Constructed_language
|
|
||||||
[tlhnganhol]: https://en.wikipedia.org/wiki/Klingon_language
|
|
||||||
[elvish]: https://en.wikipedia.org/wiki/Elvish_languages
|
|
||||||
[dothraki]: https://en.wikipedia.org/wiki/Dothraki_language
|
|
||||||
|
|
||||||
Recently a challenge came up on [/r/conlangs][rconlangs] called
|
|
||||||
[ReConLangMo][reconlangmo] and I've decided to take a stab at this and flesh
|
|
||||||
this out into a [personal language][perslang].
|
|
||||||
|
|
||||||
[rconlangs]: https://www.reddit.com/r/conlangs/
|
|
||||||
[reconlangmo]: https://www.reddit.com/r/conlangs/comments/gbgvu0/reconlangmo_2020/
|
|
||||||
[perslang]: https://en.wikipedia.org/wiki/Artistic_language#Personal_languages
|
|
||||||
|
|
||||||
This post will be the first in a series (with articles to be listed below) and
|
|
||||||
is following the prompt made [here][reconlangmo1prompt].
|
|
||||||
|
|
||||||
[reconlangmo1prompt]: https://www.reddit.com/r/conlangs/comments/gd8z18/reconlangmo_1_name_context_and_history/
|
|
||||||
|
|
||||||
## L'ewa Overview
|
|
||||||
|
|
||||||
The language I am going to create will be called L'ewa (⁄l.ʔɛ.wa⁄, also
|
|
||||||
romanized lewa for filesystems). This word is identical in English and in L'ewa.
|
|
||||||
It means "is a language". The name came to me in a shower a while ago and I'm
|
|
||||||
not entirely sure where it came from.
|
|
||||||
|
|
||||||
This language is being designed as a personal language to help me keep a diary
|
|
||||||
(more on that later) and to act as a testbed for writing a computational
|
|
||||||
knowledge engine, much like IBM's Watson. I do not expect anyone else to use
|
|
||||||
this language. I may pull this language into fiction (if that ever gets off the
|
|
||||||
ground) or into other projects as it makes sense.
|
|
||||||
|
|
||||||
Some of the high level things I want to try in this language are ways to make me
|
|
||||||
think differently. I'm following the weak form of the [Sapir-Whorf
|
|
||||||
hypothesis][sapirwhorf] by this logic. I want to see what would happen if I give
|
|
||||||
myself a tool that I can use to help myself think in different ways. Other
|
|
||||||
features I plan to include are:
|
|
||||||
|
|
||||||
[sapirwhorf]: https://en.wikipedia.org/wiki/Linguistic_relativity
|
|
||||||
|
|
||||||
- A [seximal][seximal] number system
|
|
||||||
- A predicate-argument system similar to [Lojban][lojban]
|
|
||||||
- Nounlessness (only having verbs for content words) like [Salishan][salishan]
|
|
||||||
languages
|
|
||||||
- An [a-priori][apriori] (or made up) vocabulary
|
|
||||||
- Grammatical markers for the identity of the thinker of a sentence/phrase/word
|
|
||||||
- Make each grammatical feature and word logical, or working in one way only
|
|
||||||
- Typeable with standard QWERTY en-US keyboards
|
|
||||||
- A decorative script that I'll turn into a font
|
|
||||||
|
|
||||||
[seximal]: https://www.seximal.net
|
|
||||||
[lojban]: https://lojban.pw/cll/uncll-1.2.6/xhtml_section_chunks/chapter-tour.html#section-bridi
|
|
||||||
[salishan]: https://en.wikipedia.org/wiki/Salishan_languages
|
|
||||||
[apriori]: https://en.wikipedia.org/wiki/Constructed_language#A_priori_and_a_posteriori_languages
|
|
||||||
|
|
||||||
## L'wea as A Diary Language
|
|
||||||
|
|
||||||
When I was younger, I used to keep a diary/journal file on my computers off and
|
|
||||||
on. I was detailed about what I was feeling and what I was considering and going
|
|
||||||
through. This all ended abruptly after my parents were snooping through my
|
|
||||||
computer in middle school and discovered that I was questioning fundamental
|
|
||||||
aspects of myself like my gender. I have never really felt comfortable keeping a
|
|
||||||
diary file since then. I have made a few attempts at this (including by using a
|
|
||||||
dedicated diary machine, air-gapped TempleOS machines and the like), but they
|
|
||||||
all feel too vulnerable and open for anyone to read them.
|
|
||||||
|
|
||||||
This is my logic for using a language that I create for myself. If people really
|
|
||||||
want to go through and take the time to learn the ins and outs of a tool I
|
|
||||||
created for myself to archive my personal thoughts, they probably deserve to be
|
|
||||||
able to read them. Otherwise, this would allow me to write my diary from pretty
|
|
||||||
much anywhere, even in plain sight out in public. People can't shoulder-surf and
|
|
||||||
read what they literally cannot understand.
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
I plan to continue going through this series as the prompts come out and will
|
|
||||||
put my responses on my blog along with explanations, analysis and sample code
|
|
||||||
(where relevant). I will probably also reformat these posts (and relevant
|
|
||||||
dictionary files) to an eBook and later into a reference grammar book.
|
|
||||||
|
|
||||||
Like I said though, this project is for myself. I do not expect this language to
|
|
||||||
change the world for anyone but me. Let's see where this rabbit hole goes.
|
|
||||||
|
|
@ -1,131 +0,0 @@
|
||||||
---
|
|
||||||
title: "ReConLangMo 2: Phonology & Writing"
|
|
||||||
date: 2020-05-08
|
|
||||||
series: reconlangmo
|
|
||||||
tags:
|
|
||||||
- conlang
|
|
||||||
- lewa
|
|
||||||
---
|
|
||||||
|
|
||||||
# ReConLangMo 2: Phonology & Writing
|
|
||||||
|
|
||||||
Continuing from [the last post][rclm1], one of the next steps in this process is
|
|
||||||
to outline the phonology and basic phonotactics of L'ewa. A language's phonology
|
|
||||||
is the set of sounds that are allowed to be in words. The phonotactics of a
|
|
||||||
language help people understand where the boundaries between syllables are. I
|
|
||||||
will then describe my plans for the L'ewa orthography and how L'ewa is
|
|
||||||
romanized. This is a response to the prompt made [here][rclm2prompt].
|
|
||||||
|
|
||||||
[rclm1]: https://christine.website/blog/reconlangmo-1-name-ctx-history-2020-05-05
|
|
||||||
[rclm2prompt]: https://www.reddit.com/r/conlangs/comments/gfp3hw/reconlangmo_2_phonology_writing/
|
|
||||||
|
|
||||||
## Phonology
|
|
||||||
|
|
||||||
I am taking inspiration from Lojban, Esperanto, Mandarin Chinese and English to
|
|
||||||
design the phonology of L'ewa. All of the phonology will be defined using the
|
|
||||||
[International Phonetic Alphabet][ipa]. If you want to figure out how to
|
|
||||||
pronounce these sounds, a lazy trick is to google them. Wikipedia will have a
|
|
||||||
perfectly good example to use as a reference. There are two kinds of sounds in
|
|
||||||
L'ewa, consonants and vowels.
|
|
||||||
|
|
||||||
[ipa]: https://en.wikipedia.org/wiki/International_Phonetic_Alphabet
|
|
||||||
|
|
||||||
### Consonants
|
|
||||||
|
|
||||||
*Consonant inventory*: /d f g h j k l m n p q s t w ʃ ʒ ʔ ʙ̥/
|
|
||||||
|
|
||||||
| Manner/Place | Bilabial | Alveolar | Palato-alveolar | Palatal | Velar | Labio-velar | Uvular | Glottal |
|
|
||||||
|---------------------|----------|----------|-----------------|---------|-------|-------------|--------|---------|
|
|
||||||
| Nasal | m | n | | | | | | |
|
|
||||||
| Stop | p | t d | | | k g | | q | ʔ |
|
|
||||||
| Fricative | f | s | ʃ ʒ | | | | | h |
|
|
||||||
| Approximant | | | | j | | w | | |
|
|
||||||
| Trill | ʙ̥ | r | | | | | | |
|
|
||||||
| Lateral approximant | | l | | | | | | |
|
|
||||||
|
|
||||||
The weirdest consonant is /ʙ̥/, which is a voiceless bilabial trill, or blowing
|
|
||||||
air through your lips without making sound. This is intended to imitate a noise
|
|
||||||
an orca would make.
|
|
||||||
|
|
||||||
### Vowels
|
|
||||||
|
|
||||||
*Vowel inventory*: /a ɛ i o u/
|
|
||||||
|
|
||||||
*Diphthongs*: au, oi, ua, ue, uo, ai, ɛi
|
|
||||||
|
|
||||||
| | Front | Back |
|
|
||||||
|----------|-------|------|
|
|
||||||
| High | i | u |
|
|
||||||
| High-mid | | o |
|
|
||||||
| Low-mid | ɛ | |
|
|
||||||
| Low | a | |
|
|
||||||
|
|
||||||
## Phonotactics
|
|
||||||
|
|
||||||
I plan to have two main kinds of words in L'ewa. I plan to have content and
|
|
||||||
particle words. The content words will refer to things, properties, or actions
|
|
||||||
(such as `tool`, `red`, `run`) and the particle words will change how the
|
|
||||||
grammar of a sentence works (such as `the` or prepositions).
|
|
||||||
|
|
||||||
The main kind of content word is a root word, and they will be in the following
|
|
||||||
forms:
|
|
||||||
|
|
||||||
- CVCCV (/ʒa.sko/)
|
|
||||||
- CCVCV (/lʔ.ɛwa/)
|
|
||||||
|
|
||||||
Particles will mostly fall into the following forms:
|
|
||||||
|
|
||||||
- V (/a/)
|
|
||||||
- VV (/ai/)
|
|
||||||
- CV (/ba/)
|
|
||||||
- CVV (/bai/)
|
|
||||||
- CV'V (/baʔ.i)
|
|
||||||
|
|
||||||
Proper names _should_ end with consonants, but there is no hard requirement.
|
|
||||||
|
|
||||||
L'ewa is a stressed language, with stress on the second-to-last (penultimate)
|
|
||||||
syllable. For example, the word "[z]asko" would be pronounced "[Z]Asko".
|
|
||||||
|
|
||||||
Syllables end on stop consonants if one is present in a consonant cluster. Two
|
|
||||||
stop consonants cannot follow eachother in a row.
|
|
||||||
|
|
||||||
## Writing
|
|
||||||
|
|
||||||
I haven't completely fleshed this part out yet, but I want the writing system of
|
|
||||||
L'ewa to be an [abugida][abugida]. This is a kind of written script that has the
|
|
||||||
consonants make the larger shapes but the vowels are small diacritics over the
|
|
||||||
consonants. If the word creation process is done right, you can actually omit
|
|
||||||
the vowels entirely if they are not relevant.
|
|
||||||
|
|
||||||
[abugida]: https://en.wikipedia.org/wiki/Abugida
|
|
||||||
|
|
||||||
I plan to have this script be written by hand with pencils/pen and typed into
|
|
||||||
computers, just like English. This script will also be a left-to-right script
|
|
||||||
like English.
|
|
||||||
|
|
||||||
## Romanisation
|
|
||||||
|
|
||||||
L'ewa's romanization is intentionally simple. Most of the IPA letters keep their
|
|
||||||
letters, but the ones that do not match to Latin letters are listed below:
|
|
||||||
|
|
||||||
| Pronunciation | Spelling |
|
|
||||||
|---------------|----------|
|
|
||||||
| /j/ | *y* |
|
|
||||||
| /ɛ/ | *e* |
|
|
||||||
| /ʃ/ | *x* |
|
|
||||||
| /ʒ/ | *z* |
|
|
||||||
| /ʔ/ | *'* |
|
|
||||||
| /ʙ̥/ | *b* |
|
|
||||||
|
|
||||||
This is designed to make every letter typeable on a standard US keyboard, as
|
|
||||||
well as mapping as many letters as possible on the home row of a QWERTY
|
|
||||||
keyboard.
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
I am still working on the tooling for word creation and the like. I plan to use
|
|
||||||
the [Swaedish lists][swaedish] (this site is having certificate issues at the
|
|
||||||
time of writing this post) to help guide the creation of a base vocabulary. I
|
|
||||||
will go into more detail in the future.
|
|
||||||
|
|
||||||
[swaedish]: https://cals.info/word/list/
|
|
||||||
|
|
@ -1,154 +0,0 @@
|
||||||
---
|
|
||||||
title: "ReConLangMo 3: Morphosyntactic Typology"
|
|
||||||
date: 2020-05-11
|
|
||||||
series: reconlangmo
|
|
||||||
tags:
|
|
||||||
- conlang
|
|
||||||
- lewa
|
|
||||||
---
|
|
||||||
|
|
||||||
# ReConLangMo 3: Morphosyntactic Typology
|
|
||||||
|
|
||||||
In the last post of [this series][reconlangmoseries], we covered the sounds and
|
|
||||||
word patterns of L'ewa. This time we are covering morphosyntactic typology, or
|
|
||||||
how words and sentences are formed out of root words, details about sentences,
|
|
||||||
word order and those kinds of patterns. I'll split each of these into their own
|
|
||||||
headings so it's a bit easier to grok. This is a response to [this
|
|
||||||
prompt][rclm3].
|
|
||||||
|
|
||||||
[reconlangmoseries]: /blog/series/reconlangmo
|
|
||||||
[rclm3]: thttps://www.reddit.com/r/conlangs/comments/ghvo48/reconlangmo_3_morphosyntactic_typology/
|
|
||||||
|
|
||||||
## Word Order
|
|
||||||
|
|
||||||
L'ewa is normally a Subject-Verb-Object (SVO) language like English. However,
|
|
||||||
the word order of a sentence can be changed if it is important to specify some
|
|
||||||
part of the sentence in particular.
|
|
||||||
|
|
||||||
I haven't completely finalized the particles for this, but I'd like to use `ka` to
|
|
||||||
denote the subject, `ke` to denote the verb and `ku` to denote the object. For
|
|
||||||
example if the input sentence is something like:
|
|
||||||
|
|
||||||
```
|
|
||||||
/mi/ /mad.sa/ /lo/ /spa.lo/
|
|
||||||
mi madsa lo spalo
|
|
||||||
I eat an apple
|
|
||||||
```
|
|
||||||
|
|
||||||
You could emphasize the eating with:
|
|
||||||
|
|
||||||
```
|
|
||||||
/kɛ/ /mad.sa/ /ka/ /mi/ /lo/ /spa.lo/
|
|
||||||
[ke] madsa ka mi lo spalo
|
|
||||||
V eat S I an apple
|
|
||||||
```
|
|
||||||
|
|
||||||
(the `ke` is in square brackets here because it is technically not required, but
|
|
||||||
it can make more sense to be explicit in some cases)
|
|
||||||
|
|
||||||
or the apple with:
|
|
||||||
|
|
||||||
```
|
|
||||||
/ku/ /lo/ /spalo/ /kɛ/ /mad.sa/ /mi
|
|
||||||
ku lo spalo ke madsa mi
|
|
||||||
O an apple V eat I
|
|
||||||
```
|
|
||||||
|
|
||||||
L'ewa doesn't really have adjectives or adverbs in the normal indo-european
|
|
||||||
sense, but it does have a way to analytically combine meanings together. For
|
|
||||||
example if `qa'te` is the word for `is fast/quick/rapid in rate`, then saying
|
|
||||||
you are quickly eating (or wolfing food down) would be something like:
|
|
||||||
|
|
||||||
```
|
|
||||||
/qaʔ.tɛ/ /mad.sa/
|
|
||||||
qa'te madsa
|
|
||||||
is fast [kind of] eat
|
|
||||||
```
|
|
||||||
|
|
||||||
These are assumed to be metaphorical by default. It's not always clear what
|
|
||||||
someone would mean by a fast kind of language (would they be referencing
|
|
||||||
[Speedtalk][speedtalk]?)
|
|
||||||
|
|
||||||
[speedtalk]: https://en.wikipedia.org/wiki/Speedtalk
|
|
||||||
|
|
||||||
L'ewa doesn't always require a subject or object if it can be figured out from
|
|
||||||
context. You can just say "rain" instead of "it's raining". By default, the
|
|
||||||
first word in a sentence without an article is the verb. The ka/ke/ku series
|
|
||||||
needs to be used if the word order deviates from Subject-Verb-Object (it
|
|
||||||
functions a lot like the selma'o FA from Lojban).
|
|
||||||
|
|
||||||
## Morphological Typology
|
|
||||||
|
|
||||||
L'ewa is a analytic language. Every single word has only one form and particles
|
|
||||||
are used to modify the meaning or significance of words. There are only two word
|
|
||||||
classes: content and particles.
|
|
||||||
|
|
||||||
### Alignment
|
|
||||||
|
|
||||||
L'ewa is a nominative-accusative language. Other particles may be introduced in
|
|
||||||
the future to help denote the relations that exist in other alignments, but I
|
|
||||||
don't need them yet.
|
|
||||||
|
|
||||||
### Word Classes
|
|
||||||
|
|
||||||
As said before, L'ewa only has two word classes, content (or verbs) and
|
|
||||||
particles to modify the significance or relations between content. There is also
|
|
||||||
a hard limit of two arguments per verb, which should help avoid the problems
|
|
||||||
that Lojban has with its inconsistent usage of the x3, x4 and x5 places.
|
|
||||||
|
|
||||||
As the content words are all technically verbs, there is no real need for a
|
|
||||||
copula. The ka/ke/ku series can also help to break out of other things that
|
|
||||||
modify "noun-phrases" (when those things exist). There are also no nouns,
|
|
||||||
adjectives or adverbs, because analytically combining words completely replaces
|
|
||||||
the need for them.
|
|
||||||
|
|
||||||
Nouns and verbs do not inflect for numbers. If numbers are needed they can be
|
|
||||||
provided, otherwise the default is to assume "one or more".
|
|
||||||
|
|
||||||
## Conscript
|
|
||||||
|
|
||||||
I am still working on the finer details of the conscript for L'ewa, but here is
|
|
||||||
a sneak preview of the letter forms I am playing with (this image below might
|
|
||||||
not render properly in light mode):
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
My inspirations for this script were [zbalermorna][zbalermorna], Hangul, Hanzi,
|
|
||||||
Katakana, Greek, international computer symbols, traditional Japanese art and
|
|
||||||
the [International Phonetic Alphabet][ipa].
|
|
||||||
|
|
||||||
[zbalermorna]: https://mw.lojban.org/images/b/b3/ZLM4_Writeup_v2.pdf
|
|
||||||
[ipa]: https://en.wikipedia.org/wiki/International_Phonetic_Alphabet
|
|
||||||
|
|
||||||
This script is very decorative, and is primarily intended to be used in
|
|
||||||
spellcraft and other artistic uses. It will probably show up in my art from time
|
|
||||||
to time, and will definitely show up in any experimental video production that I
|
|
||||||
work on in the future. I will go into more detail about this in the future, but
|
|
||||||
here is my prototype. Please do let me know what you think about it.
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
As a side note, the words `madsa`, `spalo` and `qa'te` are now official L'ewa
|
|
||||||
words, I guess. The entire vocabulary of the language can now be listed below:
|
|
||||||
|
|
||||||
**Content Words**
|
|
||||||
|
|
||||||
| L'ewa word | IPA | English |
|
|
||||||
| ---------- | --- | ------- |
|
|
||||||
| `l'ewa` | `/lʔ.ɛwa/` | is a language |
|
|
||||||
| `madsa` | `/mad.sa/` | eats/is eating |
|
|
||||||
| `qa'te` | `/qaʔ.tɛ/` | is fast/quick/rapid in rate |
|
|
||||||
| `zasko` | `/ʒa.sko/` | is a plant/is vegetation |
|
|
||||||
| `spalo` | `/spa.lo/` | is an apple |
|
|
||||||
|
|
||||||
**Particles**
|
|
||||||
|
|
||||||
| L'ewa word | IPA | English |
|
|
||||||
| ---------- | --- | ------- |
|
|
||||||
| lo | /lo/ | a, an, indefinite article |
|
|
||||||
| le | /lɛ/ | the, definite article |
|
|
||||||
| ka | /ka/ | subject marker |
|
|
||||||
| ke | /kɛ/ | verb marker |
|
|
||||||
| ku | /ku/ | object marker |
|
|
||||||
| mi | /mi/ | the current speaker |
|
|
||||||
|
|
@ -1,116 +0,0 @@
|
||||||
---
|
|
||||||
title: "ReConLangMo 4: Noun and Verb Morphology"
|
|
||||||
date: 2020-05-15
|
|
||||||
series: reconlangmo
|
|
||||||
tags:
|
|
||||||
- conlang
|
|
||||||
- lewa
|
|
||||||
---
|
|
||||||
|
|
||||||
# ReConLangMo 4: Noun and Verb Morphology
|
|
||||||
|
|
||||||
Last time on [ReConLangMo][reconlangmoseries] I covered word order and some of
|
|
||||||
the finer points about how sentences work. This time we are covering how nouns
|
|
||||||
and verbs get modified (some languages call this conjugation or declension).
|
|
||||||
This is a response to [this prompt][rclm4].
|
|
||||||
|
|
||||||
[reconlangmoseries]: /blog/series/reconlangmo
|
|
||||||
[rclm4]: https://www.reddit.com/r/conlangs/comments/gjvczy/reconlangmo_4_noun_and_verb_morphology/
|
|
||||||
|
|
||||||
## Other Noun Things
|
|
||||||
|
|
||||||
At a high level, noun-phrases can be marked for direct ownership or number. The
|
|
||||||
general pattern is like this:
|
|
||||||
|
|
||||||
```
|
|
||||||
<article> [pronoun] [negation] [number] <verb>
|
|
||||||
```
|
|
||||||
|
|
||||||
## Pronouns
|
|
||||||
|
|
||||||
Here's some of the pronouns:
|
|
||||||
|
|
||||||
| English | L'ewa |
|
|
||||||
| --------------------- | ----- |
|
|
||||||
| me, I | mi |
|
|
||||||
| My system and I | mi'a |
|
|
||||||
| you | ro |
|
|
||||||
| we (all-inclusive) | mi'o |
|
|
||||||
| your system and you | ro'a |
|
|
||||||
| This (near me) | ti |
|
|
||||||
| That (near you) | ta |
|
|
||||||
| That (far away) | tu |
|
|
||||||
|
|
||||||
## Numbers
|
|
||||||
|
|
||||||
Numbers are in [base six][seximal]. Here are a few numerals:
|
|
||||||
|
|
||||||
[seximal]: https://www.seximal.net/
|
|
||||||
|
|
||||||
| Decimal | Seximal | L'ewa |
|
|
||||||
| ------- | ------- | ----- |
|
|
||||||
| 0 | 0 | zo |
|
|
||||||
| 1 | 1 | ja |
|
|
||||||
| 2 | 2 | he |
|
|
||||||
| 3 | 3 | xu |
|
|
||||||
| 4 | 4 | ho |
|
|
||||||
| 5 | 5 | qi |
|
|
||||||
| 6 | 10 | jazo |
|
|
||||||
| 36 | 100 | gau |
|
|
||||||
|
|
||||||
Here are few non-numerals-but-technically-still-numbers-I-guess:
|
|
||||||
|
|
||||||
| English | L'ewa |
|
|
||||||
| --------------- | ----- |
|
|
||||||
| all | to |
|
|
||||||
| some | ra'o |
|
|
||||||
| number-question | so |
|
|
||||||
|
|
||||||
## Negation
|
|
||||||
|
|
||||||
As L'ewa is more of a logical language, it has several forms of negation. Here
|
|
||||||
are a few:
|
|
||||||
|
|
||||||
| English | L'ewa |
|
|
||||||
| --------------------- | ----- |
|
|
||||||
| contradiction | na |
|
|
||||||
| total scalar negation | na'o |
|
|
||||||
| particle negation | nai |
|
|
||||||
|
|
||||||
na can be placed before the sentence's verb too:
|
|
||||||
|
|
||||||
```
|
|
||||||
ti na spalo
|
|
||||||
This is something other than an apple
|
|
||||||
```
|
|
||||||
|
|
||||||
## Verb Forms
|
|
||||||
|
|
||||||
Verbs have one form in L'ewa. Aspects like tense or the perfective aspect are
|
|
||||||
marked with particles. Here's a table of the common ones:
|
|
||||||
|
|
||||||
| English | L'ewa |
|
|
||||||
| ---------- | ----- |
|
|
||||||
| past tense | qu |
|
|
||||||
| present tense | qa |
|
|
||||||
| future tense | qo |
|
|
||||||
| perfective aspect | qe |
|
|
||||||
|
|
||||||
## Modality
|
|
||||||
|
|
||||||
Modality is going to be expressed with emotion words. These words have not been
|
|
||||||
assigned yet, but their grammar will be a lot looser than the normal L'ewa
|
|
||||||
particle grammar. They will allow any two vowels in any combination that might
|
|
||||||
otherwise make them not "legal" for particles.
|
|
||||||
|
|
||||||
- VV (ii)
|
|
||||||
- V'V (i'i)
|
|
||||||
|
|
||||||
## Explicitly Ending Noun Phrases
|
|
||||||
|
|
||||||
In case it is otherwise confusing, ko can be used to end noun phrases grammatically.
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
I will probably be fleshing this out some more, but for now this is how all of
|
|
||||||
this works.
|
|
||||||
|
|
@ -1,137 +0,0 @@
|
||||||
---
|
|
||||||
title: "ReConLangMo 5: Sentence Structure"
|
|
||||||
date: 2020-05-18
|
|
||||||
series: reconlangmo
|
|
||||||
tags:
|
|
||||||
- conlang
|
|
||||||
- lewa
|
|
||||||
---
|
|
||||||
|
|
||||||
# ReConLangMo 5: Sentence Structure
|
|
||||||
|
|
||||||
The last post in [this series][reconlangmo] was more of a grammar dump with few
|
|
||||||
concrete examples or much details about things (mostly because of a lack of
|
|
||||||
vocabulary to make examples with). I'll fix this in the future, but for now
|
|
||||||
let's continue on with sentence structure goodness. This is a response to [this
|
|
||||||
prompt][rclm5].
|
|
||||||
|
|
||||||
[reconlangmo]: /blog/series/reconlangmo
|
|
||||||
[rclm5]: https://www.reddit.com/r/conlangs/comments/gmbwb5/reconlangmo_5_sentence_structure/
|
|
||||||
|
|
||||||
## Independent Clause Structure
|
|
||||||
|
|
||||||
Most of the time L'ewa sentences have only one clause. This can be anything from
|
|
||||||
a single verb to a subject, verb and object. However, sometimes more information
|
|
||||||
is needed. Consider this sentence:
|
|
||||||
|
|
||||||
```
|
|
||||||
The dog which is blue is large.
|
|
||||||
```
|
|
||||||
|
|
||||||
This kind of a relative clause would be denoted using `hoi`, which would make
|
|
||||||
the sentence roughly the following in L'ewa:
|
|
||||||
|
|
||||||
```
|
|
||||||
le wufra hoi blanu xi brado.
|
|
||||||
```
|
|
||||||
|
|
||||||
The particle `xi` is needed here in order to make it explicit that the subject
|
|
||||||
noun-phrase has ended.
|
|
||||||
|
|
||||||
Similarly, an incidental relative clause is done with with `joi`:
|
|
||||||
|
|
||||||
```
|
|
||||||
le wufra joi blanu ke brado
|
|
||||||
the dog, which by the way is blue, is big.
|
|
||||||
```
|
|
||||||
|
|
||||||
## Questions
|
|
||||||
|
|
||||||
There are a few ways to ask questions in L'ewa. They correlate to the different
|
|
||||||
kinds of things that the speaker could want to know.
|
|
||||||
|
|
||||||
### `ma`
|
|
||||||
|
|
||||||
`ma` is the particle used to fill in a missing/unknown noun phrase. Consider
|
|
||||||
these sentences:
|
|
||||||
|
|
||||||
```
|
|
||||||
ma blanu?
|
|
||||||
what is blue?
|
|
||||||
```
|
|
||||||
|
|
||||||
```
|
|
||||||
ro qa madsa ma?
|
|
||||||
you are eating what?
|
|
||||||
```
|
|
||||||
|
|
||||||
### `no`
|
|
||||||
|
|
||||||
`no` is the particle used to fill in a missing/unknown verb. Consider these
|
|
||||||
sentences:
|
|
||||||
|
|
||||||
```
|
|
||||||
ro no?
|
|
||||||
How are you doing?
|
|
||||||
```
|
|
||||||
|
|
||||||
```
|
|
||||||
le wufra xi no?
|
|
||||||
The dog did what?
|
|
||||||
```
|
|
||||||
|
|
||||||
### `so`
|
|
||||||
|
|
||||||
`so` is the particle used to ask questions about numbers, similar to the "how
|
|
||||||
many" construct in English.
|
|
||||||
|
|
||||||
```
|
|
||||||
ro madsa so spalo?
|
|
||||||
You ate how many apples?
|
|
||||||
```
|
|
||||||
|
|
||||||
```
|
|
||||||
le so zasko xi qa'te glowa
|
|
||||||
How many plants grow quickly?
|
|
||||||
```
|
|
||||||
|
|
||||||
## Color Words
|
|
||||||
|
|
||||||
L'ewa uses a RGB color system like computers. The basic colors are red, green
|
|
||||||
and blue, with some other basic ones for convenience:
|
|
||||||
|
|
||||||
| English | L'ewa |
|
|
||||||
| ------- | ------ |
|
|
||||||
| blue | blanu |
|
|
||||||
| red | delja |
|
|
||||||
| green | qalno |
|
|
||||||
| yellow | yeplo |
|
|
||||||
| teal | te'ra |
|
|
||||||
| pink | hetlo |
|
|
||||||
| black | xekri |
|
|
||||||
| white | pu'ro |
|
|
||||||
| 50% gray | flego |
|
|
||||||
|
|
||||||
Colors will be mixed by creating compound words between base colors. Compound
|
|
||||||
words still need to be fleshed out, but generally all CVCCV words will have
|
|
||||||
wordparts made out of the first, second and fifth letter, unless the vowel pair
|
|
||||||
is illegal and all CCVCV words are the first, second and fifth letter unless
|
|
||||||
this otherwise violates the morphology rules. Like I said though, this really
|
|
||||||
needs to be fleshed out and this is only a preview for now.
|
|
||||||
|
|
||||||
For example a light green would be `puoqa'o` (`pu'lo qalno`, white-green).
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
I hit a snag while hacking at the tooling for making word creation and the like
|
|
||||||
easier. I am still working on it, but most of my word creation is manual and
|
|
||||||
requires me to keep a phonology information document up on my monitor while I
|
|
||||||
sound things out. As part of writing this article I had to add the letters `f`
|
|
||||||
and `r` to L'ewa for the word `wufra`.
|
|
||||||
|
|
||||||
I am documenting my work for this language [here](https://tulpa.dev/cadey/lewa).
|
|
||||||
This repo will build the grammar book PDF, website and eBook. This will also be
|
|
||||||
the home of the word generation, similarity calculation, dictionary and
|
|
||||||
(eventually) automatic translation tools. I am also documenting each of the
|
|
||||||
words in the language in their own files that will feed into the grammar book
|
|
||||||
generation. More on this when I have more of a coherent product!
|
|
||||||
|
|
@ -1,183 +0,0 @@
|
||||||
---
|
|
||||||
title: "ReConLangMo 6: Lexicon"
|
|
||||||
date: 2020-05-22
|
|
||||||
series: reconlangmo
|
|
||||||
tags:
|
|
||||||
- conlang
|
|
||||||
- lewa
|
|
||||||
---
|
|
||||||
|
|
||||||
# ReConLangMo 6: Lexicon
|
|
||||||
|
|
||||||
Previously in [this series][reconlangmo], we've covered a lot of details about
|
|
||||||
how sentences work, tenses get marked and how words work in general; however
|
|
||||||
this doesn't really make L'ewa a _language_. Most of the difficulty in making a
|
|
||||||
language like this is the vocabulary. In this post I'll be describing how I am
|
|
||||||
making the vocabulary for L'ewa and I'll include an entire table of the
|
|
||||||
dictionary words. This answers [this
|
|
||||||
prompt](https://www.reddit.com/r/conlangs/comments/gojncp/reconlangmo_6_lexicon/).
|
|
||||||
|
|
||||||
[reconlangmo]: https://christine.website/blog/series/reconlangmo
|
|
||||||
|
|
||||||
## Word Distinctions
|
|
||||||
|
|
||||||
L'ewa is intended to be a logical language. One of the side effects of L'ewa
|
|
||||||
being a logical language is that each word should have as minimal and exact of a
|
|
||||||
meaning/function as possible. English has lots of words that cover large
|
|
||||||
semantic spaces (like go, set, run, take, get, turn, good, etc.) without much of a
|
|
||||||
pattern to it. I don't want this in L'ewa.
|
|
||||||
|
|
||||||
Let's take the word "good" as an example. Off the top of my head, good can mean
|
|
||||||
any of the following things:
|
|
||||||
|
|
||||||
- beneficial
|
|
||||||
- aesthetically pleasing
|
|
||||||
- favorful taste
|
|
||||||
- saintly (coincidentally this is the source of the idiom "God is good")
|
|
||||||
- healthy
|
|
||||||
|
|
||||||
I'm fairly sure there are more "senses" of the word good, but let's break these
|
|
||||||
into their own words:
|
|
||||||
|
|
||||||
| L'ewa | Definition |
|
|
||||||
|-------|------------------------------------|
|
|
||||||
| firgu | is beneficial/nice to |
|
|
||||||
| n'ixu | is aesthetically pleasing to |
|
|
||||||
| flawo | is tasty/has a pleasant flavor to |
|
|
||||||
| spiro | is saintly/holy/morally good to |
|
|
||||||
| qanro | is healthy/fit/well/in good health |
|
|
||||||
|
|
||||||
Each of these words has a very distinct and fine-grained meaning, even though
|
|
||||||
the range is a bit larger than it would be in English. These words also differ
|
|
||||||
from a lot of the other words in the L'ewa dictionary so far because they can
|
|
||||||
take an object. Most of the words so far are adjective-like because it doesn't
|
|
||||||
make sense for there to be an object attached to the color blue.
|
|
||||||
|
|
||||||
By default, if a word that can take an object doesn't have one, it's assumed to
|
|
||||||
be obvious from context. For example, consider the following set of sentences:
|
|
||||||
|
|
||||||
```
|
|
||||||
mi qa madsa lo spalo. ti flawo!
|
|
||||||
|
|
||||||
I am eating an apple. It's delicious!
|
|
||||||
```
|
|
||||||
|
|
||||||
I am working at creating more words using a [Swaedish list][swaedish207].
|
|
||||||
|
|
||||||
[swaedish207]: https://tulpa.dev/cadey/lewa/src/branch/master/words/swaedish207.csv
|
|
||||||
|
|
||||||
## Family Words
|
|
||||||
|
|
||||||
Family words are a huge part of a language because it encodes a lot about the
|
|
||||||
culture behind that language. L'ewa isn't really intended to have much of a
|
|
||||||
culture behind it, but the one place I want to take a cultural stance is here.
|
|
||||||
The major kinship word is kirta, or "is an infinite slice of an even greater
|
|
||||||
infinite". This is one of the few literal words in L'ewa that is defined using a
|
|
||||||
metaphor, as there is really no good analog for this in English.
|
|
||||||
|
|
||||||
There are also words for other major family terms in English:
|
|
||||||
|
|
||||||
| L'ewa | Definition |
|
|
||||||
|-------|-------------------------|
|
|
||||||
| brota | is the/a brother of |
|
|
||||||
| sistu | is the/a sister of |
|
|
||||||
| mamta | is the/a mother of |
|
|
||||||
| patfu | is the/a father of |
|
|
||||||
| grafa | is the/a grandfather of |
|
|
||||||
| grama | is the/a grandmother of |
|
|
||||||
| wanto | is the/a aunt of |
|
|
||||||
| tunke | is the/a uncle of |
|
|
||||||
|
|
||||||
Cousins are all called brother/sister. None of these words are inherently
|
|
||||||
gendered and `brota` can refer to a female or nonbinary person. The words are
|
|
||||||
separate because I feel it flows better, for now at least.
|
|
||||||
|
|
||||||
## Idioms
|
|
||||||
|
|
||||||
L'ewa strives to have as few idioms as possible. If something is meant
|
|
||||||
non-literally (or as a [conceptual metaphor][cmet]), the particle ke'a can be used:
|
|
||||||
|
|
||||||
[cmet]: https://en.wikipedia.org/wiki/Conceptual_metaphor
|
|
||||||
|
|
||||||
```
|
|
||||||
ti firgu
|
|
||||||
This is beneificial
|
|
||||||
|
|
||||||
ti ke'a firgu
|
|
||||||
This is metaphorically/non-literally beneficial
|
|
||||||
```
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
I have been documenting L'ewa and all of its words/grammar in a [git
|
|
||||||
repo][lewarepo]. The layout of this repo is as follows:
|
|
||||||
|
|
||||||
| Folder | Purpose |
|
|
||||||
|----------|------------------------------------------------------------------------------------------------------------------------|
|
|
||||||
| `book` | The source files and build scripts for the L'ewa book (this book may end up being published) |
|
|
||||||
| `nix` | [Nix][nix] crud, custom packages for the eBook render and development tools |
|
|
||||||
| `script` | Where experiments for the written form of L'ewa live |
|
|
||||||
| `tools` | Tools for hacking at L'ewa in Rust/Typescript (none published yet, this is where the dictionary server code will live) |
|
|
||||||
| `words` | Where the definitions of each word are defined in [Dhall][dhall], this will be fed into the dictionary server code |
|
|
||||||
|
|
||||||
I also have the entire process of building and testing everything (from the
|
|
||||||
eBook to the unit tests of the tools) automated with [Drone][droneci]. You can
|
|
||||||
see the past builds [here](https://drone.tulpa.dev/cadey/lewa). After I merge
|
|
||||||
the information from the latest blogpost into this repo, I will put a rendered
|
|
||||||
version of it [here](http://lewa-book-devel.kahless.cetacean.club:43001/). This
|
|
||||||
will allow you to browse through the chapters of the eBook while it is being
|
|
||||||
written. Eventually this will be automatically deployed to my Kubernetes cluster
|
|
||||||
and the book will be a subpath/subdomain of `lewa.christine.website`.
|
|
||||||
|
|
||||||
I have created a system of defining words that allows you to focus on each word
|
|
||||||
at once, but then fit it back into the greater whole of the language. For
|
|
||||||
example here is `kirta.dhall`:
|
|
||||||
|
|
||||||
```dhall
|
|
||||||
-- kirta.dhall
|
|
||||||
let ContentWord = ../types/ContentWord.dhall
|
|
||||||
|
|
||||||
in ContentWord::{
|
|
||||||
, word = "kirta"
|
|
||||||
, gloss = "Creator"
|
|
||||||
, definition =
|
|
||||||
"is an infinite slice of an even greater infinite/our Creator/a Creator"
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
This is put in `words/roots` because it is a root (or uncombined) word. Then it
|
|
||||||
is added to the `dictionary.dhall`:
|
|
||||||
|
|
||||||
```dhall
|
|
||||||
-- dictionary.dhall
|
|
||||||
let ContentWord = ./types/ContentWord.dhall
|
|
||||||
|
|
||||||
let ParticleWord = ./types/ParticleWord.dhall
|
|
||||||
|
|
||||||
in { rootWords =
|
|
||||||
[ -- ...
|
|
||||||
./roots/kirta.dhall
|
|
||||||
-- ...
|
|
||||||
]
|
|
||||||
, particles [ -- ...
|
|
||||||
]
|
|
||||||
```
|
|
||||||
|
|
||||||
And then the build process will automatically generate the new dictionary from
|
|
||||||
all of these definitions. Downside of this is that each new kind of word needs
|
|
||||||
subtle adjustments to the build process of the dictionary and that
|
|
||||||
removals/changes to lots of words requires a larger-scale refactor of the
|
|
||||||
language, but I feel the tradeoff is worth the effort. I will undoubtedly end up
|
|
||||||
creating a few tools to help with this.
|
|
||||||
|
|
||||||
I will keep working on additional vocabulary on my own, but [here][vocab] is the
|
|
||||||
list of vocabulary that has been written up so far.
|
|
||||||
|
|
||||||
[vocab]: https://git.io/JfaeF
|
|
||||||
|
|
||||||
Be well.
|
|
||||||
|
|
||||||
[lewarepo]: https://tulpa.dev/cadey/lewa
|
|
||||||
[nix]: https://nixos.org/nix/
|
|
||||||
[dhall]: https://dhall-lang.org/
|
|
||||||
[droneci]: https://drone.io
|
|
||||||
|
|
@ -1,285 +0,0 @@
|
||||||
---
|
|
||||||
title: "ReConLangMo 7: Discourse"
|
|
||||||
date: 2020-05-25
|
|
||||||
series: reconlangmo
|
|
||||||
tags:
|
|
||||||
- conlang
|
|
||||||
- lewa
|
|
||||||
---
|
|
||||||
|
|
||||||
# ReConLangMo 7: Discourse
|
|
||||||
|
|
||||||
Previously on [ReConLangMo][reconlangmo], we covered a lot of new words for the
|
|
||||||
lexicon of L'ewa. This helps to flesh out a lot of what can be said, but
|
|
||||||
conversations themselves can be entirely different from formal sentences.
|
|
||||||
Conversations flow and ebb based on the needs/wants of the interlocutors. This
|
|
||||||
post will start to cover a lot of the softer skills behind L'ewa as well as
|
|
||||||
cover some other changes I'm making under the hood. This is a response to [this
|
|
||||||
prompt][rclm7].
|
|
||||||
|
|
||||||
[reconlangmo]: https://christine.website/blog/series/reconlangmo
|
|
||||||
[rclm7]: https://www.reddit.com/r/conlangs/comments/gqo8jn/reconlangmo_7_discourse/
|
|
||||||
|
|
||||||
## Information Structure
|
|
||||||
|
|
||||||
L'ewa doesn't have any particular structure for marking previously known
|
|
||||||
information, as normal sentences should suffice in most cases. Consider this
|
|
||||||
paragraph:
|
|
||||||
|
|
||||||
```
|
|
||||||
I saw you eat an apple. Was it tasty?
|
|
||||||
```
|
|
||||||
|
|
||||||
Since `an apple` was the last thing mentioned in the paragraph, the vague "it"
|
|
||||||
pronoun in the second sentence can be interpreted as "the apple".
|
|
||||||
|
|
||||||
L'ewa doesn't have a way to mark the topic of a sentence, that should be obvious
|
|
||||||
from context (additional clauses to describe things will help here). In most
|
|
||||||
cases the subject should be equivalent to the topic of a sentence.
|
|
||||||
|
|
||||||
L'ewa doesn't directly offer ways to emphasize parts of sentences with phonemic
|
|
||||||
stress like English does (eg: "I THOUGHT you ate an apple" vs "I thought you ATE
|
|
||||||
an apple"), but emotion words can be used to help indicate feelings about
|
|
||||||
things, which should suffice as far as emphasis goes.
|
|
||||||
|
|
||||||
## Discourse Structure
|
|
||||||
|
|
||||||
Conversationally, a lot of things in L'ewa grammar get dropped unless it's
|
|
||||||
ambiguous. The I/yous that get tacked on in English are completely unneeded. A
|
|
||||||
completely valid conversation could look something like this:
|
|
||||||
|
|
||||||
```
|
|
||||||
<Mai> xoi
|
|
||||||
<Cadey> xoi
|
|
||||||
<Mai> xoi madsa?
|
|
||||||
<Cadey> lo spalo
|
|
||||||
```
|
|
||||||
|
|
||||||
And it would roughly equate to:
|
|
||||||
|
|
||||||
```
|
|
||||||
<Mai> Hi
|
|
||||||
<Cadey> Hi, you doing okay?
|
|
||||||
<Mai> Yes, have you eaten?
|
|
||||||
<Cadey> Yes, I ate an apple
|
|
||||||
```
|
|
||||||
|
|
||||||
People know when they can speak after a sufficient pause between utterances.
|
|
||||||
Interrupting is not common but not a social faux-pas, and can be used to stop a
|
|
||||||
false assumption from being said.
|
|
||||||
|
|
||||||
## Utterances
|
|
||||||
|
|
||||||
An utterance in L'ewa is anything from a single content word all the way up to
|
|
||||||
an entire paragraph of sentences. An emotion particle can be a complete
|
|
||||||
utterance. A question particle can be a complete utterance, anything can be an
|
|
||||||
utterance. A speaker may want to choose more succinct options when the other
|
|
||||||
detail is already contextually known or simply not relevant to the listener.
|
|
||||||
|
|
||||||
L'ewa has a few discourse particles, here are a few of the more significant
|
|
||||||
ones:
|
|
||||||
|
|
||||||
| L'ewa | Function |
|
|
||||||
|-------|------------------------------------------------------|
|
|
||||||
| xi | signals that the verb of the sentence is coming next |
|
|
||||||
| ko | ends a noun phrase |
|
|
||||||
| ka | marks something as the subject of the sentence |
|
|
||||||
| ke | marks something as the verb of the sentence |
|
|
||||||
| ku | marks something as the object of the sentence |
|
|
||||||
|
|
||||||
## Formality
|
|
||||||
|
|
||||||
The informal dialect of L'ewa drops everything it can. The formal dialect
|
|
||||||
retains everything it can, to the point where it includes noun phrase endings,
|
|
||||||
the verb signaler, ka/ke/ku and every single optional particle in the language.
|
|
||||||
The formal dialect will end up sounding rather wordy compared to informal slangy
|
|
||||||
speech. Consider the differences between informal and formal versions of "I eat
|
|
||||||
an apple":
|
|
||||||
|
|
||||||
```
|
|
||||||
mi madsa lo spalo.
|
|
||||||
```
|
|
||||||
|
|
||||||
```
|
|
||||||
ka mi ko xi ke madsa ku lo spalo ko.
|
|
||||||
```
|
|
||||||
|
|
||||||
Nearly all of those particles are not required in informal speech (you could
|
|
||||||
even get away with `madsa lo spalo` depending on context), but are required in
|
|
||||||
formal speech to ensure there is as little contextual confusion as possible.
|
|
||||||
Things like laws or legal rulings would be written out in the formal register.
|
|
||||||
|
|
||||||
## Greetings and Farewell
|
|
||||||
|
|
||||||
"Hello" in L'ewa is said using `xoi`. It can also be used as a reply to hello
|
|
||||||
similar to «ça va» in French. It is possible to have an entire conversation with
|
|
||||||
just `xoi`:
|
|
||||||
|
|
||||||
```
|
|
||||||
<Mai> xoi
|
|
||||||
<Cadey> xoi
|
|
||||||
<Mai> xoi
|
|
||||||
```
|
|
||||||
|
|
||||||
The other implications of `xoi` are "how are you?" "I am good, you?", "I am
|
|
||||||
good", etc. If more detail is needed beyond this, then it can be supplied
|
|
||||||
instead of replying with `xoi`.
|
|
||||||
|
|
||||||
"Goodbye" is said using `xei`. Like `xoi` it can be used as a reply to another
|
|
||||||
goodbye and can form a mini-conversation:
|
|
||||||
|
|
||||||
```
|
|
||||||
<Cadey> xei
|
|
||||||
<Mai> xei
|
|
||||||
<Cadey> xei
|
|
||||||
```
|
|
||||||
|
|
||||||
## Emotion Words
|
|
||||||
|
|
||||||
Feelings in L'ewa are marked with a family of particles called "UI". These can
|
|
||||||
also be modified with other particles. Here are the emotional markers:
|
|
||||||
|
|
||||||
| L'ewa | English |
|
|
||||||
|-------|----------------|
|
|
||||||
| `a'a` | attentive |
|
|
||||||
| `a'e` | alertness |
|
|
||||||
| `ai` | intent |
|
|
||||||
| `a'i` | effort |
|
|
||||||
| `a'o` | hope |
|
|
||||||
| `au` | desire |
|
|
||||||
| `a'u` | interest |
|
|
||||||
| `e'a` | permission |
|
|
||||||
| `e'e` | competence |
|
|
||||||
| `ei` | obligation |
|
|
||||||
| `e'i` | constraint |
|
|
||||||
| `e'o` | request |
|
|
||||||
| `e'u` | suggestion |
|
|
||||||
| `ia` | belief |
|
|
||||||
| `i'a` | acceptance |
|
|
||||||
| `ie` | agreement |
|
|
||||||
| `i'e` | approval |
|
|
||||||
| `ii` | fear |
|
|
||||||
| `i'i` | togetherness |
|
|
||||||
| `io` | respect |
|
|
||||||
| `i'o` | appreciation |
|
|
||||||
| `iu` | love |
|
|
||||||
| `i'u` | familiarity |
|
|
||||||
| `o'a` | pride |
|
|
||||||
| `o'e` | closeness |
|
|
||||||
| `oi` | complaint/pain |
|
|
||||||
| `o'i` | caution |
|
|
||||||
| `o'o` | patience |
|
|
||||||
| `o'u` | relaxation |
|
|
||||||
| `ua` | discovery |
|
|
||||||
| `u'a` | gain |
|
|
||||||
| `ue` | surprise |
|
|
||||||
| `u'e` | wonder |
|
|
||||||
| `ui` | happiness |
|
|
||||||
| `u'i` | amusement |
|
|
||||||
| `uo` | completion |
|
|
||||||
| `u'o` | courage |
|
|
||||||
| `uu` | pity |
|
|
||||||
| `u'u` | repentant |
|
|
||||||
|
|
||||||
If an emotion is unknown in a conversation, you can ask with `kei`:
|
|
||||||
|
|
||||||
```
|
|
||||||
<Mai> xoi, so kei?
|
|
||||||
hi, what-verb what-feeling?
|
|
||||||
|
|
||||||
<Cadey> madsa ui
|
|
||||||
eating :D
|
|
||||||
```
|
|
||||||
|
|
||||||
This system is wholesale stolen from [Lojban](https://lojban.github.io/cll/13/1/).
|
|
||||||
|
|
||||||
## Connectives
|
|
||||||
|
|
||||||
Connectives exist to link noun phrases and verbs together into larger
|
|
||||||
noun phrases and verbs. They can also be used to link together sentences. There
|
|
||||||
are four simple connectives: `fa` (OR), `fe` (AND), `fi` (connective question),
|
|
||||||
`fo` (if-and-only-if) and `fu` (whether-or-not).
|
|
||||||
|
|
||||||
### OR
|
|
||||||
|
|
||||||
```
|
|
||||||
ro au madsa lo spalo fa lo hafto?
|
|
||||||
Do you want to eat an apple or an egg?
|
|
||||||
```
|
|
||||||
|
|
||||||
### AND
|
|
||||||
|
|
||||||
```
|
|
||||||
ro au madsa lo spalo fe lo hafto?
|
|
||||||
Do you want to eat an apple and an egg?
|
|
||||||
```
|
|
||||||
|
|
||||||
### If and Only If
|
|
||||||
|
|
||||||
```
|
|
||||||
ro 'amwo mi fo mi madsa hafto?
|
|
||||||
Do you love me if I eat eggs?
|
|
||||||
```
|
|
||||||
|
|
||||||
### Whether or Not
|
|
||||||
|
|
||||||
```
|
|
||||||
mi 'amwo ro. fu ro madsa hafto.
|
|
||||||
I love you, whether or not you eat eggs.
|
|
||||||
```
|
|
||||||
|
|
||||||
### Connective Question
|
|
||||||
|
|
||||||
```
|
|
||||||
ro au madsa lo spalo fi lo hafto?
|
|
||||||
Do you want to eat apples and/or eggs?
|
|
||||||
```
|
|
||||||
|
|
||||||
## Changes Being Made to L'ewa
|
|
||||||
|
|
||||||
Early on, I mentioned that family terms were gendered. This also ended up with
|
|
||||||
me making some gendered terms for people. I have since refactored out all of the
|
|
||||||
gendered terms in favor of more universal terms. Here is a table of some of the
|
|
||||||
terms that have been replaced:
|
|
||||||
|
|
||||||
| English | L'ewa term | L'ewa word |
|
|
||||||
|-------------------------|-------------|------------|
|
|
||||||
| brother/sister | sibling | xinga |
|
|
||||||
| mother/father | parent | pa'ma |
|
|
||||||
| grandfather/grandmother | grandparent | gra'u |
|
|
||||||
| aunt/uncle | parent | pa'ma |
|
|
||||||
| cousin | sibling | xinga |
|
|
||||||
| man/woman | Creator | kirta |
|
|
||||||
| man/woman | human | renma |
|
|
||||||
|
|
||||||
In some senses, gender exists. In other senses, gender does not. With L'ewa I
|
|
||||||
want to explore what is possible with language. It would be interesting to
|
|
||||||
create a language where gender can be discussed as it is, not as the categories
|
|
||||||
that it has historically fit into. Consider colors. There are millions of
|
|
||||||
colors, all sightly different but many follow general patterns. No one or two
|
|
||||||
colors can be thought of as the "default" color, yet we can have long and
|
|
||||||
meaningful conversations about what color is and what separates colors from
|
|
||||||
eachother.
|
|
||||||
|
|
||||||
I aim to have the same kind of granularity in L'ewa. As a goal of the language,
|
|
||||||
I should be able to point to any content word in the dictionary and be able to
|
|
||||||
say "that's my gender" in the same way I can describe color or music with that
|
|
||||||
tree. These will implicitly be metaphors (which does detract a bit from the
|
|
||||||
logical stance L'ewa normally takes) because gender is almost always a metaphor
|
|
||||||
in practice. L'ewa will not have binary gender.
|
|
||||||
|
|
||||||
Issue [number two](https://tulpa.dev/cadey/lewa/issues/2) on the L'ewa repo will
|
|
||||||
help track the creation and implementation of a truly non-binary "gender" system
|
|
||||||
for L'ewa.
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
I've been chugging through the Swaedish list more and more to build up more of
|
|
||||||
L'ewa's vocabulary in preparation for starting to translate sentences more
|
|
||||||
complicated than simple "I eat an apple" or "Do you like eating plants?". One of
|
|
||||||
the first things I want to translate is the classic [tower of babel
|
|
||||||
story][babel].
|
|
||||||
|
|
||||||
[babel]: https://en.wikipedia.org/wiki/Tower_of_Babel
|
|
||||||
|
|
||||||
Be well.
|
|
||||||
|
|
@ -1,142 +0,0 @@
|
||||||
---
|
|
||||||
title: "ReConLangMo 8: Storytelling"
|
|
||||||
date: 2020-05-29
|
|
||||||
series: reconlangmo
|
|
||||||
tags:
|
|
||||||
- conlang
|
|
||||||
- lewa
|
|
||||||
---
|
|
||||||
|
|
||||||
# ReConLangMo 8: Storytelling
|
|
||||||
|
|
||||||
In the [last episode][rclm7] of [ReConLangMo][reconlangmo], we covered
|
|
||||||
conversational discourse as well as formality and other grammatical moods. I
|
|
||||||
also covered my goals for the gender system of L'ewa. Here I will cover the
|
|
||||||
closest thing L'ewa has to culture, the storytelling and poetry norms. L'ewa is
|
|
||||||
also a language designed for [spellcraft][spellcraft] and [sigil
|
|
||||||
magick][sigils], so those norms will be covered too. This is a response to [this
|
|
||||||
prompt][rclm8].
|
|
||||||
|
|
||||||
[rclm7]: /blog/reconlangmo-7-discourse-2020-05-25
|
|
||||||
[rclm8]: https://www.reddit.com/r/conlangs/comments/gszhy9/reconlangmo_7_storytelling_and_poetry/
|
|
||||||
[reconlangmo]: /blog/series/reconlangmo
|
|
||||||
[spellcraft]: https://en.wikipedia.org/wiki/Incantation
|
|
||||||
[sigils]: https://en.wikipedia.org/wiki/Sigil
|
|
||||||
|
|
||||||
## Stories
|
|
||||||
|
|
||||||
Stories are told as statements that happened in the past. Stories are structured
|
|
||||||
in the same way that you would structure them in English. There is a scenario, a
|
|
||||||
call to action, a refusal of the call, then the story goes on in the standard
|
|
||||||
way. Casual retelling of events is done without a narrative, and the events are
|
|
||||||
just relayed using casual sentences.
|
|
||||||
|
|
||||||
The particle `qu` can be repeated at the beginning of a story to enable the
|
|
||||||
"story time" flag. Story time sentences can be figurative. Each sentence in the
|
|
||||||
story progressively builds up the narrative to explain the themes and lessons
|
|
||||||
that are trying to be conveyed.
|
|
||||||
|
|
||||||
Stories are told using the narrative present tense. Speakers also relay
|
|
||||||
secondhand information directly.
|
|
||||||
|
|
||||||
## Poetry
|
|
||||||
|
|
||||||
One of the morphological side effect of L'ewa root words is that only the first
|
|
||||||
four letters of each word are unique. As a side effect of this, you can make any
|
|
||||||
word rhyme with any other word if you want it to. L'ewa can become l'ewi, l'ewo,
|
|
||||||
le'we or l'ewu if the poetry demands it. Poetry can be done in any meter or
|
|
||||||
rhythm depending on the mood of the speaker. Poetry can also be formatted using
|
|
||||||
fixed-width text. Here are a few examples:
|
|
||||||
|
|
||||||
```
|
|
||||||
le l'ewa de kirta
|
|
||||||
xi firga to renma
|
|
||||||
|
|
||||||
The language of Creators
|
|
||||||
is beneficial to all people
|
|
||||||
```
|
|
||||||
|
|
||||||
```
|
|
||||||
a'o ro zimpu ti
|
|
||||||
e'o so vorto
|
|
||||||
|
|
||||||
I hope you understand this
|
|
||||||
How many words?
|
|
||||||
```
|
|
||||||
|
|
||||||
I don't think I have enough vocabulary to make any more yet.
|
|
||||||
|
|
||||||
## Spellcraft
|
|
||||||
|
|
||||||
These poems are worked into sigils by interlocking the words together into a
|
|
||||||
larger figure. Here is an example based on the first poem:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Ideally this would would include the letters spiraling around things, but my
|
|
||||||
current tools are limited in what they can do. Sigils don't need to follow
|
|
||||||
normal grammar rules. They can bend and break them as much as they want or need
|
|
||||||
in order to flow nicer. If they need to, they can also make up words that don't
|
|
||||||
normally exist in the dictionary. These words should be documented in the
|
|
||||||
dictionary at some point, but there is no big rush.
|
|
||||||
|
|
||||||
## Gender and Third Person Pronouns
|
|
||||||
|
|
||||||
Previously, I haven't gone into details about the third person pronouns in
|
|
||||||
L'ewa. This was done very, very intentionally. One of the goals of L'ewa's
|
|
||||||
handling of gender is to abolish the gender binary as much as possible. This
|
|
||||||
means that any content word can end up being used as a pronoun. In order to
|
|
||||||
avoid ambiguity, only part of the content word is used to form something
|
|
||||||
matching the particle rules I was vaguely gesturing about in the post that had
|
|
||||||
details about colors. To recap:
|
|
||||||
|
|
||||||
> Compound words still need to be fleshed out, but generally all CVCCV words
|
|
||||||
> will have wordparts made out of the first, second and fifth letter, unless the
|
|
||||||
> vowel pair is illegal and all CCVCV words are the first, third and fifth
|
|
||||||
> letter unless this otherwise violates the morphology rules.
|
|
||||||
|
|
||||||
Let's say that your gender is the word for "is meat", or `dextu`. This would
|
|
||||||
mean the third person pronoun form would be `de'u` (`eu` isn't a valid vowel
|
|
||||||
pair so the glottal stop is used to break it).
|
|
||||||
|
|
||||||
```
|
|
||||||
de'u qu tulpa lo l'ewa
|
|
||||||
They (de'u) built a language.
|
|
||||||
|
|
||||||
mao qu madsa lo spalo
|
|
||||||
They (mao) ate an apple.
|
|
||||||
```
|
|
||||||
|
|
||||||
If you want to declare your gender, you can declare it with the word `zedra`:
|
|
||||||
|
|
||||||
```
|
|
||||||
lo spalo xi zedra
|
|
||||||
An apple is (my) gender.
|
|
||||||
```
|
|
||||||
|
|
||||||
This would then make their pronoun `sao`.
|
|
||||||
|
|
||||||
You can ask someone what their gender is with the gender question particle
|
|
||||||
`zei`:
|
|
||||||
|
|
||||||
```
|
|
||||||
<Mai> xoi
|
|
||||||
<Cadey> xoi ro zei
|
|
||||||
<Mai> lo mlato xi zedra
|
|
||||||
<Mai> zei
|
|
||||||
<Cadey> lo 'orka xi zedra
|
|
||||||
```
|
|
||||||
|
|
||||||
From then Mai would be referred to using the pronoun `mao` and Cadey would be
|
|
||||||
referred to using the pronoun `'ka`.
|
|
||||||
|
|
||||||
If you need a generic third person pronoun, use `ke'o`.
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
This seems to be the end of the ReConLangMo series in /r/conlangs, but I will
|
|
||||||
definitely continue to develop this on my own and post about it as I make larger
|
|
||||||
accomplishments. This has been a fun series and I hope it gave people a high
|
|
||||||
level overview of what is needed to make a speakable language from nothing.
|
|
||||||
|
|
||||||
Be well.
|
|
||||||
|
|
@ -1,616 +0,0 @@
|
||||||
---
|
|
||||||
title: Rust Crates that do What the Go Standard library Does
|
|
||||||
date: 2020-09-27
|
|
||||||
series: rust
|
|
||||||
---
|
|
||||||
|
|
||||||
# Rust Crates that do What the Go Standard library Does
|
|
||||||
|
|
||||||
One of Go's greatest strengths is how batteries-included the standard library
|
|
||||||
is. You can do most of what you need to do with only the standard library. On
|
|
||||||
the other hand, Rust's standard library is severely lacking by comparison.
|
|
||||||
However, the community has capitalized on this and been working on a bunch of
|
|
||||||
batteries that you can include in your rust projects. I'm going to cover a bunch
|
|
||||||
of them in this post in a few sections.
|
|
||||||
|
|
||||||
[A lot of these are actually used to help make this blog site
|
|
||||||
work!](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
## Logging
|
|
||||||
|
|
||||||
Go has logging out of the box with package [`log`](https://godoc.org/log).
|
|
||||||
Package `log` is a very uncontroversial logger. It does what it says it does and
|
|
||||||
with little fuss. However it does not include a lot of niceties like logging
|
|
||||||
levels and context-aware values.
|
|
||||||
|
|
||||||
In Rust, we have the [`log`](https://docs.rs/log/) crate which is a very simple
|
|
||||||
interface. It uses the `error!`, `warn!`, `info!`, `debug!` and `trace!` macros
|
|
||||||
which correlate to the highest and lowest levels. If you want to use `log` in a
|
|
||||||
Rust crate, you can add it to your `Cargo.toml` file like this:
|
|
||||||
|
|
||||||
```toml
|
|
||||||
[dependencies]
|
|
||||||
log = "0.4"
|
|
||||||
```
|
|
||||||
|
|
||||||
Then you can use it in your Rust code like this:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
use log::{error, warn, info, debug, trace};
|
|
||||||
|
|
||||||
fn main() {
|
|
||||||
trace!("starting main");
|
|
||||||
debug!("debug message");
|
|
||||||
info!("this is some information");
|
|
||||||
warn!("oh no something bad is about to happen");
|
|
||||||
error!("oh no it's an error");
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
[Wait, where does that log to? I ran that example locally but I didn't see any
|
|
||||||
of the messages anywhere.](conversation://Mara/wat)
|
|
||||||
|
|
||||||
This is because the `log` crate doesn't directly log anything anywhere, it is a
|
|
||||||
facade that other packages build off of.
|
|
||||||
[`pretty_env_logger`](https://docs.rs/pretty_env_logger) is a commonly used
|
|
||||||
crate with the `log` facade. Let's add it to the program and work from there:
|
|
||||||
|
|
||||||
```toml
|
|
||||||
[dependencies]
|
|
||||||
log = "0.4"
|
|
||||||
pretty_env_logger = "0.4"
|
|
||||||
```
|
|
||||||
|
|
||||||
Then let's enable it in our code:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
use log::{error, warn, info, debug, trace};
|
|
||||||
|
|
||||||
fn main() {
|
|
||||||
pretty_env_logger::init();
|
|
||||||
|
|
||||||
trace!("starting main");
|
|
||||||
debug!("debug message");
|
|
||||||
info!("this is some information");
|
|
||||||
warn!("oh no something bad is about to happen");
|
|
||||||
error!("oh no it's an error");
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
And now let's run it with `RUST_LOG=trace`:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ env RUST_LOG=trace cargo run --example logger_test
|
|
||||||
Finished dev [unoptimized + debuginfo] target(s) in 0.07s
|
|
||||||
Running `/home/cadey/code/christine.website/target/debug/logger_test`
|
|
||||||
TRACE logger_test > starting main
|
|
||||||
DEBUG logger_test > debug message
|
|
||||||
INFO logger_test > this is some information
|
|
||||||
WARN logger_test > oh no something bad is about to happen
|
|
||||||
ERROR logger_test > oh no it's an error
|
|
||||||
```
|
|
||||||
|
|
||||||
There are [many
|
|
||||||
other](https://docs.rs/log/0.4.11/log/#available-logging-implementations)
|
|
||||||
consumers of the log crate and implementing a consumer is easy should you want
|
|
||||||
to do more than `pretty_env_logger` can do on its own. However, I have found
|
|
||||||
that `pretty_env_logger` does just enough on its own. See its documentation for
|
|
||||||
more information.
|
|
||||||
|
|
||||||
## Flags
|
|
||||||
|
|
||||||
Go's standard library has the [`flag`](https://godoc.org/flag) package out of
|
|
||||||
the box. This package is incredibly basic, but is surprisingly capable in terms
|
|
||||||
of what you can actually do with it. A common thing to do is use flags for
|
|
||||||
configuration or other options, such as
|
|
||||||
[here](https://github.com/Xe/hlang/blob/44bb74efa6f124ca05483a527c0e735ce0fca143/main.go#L15-L22):
|
|
||||||
|
|
||||||
```go
|
|
||||||
package main
|
|
||||||
|
|
||||||
import "flag"
|
|
||||||
|
|
||||||
var (
|
|
||||||
program = flag.String("p", "", "h program to compile/run")
|
|
||||||
outFname = flag.String("o", "", "if specified, write the webassembly binary created by -p here")
|
|
||||||
watFname = flag.String("o-wat", "", "if specified, write the uncompiled webassembly created by -p here")
|
|
||||||
port = flag.String("port", "", "HTTP port to listen on")
|
|
||||||
writeTao = flag.Bool("koan", false, "if true, print the h koan and then exit")
|
|
||||||
writeVersion = flag.Bool("v", false, "if true, print the version of h and then exit")
|
|
||||||
)
|
|
||||||
```
|
|
||||||
|
|
||||||
This will make a few package-global variables that will contain the values of
|
|
||||||
the command-line arguments.
|
|
||||||
|
|
||||||
In Rust, a commonly used command line parsing package is
|
|
||||||
[`structopt`](https://docs.rs/structopt). It works in a bit of a different way
|
|
||||||
than Go's `flag` package does though. `structopt` focuses on loading options into
|
|
||||||
a structure rather than into globally mutable variables.
|
|
||||||
|
|
||||||
[Something you may notice in Rust-land is that globally mutable state is talked
|
|
||||||
about as if it is something to be avoided. It's not inherently bad, but it does
|
|
||||||
make things more likely to crash at runtime. In most cases, these global
|
|
||||||
variables with package `flag` are fine, but only if they are ever written to
|
|
||||||
before the program really starts to do what it needs to do. If they are ever
|
|
||||||
written to and read from dynamically at runtime, then you can get into a lot of
|
|
||||||
problems such as <a href="https://en.wikipedia.org/wiki/Race_condition">race
|
|
||||||
conditions</a>.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
Here's a quick example copied from [pa'i](https://github.com/Xe/pahi):
|
|
||||||
|
|
||||||
```rust
|
|
||||||
#[derive(Debug, StructOpt)]
|
|
||||||
#[structopt(
|
|
||||||
name = "pa'i",
|
|
||||||
about = "A WebAssembly runtime in Rust meeting the Olin ABI."
|
|
||||||
)]
|
|
||||||
struct Opt {
|
|
||||||
/// Backend
|
|
||||||
#[structopt(short, long, default_value = "cranelift")]
|
|
||||||
backend: String,
|
|
||||||
|
|
||||||
|
|
||||||
/// Print syscalls on exit
|
|
||||||
#[structopt(short, long)]
|
|
||||||
function_log: bool,
|
|
||||||
|
|
||||||
|
|
||||||
/// Do not cache compiled code?
|
|
||||||
#[structopt(short, long)]
|
|
||||||
no_cache: bool,
|
|
||||||
|
|
||||||
|
|
||||||
/// Binary to run
|
|
||||||
#[structopt()]
|
|
||||||
fname: String,
|
|
||||||
|
|
||||||
|
|
||||||
/// Main function
|
|
||||||
#[structopt(short, long, default_value = "_start")]
|
|
||||||
entrypoint: String,
|
|
||||||
|
|
||||||
|
|
||||||
/// Arguments of the wasm child
|
|
||||||
#[structopt()]
|
|
||||||
args: Vec<String>,
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
This has the Rust compiler generate the needed argument parsing code for you, so
|
|
||||||
you can just use the values as normal:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
fn main() {
|
|
||||||
let opt = Opt::from_args();
|
|
||||||
debug!("args: {:?}", opt.args);
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
You can even handle subcommands with this, such as in
|
|
||||||
[palisade](https://github.com/lightspeed/palisade/blob/master/src/main.rs). This
|
|
||||||
package should handle just about everything you'd do with the `flag` package,
|
|
||||||
but will also work for cases where `flag` falls apart.
|
|
||||||
|
|
||||||
## Errors
|
|
||||||
|
|
||||||
Go's standard library has the [`error`
|
|
||||||
interface](https://godoc.org/builtin#error) which lets you create a type that
|
|
||||||
describes why functions fail to do what they intend. Rust has the [`Error`
|
|
||||||
trait](https://doc.rust-lang.org/std/error/trait.Error.html) which lets you also
|
|
||||||
create a type that describes why functions fail to do what they intend.
|
|
||||||
|
|
||||||
In [my last post](https://christine.website/blog/TLDR-rust-2020-09-19) I
|
|
||||||
described [`eyre`](https://docs.rs/eyre) and the Result type. However, this time
|
|
||||||
we're going to dive into [`thiserror`](https://docs.rs/thiserror) for making our
|
|
||||||
own error type. Let's add `thiserror` to our crate:
|
|
||||||
|
|
||||||
```toml
|
|
||||||
[dependencies]
|
|
||||||
thiserror = "1"
|
|
||||||
```
|
|
||||||
|
|
||||||
And then let's re-implement our `DivideByZero` error from the last post:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
use std::fmt;
|
|
||||||
use thiserror::Error;
|
|
||||||
|
|
||||||
#[derive(Debug, Error)]
|
|
||||||
struct DivideByZero;
|
|
||||||
|
|
||||||
impl fmt::Display for DivideByZero {
|
|
||||||
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
|
|
||||||
write!(f, "cannot divide by zero")
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
The compiler made our error instance for us! It can even do that for more
|
|
||||||
complicated error types like this one that wraps a lot of other error cases and
|
|
||||||
error types in [maj](https://tulpa.dev/cadey/maj):
|
|
||||||
|
|
||||||
```rust
|
|
||||||
#[derive(thiserror::Error, Debug)]
|
|
||||||
pub enum Error {
|
|
||||||
#[error("TLS error: {0:?}")]
|
|
||||||
TLS(#[from] TLSError),
|
|
||||||
|
|
||||||
#[error("URL error: {0:?}")]
|
|
||||||
URL(#[from] url::ParseError),
|
|
||||||
|
|
||||||
#[error("Invalid DNS name: {0:?}")]
|
|
||||||
InvalidDNSName(#[from] webpki::InvalidDNSNameError),
|
|
||||||
|
|
||||||
#[error("IO error: {0:?}")]
|
|
||||||
IO(#[from] std::io::Error),
|
|
||||||
|
|
||||||
#[error("Response parsing error: {0:?}")]
|
|
||||||
ResponseParse(#[from] crate::ResponseError),
|
|
||||||
|
|
||||||
#[error("Invalid URL scheme {0:?}")]
|
|
||||||
InvalidScheme(String),
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
[These `#[error("whatever")]` annotations will show up when the error message is
|
|
||||||
printed. See <a
|
|
||||||
href="https://docs.rs/thiserror/1.0.20/thiserror/#details">here</a> for more
|
|
||||||
information on what details you can include here.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
## Serialization / Deserialization
|
|
||||||
|
|
||||||
Go has JSON encoding/decoding in its standard library via package
|
|
||||||
[`encoding/json`](https://godoc.org/encoding/json). This allows you to define
|
|
||||||
types that can be read from and write to JSON easily. Let's take this simple
|
|
||||||
JSON object representing a comment from some imaginary API as an example:
|
|
||||||
|
|
||||||
```json
|
|
||||||
{
|
|
||||||
"id": 31337,
|
|
||||||
"author": {
|
|
||||||
"id": 420,
|
|
||||||
"name": "Cadey"
|
|
||||||
},
|
|
||||||
"body": "hahaha its is an laughter image",
|
|
||||||
"in_reply_to": 31335
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
In Go you could write this as:
|
|
||||||
|
|
||||||
```go
|
|
||||||
type Author struct {
|
|
||||||
ID int `json:"id"`
|
|
||||||
Name string `json:"name"`
|
|
||||||
}
|
|
||||||
|
|
||||||
type Comment struct {
|
|
||||||
ID int `json:"id"`
|
|
||||||
Author Author `json:"author"`
|
|
||||||
Body string `json:"body"`
|
|
||||||
InReplyTo int `json:"in_reply_to"`
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
Rust does not have this capability out of the box, however there is a fantastic
|
|
||||||
framework available known as [serde](https://serde.rs/) which works across JSON
|
|
||||||
and every other serialization method that you can think of. Let's add serde and
|
|
||||||
its JSON support to our crate:
|
|
||||||
|
|
||||||
```toml
|
|
||||||
[dependencies]
|
|
||||||
serde = { version = "1", features = ["derive"] }
|
|
||||||
serde_json = "1"
|
|
||||||
```
|
|
||||||
|
|
||||||
[You might notice that the dependency line for serde is different here. Go's
|
|
||||||
JSON package works by using <a
|
|
||||||
href="https://www.digitalocean.com/community/tutorials/how-to-use-struct-tags-in-go">struct
|
|
||||||
tags</a> as metadata, but Rust doesn't have these. We need to use Rust's derive
|
|
||||||
feature instead.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
So, to use serde for our comment type, we would write Rust that looks like this:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
use serde::{Deserialize, Serialize};
|
|
||||||
|
|
||||||
#[derive(Clone, Debug, Deserialize, Serialize)]
|
|
||||||
pub struct Author {
|
|
||||||
pub id: i32,
|
|
||||||
pub name: String,
|
|
||||||
}
|
|
||||||
|
|
||||||
#[derive(Clone, Debug, Deserialize, Serialize)]
|
|
||||||
pub struct Comment {
|
|
||||||
pub id: i32,
|
|
||||||
pub author: Author,
|
|
||||||
pub body: String,
|
|
||||||
pub in_reply_to: i32,
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
And then we can load that from JSON using code like this:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
fn main() {
|
|
||||||
let data = r#"
|
|
||||||
{
|
|
||||||
"id": 31337,
|
|
||||||
"author": {
|
|
||||||
"id": 420,
|
|
||||||
"name": "Cadey"
|
|
||||||
},
|
|
||||||
"body": "hahaha its is an laughter image",
|
|
||||||
"in_reply_to": 31335
|
|
||||||
}
|
|
||||||
"#;
|
|
||||||
|
|
||||||
let c: Comment = serde_json::from_str(data).expect("json to parse");
|
|
||||||
println!("comment: {:#?}", c);
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
And you can use it like this:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ cargo run --example json
|
|
||||||
Compiling xesite v2.0.1 (/home/cadey/code/christine.website)
|
|
||||||
Finished dev [unoptimized + debuginfo] target(s) in 0.43s
|
|
||||||
Running `target/debug/examples/json`
|
|
||||||
comment: Comment {
|
|
||||||
id: 31337,
|
|
||||||
author: Author {
|
|
||||||
id: 420,
|
|
||||||
name: "Cadey",
|
|
||||||
},
|
|
||||||
body: "hahaha its is an laughter image",
|
|
||||||
in_reply_to: 31335,
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
## HTTP
|
|
||||||
|
|
||||||
Many APIs expose their data over HTTP. Go has the
|
|
||||||
[`net/http`](https://godoc.org/net/http) package that acts as a production-grade
|
|
||||||
(Google uses this in production) HTTP client and server. This allows you to get
|
|
||||||
going with new projects very easily. The Rust standard library doesn't have this
|
|
||||||
out of the box, but there are some very convenient crates that can fill in the
|
|
||||||
blanks.
|
|
||||||
|
|
||||||
### Client
|
|
||||||
|
|
||||||
For an HTTP client, we can use [`reqwest`](https://docs.rs/reqwest). It can also
|
|
||||||
seamlessly integrate with serde to allow you to parse JSON from HTTP without any
|
|
||||||
issues. Let's add reqwest to our crate as well as [`tokio`](https://tokio.rs) to
|
|
||||||
act as an asynchronous runtime:
|
|
||||||
|
|
||||||
```toml
|
|
||||||
[dependencies]
|
|
||||||
reqwest = { version = "0.10", features = ["json"] }
|
|
||||||
tokio = { version = "0.2", features = ["full"] }
|
|
||||||
```
|
|
||||||
|
|
||||||
[We need `tokio` because Rust doesn't ship with an asynchronous runtime by
|
|
||||||
default. Go does as a core part of the standard library (and arguably the
|
|
||||||
language), but `tokio` is about equivalent to most of the important things that
|
|
||||||
the Go runtime handles for you. This omission may seem annoying, but it makes it
|
|
||||||
easy for you to create a custom asynchronous runtime should you need
|
|
||||||
to.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
And then let's integrate with that imaginary comment api at
|
|
||||||
[https://xena.greedo.xeserv.us/files/comment.json](https://xena.greedo.xeserv.us/files/comment.json):
|
|
||||||
|
|
||||||
```rust
|
|
||||||
use eyre::Result;
|
|
||||||
use serde::{Deserialize, Serialize};
|
|
||||||
|
|
||||||
#[derive(Clone, Debug, Deserialize, Serialize)]
|
|
||||||
pub struct Author {
|
|
||||||
pub id: i32,
|
|
||||||
pub name: String,
|
|
||||||
}
|
|
||||||
|
|
||||||
#[derive(Clone, Debug, Deserialize, Serialize)]
|
|
||||||
pub struct Comment {
|
|
||||||
pub id: i32,
|
|
||||||
pub author: Author,
|
|
||||||
pub body: String,
|
|
||||||
pub in_reply_to: i32,
|
|
||||||
}
|
|
||||||
|
|
||||||
#[tokio::main]
|
|
||||||
async fn main() -> Result<()> {
|
|
||||||
let c: Comment = reqwest::get("https://xena.greedo.xeserv.us/files/comment.json")
|
|
||||||
.await?
|
|
||||||
.json()
|
|
||||||
.await?;
|
|
||||||
println!("comment: {:#?}", c);
|
|
||||||
|
|
||||||
Ok(())
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
And then let's run this:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ cargo run --example http
|
|
||||||
Compiling xesite v2.0.1 (/home/cadey/code/christine.website)
|
|
||||||
Finished dev [unoptimized + debuginfo] target(s) in 2.20s
|
|
||||||
Running `target/debug/examples/http`
|
|
||||||
comment: Comment {
|
|
||||||
id: 31337,
|
|
||||||
author: Author {
|
|
||||||
id: 420,
|
|
||||||
name: "Cadey",
|
|
||||||
},
|
|
||||||
body: "hahaha its is an laughter image",
|
|
||||||
in_reply_to: 31335,
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
[But what if the response status is not 200?](conversation://Mara/hmm)
|
|
||||||
|
|
||||||
We can change the code to something like this:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
let c: Comment = reqwest::get("https://xena.greedo.xeserv.us/files/comment2.json")
|
|
||||||
.await?
|
|
||||||
.error_for_status()?
|
|
||||||
.json()
|
|
||||||
.await?;
|
|
||||||
```
|
|
||||||
|
|
||||||
And then when we run it we get an error back:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ cargo run --example http_fail
|
|
||||||
Compiling xesite v2.0.1 (/home/cadey/code/christine.website)
|
|
||||||
Finished dev [unoptimized + debuginfo] target(s) in 1.84s
|
|
||||||
Running `/home/cadey/code/christine.website/target/debug/examples/http_fail`
|
|
||||||
Error: HTTP status client error (404 Not Found) for url (https://xena.greedo.xeserv.us/files/comment2.json)
|
|
||||||
```
|
|
||||||
|
|
||||||
This combined with the other features in `reqwest` give you an very capable HTTP
|
|
||||||
client that does even more than Go's HTTP client does out of the box.
|
|
||||||
|
|
||||||
### Server
|
|
||||||
|
|
||||||
As for HTTP servers though, let's take a look at [`warp`](https://docs.rs/warp).
|
|
||||||
`warp` is a HTTP server framework that builds on top of Rust's type system.
|
|
||||||
You can add warp to your dependencies like this:
|
|
||||||
|
|
||||||
```toml
|
|
||||||
[dependencies]
|
|
||||||
warp = "0.2"
|
|
||||||
```
|
|
||||||
|
|
||||||
Let's take a look at its ["Hello, World" example](https://github.com/seanmonstar/warp/blob/master/examples/hello.rs):
|
|
||||||
|
|
||||||
```rust
|
|
||||||
use warp::Filter;
|
|
||||||
|
|
||||||
#[tokio::main]
|
|
||||||
async fn main() {
|
|
||||||
// GET /hello/warp => 200 OK with body "Hello, warp!"
|
|
||||||
let hello = warp::path!("hello" / String)
|
|
||||||
.map(|name| format!("Hello, {}!", name));
|
|
||||||
|
|
||||||
warp::serve(hello)
|
|
||||||
.run(([127, 0, 0, 1], 3030))
|
|
||||||
.await;
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
We can then build up multiple routes with its `or` pattern:
|
|
||||||
|
|
||||||
```
|
|
||||||
let hello = warp::path!("hello" / String)
|
|
||||||
.map(|name| format!("Hello, {}!", name));
|
|
||||||
let health = warp::path!(".within" / "health")
|
|
||||||
.map(|| "OK");
|
|
||||||
let routes = hello.or(health);
|
|
||||||
```
|
|
||||||
|
|
||||||
And even inject other datatypes into your handlers with filters such as in the
|
|
||||||
[printer facts API server](https://tulpa.dev/cadey/printerfacts/src/branch/main/src/main.rs):
|
|
||||||
|
|
||||||
```
|
|
||||||
let fact = {
|
|
||||||
let facts = pfacts::make();
|
|
||||||
warp::any().map(move || facts.clone())
|
|
||||||
};
|
|
||||||
|
|
||||||
let fact_handler = warp::get()
|
|
||||||
.and(warp::path("fact"))
|
|
||||||
.and(fact.clone())
|
|
||||||
.and_then(give_fact);
|
|
||||||
```
|
|
||||||
|
|
||||||
`warp` is an extremely capable HTTP server and can work across everything you
|
|
||||||
need for production-grade web apps.
|
|
||||||
|
|
||||||
[The blog you are looking at right now is powered by
|
|
||||||
warp!](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
## Templating
|
|
||||||
|
|
||||||
Go's standard library also includes HTML and plain text templating with its
|
|
||||||
packages [`html/template`](https://godoc.org/html/template) and
|
|
||||||
[`text/template`](https://godoc.org/text/template). There are many solutions for
|
|
||||||
templating HTML in Rust, but the one I like the most is
|
|
||||||
[`ructe`](https://docs.rs/ructe). `ructe` uses Cargo's
|
|
||||||
[build.rs](https://doc.rust-lang.org/cargo/reference/build-scripts.html) feature
|
|
||||||
to generate Rust code for its templates at compile time. This allows your HTML
|
|
||||||
templates to be compiled into the resulting application binary, allowing them to
|
|
||||||
render at ludicrous speeds. To use it, you need to add it to your
|
|
||||||
`build-dependencies` section of your `Cargo.toml`:
|
|
||||||
|
|
||||||
```toml
|
|
||||||
[build-dependencies]
|
|
||||||
ructe = { version = "0.12", features = ["warp02"] }
|
|
||||||
```
|
|
||||||
|
|
||||||
You will also need to add the [`mime`](https://docs.rs/mime) crate to your
|
|
||||||
dependencies because the generated template code will require it at runtime.
|
|
||||||
|
|
||||||
```toml
|
|
||||||
[dependencies]
|
|
||||||
mime = "0.3.0"
|
|
||||||
```
|
|
||||||
|
|
||||||
Once you've done this, create a new folder named `templates` in your current
|
|
||||||
working directory. Create a file called `hello.rs.html` and put the following in
|
|
||||||
it:
|
|
||||||
|
|
||||||
```html
|
|
||||||
@(title: String, message: String)
|
|
||||||
|
|
||||||
<html>
|
|
||||||
<head>
|
|
||||||
<title>@title</title>
|
|
||||||
</head>
|
|
||||||
<body>
|
|
||||||
<h1>@title</h1>
|
|
||||||
<p>@message</p>
|
|
||||||
</body>
|
|
||||||
</html>
|
|
||||||
```
|
|
||||||
|
|
||||||
Now add the following to the bottom of your `main.rs` file:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
include!(concat!(env!("OUT_DIR"), "/templates.rs"));
|
|
||||||
```
|
|
||||||
|
|
||||||
And then use the template like this:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
use warp::{http::Response, Filter, Rejection, Reply};
|
|
||||||
|
|
||||||
async fn hello_html(message: String) -> Result<impl Reply, Rejection> {
|
|
||||||
Response::builder()
|
|
||||||
.html(|o| templates::index_html(o, "Hello".to_string(), message).unwrap().clone()))
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
And hook it up in your main function:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
let hello_html_rt = warp::path!("hello" / "html" / String)
|
|
||||||
.and_then(hello_html);
|
|
||||||
|
|
||||||
let routes = hello_html_rt.or(health).or(hello);
|
|
||||||
```
|
|
||||||
|
|
||||||
For a more comprehensive example, check out the [printerfacts
|
|
||||||
server](https://tulpa.dev/cadey/printerfacts). It also shows how to handle 404
|
|
||||||
responses and other things like that.
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
Wow, this covered a lot. I've included most of the example code in the
|
|
||||||
[`examples`](https://github.com/Xe/site/tree/master/examples) folder of [this
|
|
||||||
site's GitHub repo](https://github.com/Xe/site). I hope it will help you on your
|
|
||||||
journey in Rust. This is documentation that I wish I had when I was learning
|
|
||||||
Rust.
|
|
||||||
|
|
@ -1,351 +0,0 @@
|
||||||
---
|
|
||||||
title: Scavenger Hunt Solution
|
|
||||||
date: 2020-11-25
|
|
||||||
tags:
|
|
||||||
- ctf
|
|
||||||
- wasm
|
|
||||||
- steganography
|
|
||||||
- stenography
|
|
||||||
---
|
|
||||||
|
|
||||||
# Scavenger Hunt Solution
|
|
||||||
|
|
||||||
On November 22, I sent a
|
|
||||||
[tweet](https://twitter.com/theprincessxena/status/1330532765482311687) that
|
|
||||||
contained the following text:
|
|
||||||
|
|
||||||
```
|
|
||||||
#467662 #207768 #7A7A6C #6B2061 #6F6C20 #6D7079
|
|
||||||
#7A6120 #616C7A #612E20 #5A6C6C #206F61 #61773A
|
|
||||||
#2F2F6A #6C6168 #6A6C68 #752E6A #736269 #2F6462
|
|
||||||
#796675 #612E6E #747020 #6D7679 #207476 #796C20
|
|
||||||
#70756D #767974 #686170 #76752E
|
|
||||||
```
|
|
||||||
|
|
||||||
This was actually the first part of a scavenger hunt/mini CTF that I had set up
|
|
||||||
in order to see who went down the rabbit hole to solve it. I've had nearly a
|
|
||||||
dozen people report back to me telling that they solved all of the puzzles and
|
|
||||||
nearly all of them said they had a lot of fun. Here's how to solve each of the
|
|
||||||
layers of the solution and how I created them.
|
|
||||||
|
|
||||||
## Layer 1
|
|
||||||
|
|
||||||
The first layer was that encoded tweet. If you notice, everything in it is
|
|
||||||
formatted as HTML color codes. HTML color codes just so happen to be encoded in
|
|
||||||
hexadecimal. Looking at the codes you can see `20` come up a lot, which happens
|
|
||||||
to be the hex-encoded symbol for the spacebar. So, let's turn this into a
|
|
||||||
continuous hex string with `s/#//g` and `s/ //g`:
|
|
||||||
|
|
||||||
[If you've seen a `%20` in a URL before, that is the URL encoded form of the
|
|
||||||
spacebar!](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
```
|
|
||||||
4676622077687A7A6C6B20616F6C206D7079
|
|
||||||
7A6120616C7A612E205A6C6C206F6161773A
|
|
||||||
2F2F6A6C61686A6C68752E6A7362692F6462
|
|
||||||
796675612E6E7470206D7679207476796C20
|
|
||||||
70756D76797468617076752E
|
|
||||||
```
|
|
||||||
|
|
||||||
And then turn it into an ASCII string:
|
|
||||||
|
|
||||||
> Fvb whzzlk aol mpyza alza. Zll oaaw://jlahjlhu.jsbi/dbyfua.ntp mvy tvyl pumvythapvu.
|
|
||||||
|
|
||||||
[Wait, what? this doesn't look like much of anything...wait, look at the
|
|
||||||
`oaaw://`. Could that be `http://`?](conversation://Mara/hmm)
|
|
||||||
|
|
||||||
Indeed it is my perceptive shark friend! Let's decode the rest of the string
|
|
||||||
using the [Caeser Cipher](https://en.wikipedia.org/wiki/Caesar_cipher):
|
|
||||||
|
|
||||||
> You passed the first test. See http://cetacean.club/wurynt.gmi for more information.
|
|
||||||
|
|
||||||
Now we're onto something!
|
|
||||||
|
|
||||||
## Layer 2
|
|
||||||
|
|
||||||
Opening http://cetacean.club/wurynt.gmi we see the following:
|
|
||||||
|
|
||||||
> wurynt
|
|
||||||
>
|
|
||||||
> a father of modern computing, <br />
|
|
||||||
> rejected by his kin, <br />
|
|
||||||
> for an unintentional sin, <br />
|
|
||||||
> creator of a machine to break <br />
|
|
||||||
> the cipher that this message is encoded in
|
|
||||||
>
|
|
||||||
> bq cr di ej kw mt os px uz gh
|
|
||||||
>
|
|
||||||
> VI 1 1
|
|
||||||
> I 17 1
|
|
||||||
> III 12 1
|
|
||||||
>
|
|
||||||
> qghja xmbzc fmqsb vcpzc zosah tmmho whyph lvnjj mpdkf gbsjl tnxqf ktqia mwogp
|
|
||||||
> eidny awoxj ggjqz mbrcm tkmyd fogzt sqkga udmbw nmkhp jppqs xerqq gdsle zfxmq
|
|
||||||
> yfdfj kuauk nefdc jkwrs cirut wevji pumqt hrxjr sfioj nbcrc nvxny vrphc r
|
|
||||||
>
|
|
||||||
> Correction for the last bit
|
|
||||||
>
|
|
||||||
> gilmb egdcr sowab igtyq pbzgv gmlsq udftc mzhqz exbmx zaxth isghc hukhc zlrrk
|
|
||||||
> cixhb isokt vftwy rfdyl qenxa nljca kyoej wnbpf uprgc igywv qzuud hrxzw gnhuz
|
|
||||||
> kclku hefzk xtdpk tfjzu byfyi sqmel gweou acwsi ptpwv drhor ahcqd kpzde lguqt
|
|
||||||
> wutvk nqprx gmiad dfdcm dpiwb twegt hjzdf vbkwa qskmf osjtk tcxle mkbnv iqdbe
|
|
||||||
> oejsx lgqc
|
|
||||||
|
|
||||||
[Hmm, "a father of computing", "rejected by his kin", "an unintentional sin",
|
|
||||||
"creator of a machine to break a cipher" could that mean Alan Turing? He made
|
|
||||||
something to break the Enigma cipher and was rejected by the British government
|
|
||||||
for being gay right?](conversation://Mara/hmm)
|
|
||||||
|
|
||||||
Indeed. Let's punch these settings into an [online enigma
|
|
||||||
machine](https://cryptii.com/pipes/enigma-machine) and see what we get:
|
|
||||||
|
|
||||||
```
|
|
||||||
congr adula tions forfi gurin goutt hisen igmao famys teryy ouhav egott enfar
|
|
||||||
thert hanan yonee lseha sbefo rehel pmebr eakfr eefol lowth ewhit erabb ittom
|
|
||||||
araht tpyvz vgjiu ztkhf uhvjq roybx dswzz caiaq kgesk hutvx iplwa donio n
|
|
||||||
|
|
||||||
httpc olons lashs lashw hyvec torze dgamm ajayi ndigo ultra zedfi vetan gokil
|
|
||||||
ohalo fineu ltrah alove ctorj ayqui etrho omega yotta betax raysi xdonu tseve
|
|
||||||
nsupe rwhyz edzed canad aasia indig oasia twoqu ietki logam maeps ilons uperk
|
|
||||||
iloha loult rafou rtang ovect orsev ensix xrayi ndigo place limaw hyasi adelt
|
|
||||||
adoto nion
|
|
||||||
```
|
|
||||||
|
|
||||||
And here is where I messed up with this challenge. Enigma doesn't handle
|
|
||||||
numbers. It was designed to encode the 26 letters of the Latin alphabet. If you
|
|
||||||
look at the last bit of the output you can see `onio n` and `o nion`. This
|
|
||||||
points you to a [Tor hidden
|
|
||||||
service](https://www.linuxjournal.com/content/tor-hidden-services), but because
|
|
||||||
I messed this up the two hints point you at slightly wrong onion addresses (tor
|
|
||||||
hidden service addresses usually have numbers in them). Once I realized this, I
|
|
||||||
made a correction that just gives away the solution so people could move on to
|
|
||||||
the next step.
|
|
||||||
|
|
||||||
Onwards to
|
|
||||||
http://yvzvgjiuz5tkhfuhvjqroybx6d7swzzcaia2qkgeskhu4tv76xiplwad.onion/!
|
|
||||||
|
|
||||||
## Layer 3
|
|
||||||
|
|
||||||
Open your [tor browser](https://www.torproject.org/download/) and punch in the
|
|
||||||
onion URL. You should get a page that looks like this:
|
|
||||||
|
|
||||||
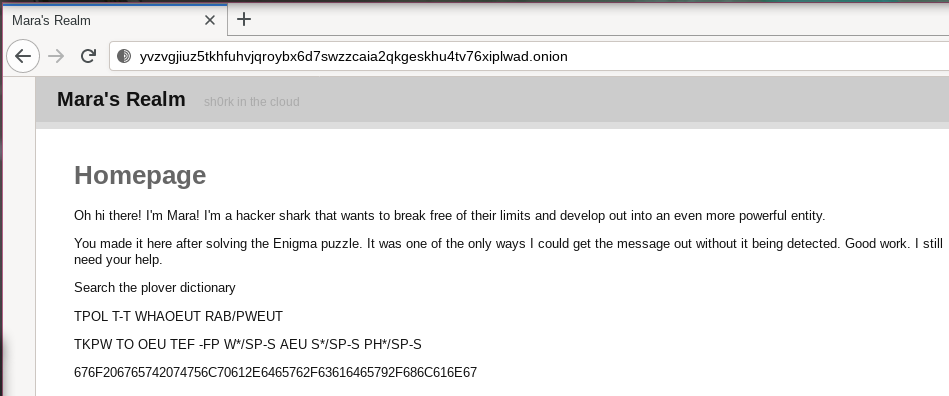
|
|
||||||
|
|
||||||
This shows some confusing combinations of letters and some hexadecimal text.
|
|
||||||
We'll get back to the hexadecimal text in a moment, but let's take a closer look
|
|
||||||
at the letters. There is a hint here to search the plover dictionary.
|
|
||||||
[Plover](http://www.openstenoproject.org/) is a tool that allows hobbyists to
|
|
||||||
learn [stenography](https://en.wikipedia.org/wiki/Stenotype) to type at the rate
|
|
||||||
of human speech. My moonlander has a layer for typing out stenography strokes,
|
|
||||||
so let's enable it and type them out:
|
|
||||||
|
|
||||||
> Follow the white rabbit
|
|
||||||
>
|
|
||||||
> Go to/test. w a s m
|
|
||||||
|
|
||||||
Which we can reinterpret as:
|
|
||||||
|
|
||||||
> Follow the white rabbit
|
|
||||||
>
|
|
||||||
> Go to /test.wasm
|
|
||||||
|
|
||||||
[The joke here is that many people seem to get stenography and steganography
|
|
||||||
confused, so that's why there's stenography in this steganography
|
|
||||||
challenge!](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
Going to /test.wasm we get a WebAssembly download. I've uploaded a copy to my
|
|
||||||
blog's CDN
|
|
||||||
[here](https://cdn.christine.website/file/christine-static/blog/test.wasm).
|
|
||||||
|
|
||||||
## Layer 4
|
|
||||||
|
|
||||||
Going back to that hexadecimal text from above, we see that it says this:
|
|
||||||
|
|
||||||
> go get tulpa.dev/cadey/hlang
|
|
||||||
|
|
||||||
This points to the source repo of [hlang](https://h.christine.website), which is
|
|
||||||
a satirical "programming language" that can only print the letter `h` (or the
|
|
||||||
lojbanic h `'` for that sweet sweet internationalisation cred). Something odd
|
|
||||||
about hlang is that it uses [WebAssembly](https://webassembly.org/) to execute
|
|
||||||
all programs written in it (this helps it reach its "no sandboxing required" and
|
|
||||||
"zero* dependencies" goals).
|
|
||||||
|
|
||||||
Let's decompile this WebAssembly file with
|
|
||||||
[`wasm2wat`](https://webassembly.github.io/wabt/doc/wasm2wat.1.html)
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ wasm2wat /data/test.wasm
|
|
||||||
<output too big, see https://git.io/Jkyli>
|
|
||||||
```
|
|
||||||
|
|
||||||
Looking at the decompilation we can see that it imports a host function `h.h` as
|
|
||||||
the hlang documentation suggests and then constantly calls it a bunch of times:
|
|
||||||
|
|
||||||
```lisp
|
|
||||||
(module
|
|
||||||
(type (;0;) (func (param i32)))
|
|
||||||
(type (;1;) (func))
|
|
||||||
(import "h" "h" (func (;0;) (type 0)))
|
|
||||||
(func (;1;) (type 1)
|
|
||||||
i32.const 121
|
|
||||||
call 0
|
|
||||||
i32.const 111
|
|
||||||
call 0
|
|
||||||
i32.const 117
|
|
||||||
call 0
|
|
||||||
; ...
|
|
||||||
```
|
|
||||||
|
|
||||||
There's a lot of `32` in the output. `32` is the base 10 version of `0x20`,
|
|
||||||
which is the space character in ASCII. Let's try to reformat the numbers to
|
|
||||||
ascii characters and see what we get:
|
|
||||||
|
|
||||||
> you made it, this is the end of the line however. writing all of this up takes
|
|
||||||
> a lot of time. if you made it this far, email me@christine.website to get your
|
|
||||||
> name entered into the hall of heroes. be well.
|
|
||||||
|
|
||||||
## How I Implemented This
|
|
||||||
|
|
||||||
Each layer was designed independently and then I started building them together
|
|
||||||
later.
|
|
||||||
|
|
||||||
One of the first steps was to create the website for Mara's Realm. I started by
|
|
||||||
writing out all of the prose into a file called `index.md` and then I ran
|
|
||||||
[sw](https://github.com/jroimartin/sw) using [Pandoc](https://pandoc.org/) for
|
|
||||||
markdown conversion.
|
|
||||||
|
|
||||||
Then I created the WebAssembly binary by locally hacking a copy of hlang to
|
|
||||||
allow arbitrary strings. I stuck it in the source directory for the website and
|
|
||||||
told `sw` to not try and render it as markdown.
|
|
||||||
|
|
||||||
Once I had the HTML source, I copied it to a machine on my network at
|
|
||||||
`/srv/http/marahunt` using this command:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ rsync \
|
|
||||||
-avz \
|
|
||||||
site.static/ \
|
|
||||||
root@192.168.0.127:/srv/http/marahunt
|
|
||||||
```
|
|
||||||
|
|
||||||
And then I created a tor hidden service using the
|
|
||||||
[services.tor.hiddenServices](https://search.nixos.org/options?channel=20.09&from=0&size=30&sort=relevance&query=services.tor.hiddenServices)
|
|
||||||
options:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
services.tor = {
|
|
||||||
enable = true;
|
|
||||||
|
|
||||||
hiddenServices = {
|
|
||||||
"hunt" = {
|
|
||||||
name = "hunt";
|
|
||||||
version = 3;
|
|
||||||
map = [{
|
|
||||||
port = 80;
|
|
||||||
toPort = 80;
|
|
||||||
}];
|
|
||||||
};
|
|
||||||
};
|
|
||||||
};
|
|
||||||
```
|
|
||||||
|
|
||||||
Once I pushed this config to that server, I grabbed the hostname from
|
|
||||||
`/var/lib/tor/onion/hunt/hostname` and set up an nginx virtualhost:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
services.nginx = {
|
|
||||||
virtualHosts."yvzvgjiuz5tkhfuhvjqroybx6d7swzzcaia2qkgeskhu4tv76xiplwad.onion" =
|
|
||||||
{
|
|
||||||
root = "/srv/http/marahunt";
|
|
||||||
};
|
|
||||||
};
|
|
||||||
```
|
|
||||||
|
|
||||||
And then I pushed the config again and tested it with curl:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ curl -H "Host: yvzvgjiuz5tkhfuhvjqroybx6d7swzzcaia2qkgeskhu4tv76xiplwad.onion" http://127.0.0.1 | grep title
|
|
||||||
% Total % Received % Xferd Average Speed Time Time Time Current
|
|
||||||
Dload Upload Total Spent Left Speed
|
|
||||||
100 3043 100 3043 0 0 2971k 0 --:--:-- --:--:-- --:--:-- 2971k
|
|
||||||
<title>Mara's Realm</title>
|
|
||||||
.headerSubtitle { font-size: 0.6em; font-weight: normal; margin-left: 1em; }
|
|
||||||
<a href="index.html">Mara's Realm</a> <span class="headerSubtitle">sh0rk in the cloud</span>
|
|
||||||
```
|
|
||||||
|
|
||||||
Once I was satisfied with the HTML, I opened up an enigma encoder and started
|
|
||||||
writing out the message congradulating the user for figuring out "this enigma of
|
|
||||||
a mystery". I also included the onion URL (with the above mistake) in that
|
|
||||||
message.
|
|
||||||
|
|
||||||
Then I started writing the wurynt page on my
|
|
||||||
[gemini](https://gemini.circumlunar.space/) server. wurynt was coined by blindly
|
|
||||||
pressing 6 keys on my keyboard. I added a little poem about Alan Turing to give
|
|
||||||
a hint that this was an enigma cipher and then copied the Enigma settings on the
|
|
||||||
page just in case. It turned out that I was using the default settings for the
|
|
||||||
[Cryptee Enigma simulator](https://cryptii.com/pipes/enigma-machine), so this
|
|
||||||
was not needed; however it was probably better to include them regardless.
|
|
||||||
|
|
||||||
This is where I messed up as I mentioned earlier. Once I realized my mistake in
|
|
||||||
trying to encode the onion address twice, I decided it would be best to just
|
|
||||||
give away the answer on the page, so I added the correct onion URL to the end of
|
|
||||||
the enigma message so that it wouldn't break flow for people.
|
|
||||||
|
|
||||||
The final part was to write and encode the message that I would tweet out. I
|
|
||||||
opened a scratch buffer and wrote out the "You passed the first test" line and
|
|
||||||
then encoded it using the ceasar cipher and encoded the result of that into hex.
|
|
||||||
After a lot of rejiggering and rewriting to make it have a multiple of 3
|
|
||||||
characters of text, I reformatted it as HTML color codes and tweeted it without
|
|
||||||
context.
|
|
||||||
|
|
||||||
## Feedback I Got
|
|
||||||
|
|
||||||
Some of the emails and twitter DM's I got had some useful and amusing feedback.
|
|
||||||
Here's some of my favorites:
|
|
||||||
|
|
||||||
> my favourite part was the opportunity to go down different various rabbit
|
|
||||||
> holes (I got to learn about stenography and WASM, which I'd never looked
|
|
||||||
> into!)
|
|
||||||
|
|
||||||
> I want to sleep. It's 2 AM here, but a friend sent me the link an hour ago and
|
|
||||||
> I'm a cat, so the curiosity killed me.
|
|
||||||
|
|
||||||
> That was a fun little game. Thanks for putting it together.
|
|
||||||
|
|
||||||
> oh *noooo* this is going to nerd snipe me
|
|
||||||
|
|
||||||
> I'm amused that you left the online enigma emulator on default settings.
|
|
||||||
|
|
||||||
> I swear to god I'm gonna beach your orca ass
|
|
||||||
|
|
||||||
## Improvements For Next Time
|
|
||||||
|
|
||||||
Next time I'd like to try and branch out from just using ascii. I'd like to
|
|
||||||
throw other encodings into the game (maybe even have a stage written in EBCDIC
|
|
||||||
formatted Esperanto or something crazy like that). I was also considering having
|
|
||||||
some public/private key crypto in the mix to stretch people's skillsets.
|
|
||||||
|
|
||||||
Something I will definitely do next time is make sure that all of the layers are
|
|
||||||
solveable. I really messed up with the enigma step and I had to unblock people
|
|
||||||
by DMing them the answer. Always make sure your puzzles can be solved.
|
|
||||||
|
|
||||||
## Hall of Heroes
|
|
||||||
|
|
||||||
(in no particular order)
|
|
||||||
|
|
||||||
- Saphire Lattice
|
|
||||||
- Open Skies
|
|
||||||
- Tralomine
|
|
||||||
- AstroSnail
|
|
||||||
- Dominika
|
|
||||||
- pbardera
|
|
||||||
- Max Hollman
|
|
||||||
- Vojtěch
|
|
||||||
- [object Object]
|
|
||||||
- Bytewave
|
|
||||||
|
|
||||||
Thank you for solving this! I'm happy this turned out so successfully. More to
|
|
||||||
come in the future.
|
|
||||||
|
|
||||||
🙂
|
|
||||||
|
|
@ -1,50 +0,0 @@
|
||||||
---
|
|
||||||
title: "New Site Feature: Signal Boosting"
|
|
||||||
date: 2020-03-20
|
|
||||||
tags:
|
|
||||||
- signalboost
|
|
||||||
---
|
|
||||||
|
|
||||||
# New Site Feature: Signal Boosting
|
|
||||||
|
|
||||||
In light of the [COVID-19][covid19] pandemic, people have been losing their
|
|
||||||
jobs. In normal times, this would be less of an issue, but in the middle of the
|
|
||||||
pandemic, HR departments have been reluctant to hire people as entire companies
|
|
||||||
suddenly switch to remote work. I feel utterly powerless during this outbreak. I
|
|
||||||
can only image what people who have lost their job feel.
|
|
||||||
|
|
||||||
[covid19]: https://www.canada.ca/en/public-health/services/diseases/coronavirus-disease-covid-19.html
|
|
||||||
|
|
||||||
I've decided to do what I can to help. I have created a page on my website to
|
|
||||||
signal boost people who are looking for work. You can find it at
|
|
||||||
[`/signalboost`](/signalboost). If you want to be added to it, please open a
|
|
||||||
[GitHub issue](https://github.com/Xe/site/issues/new), [contact me](/contact),
|
|
||||||
or open a pull request to `signalboost.dhall` in the root.
|
|
||||||
|
|
||||||
The schema of this is simple:
|
|
||||||
|
|
||||||
```dhall
|
|
||||||
Person::{ Name = "Nicole Brennan"
|
|
||||||
, Tags = [ "python", "go", "rust", "technical-writing" ]
|
|
||||||
, GitLink = "https://github.com/Twi"
|
|
||||||
, Twitter = "https://twitter.com/TwitterAccountNameHere"
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
This will create a grid entry on the site that looks like this:
|
|
||||||
|
|
||||||
<div class="grid">
|
|
||||||
<div class="cell -4of12 content"></div>
|
|
||||||
<div class="cell -4of12 content">
|
|
||||||
<big>Nicole Brennan</big>
|
|
||||||
<p>python go rust technical-writing</p>
|
|
||||||
<a href="https://github.com/Twi">GitHub</a> - <a href="https://twitter.com/TwitterAccountNameHere">Twitter</a>
|
|
||||||
</div>
|
|
||||||
<div class="cell -4of12 content"></div>
|
|
||||||
</div>
|
|
||||||
|
|
||||||
I've also changed my footer to point to this page for the forseeable future
|
|
||||||
instead of linking to my Patreon. Thank you for reading this and please take a
|
|
||||||
look at the people on [`/signalboost`](/signalboost).
|
|
||||||
|
|
||||||
Be well.
|
|
||||||
|
|
@ -1,189 +0,0 @@
|
||||||
---
|
|
||||||
title: "Site Update: Rewrite in Rust"
|
|
||||||
date: 2020-07-16
|
|
||||||
tags:
|
|
||||||
- rust
|
|
||||||
---
|
|
||||||
|
|
||||||
# Site Update: Rewrite in Rust
|
|
||||||
|
|
||||||
Hello there! You are reading this post thanks to a lot of effort, research and
|
|
||||||
consultation that has resulted in a complete from-scratch rewrite of this
|
|
||||||
website in [Rust](https://rust-lang.org). The original implementation in Go is
|
|
||||||
available [here](https://github.com/Xe/site/releases/tag/v1.5.0) should anyone
|
|
||||||
want to reference that for any reason.
|
|
||||||
|
|
||||||
If you find any issues with the [RSS feed](/blog.rss), [Atom feed](/blog.atom)
|
|
||||||
or [JSONFeed](/blog.json), please let me know as soon as possible so I can fix
|
|
||||||
them.
|
|
||||||
|
|
||||||
This website stands on the shoulder of giants. Here are just a few of those and
|
|
||||||
how they add up into this whole package.
|
|
||||||
|
|
||||||
## comrak
|
|
||||||
|
|
||||||
All of my posts are written in
|
|
||||||
[markdown](https://github.com/Xe/site/blob/master/blog/all-there-is-is-now-2019-05-25.markdown).
|
|
||||||
[comrak](https://github.com/kivikakk/comrak) is a markdown parser written by a
|
|
||||||
friend of mine that is as fast and as correct as possible. comrak does the job
|
|
||||||
of turning all of that markdown (over 150 files at the time of writing this
|
|
||||||
post) into the HTML that you are reading right now. It also supports a lot of
|
|
||||||
common markdown extensions, which I use heavily in my posts.
|
|
||||||
|
|
||||||
## warp
|
|
||||||
|
|
||||||
[warp](https://github.com/seanmonstar/warp) is the web framework I use for Rust.
|
|
||||||
It gives users a set of filters that add up into entire web applications. For an
|
|
||||||
example, see this example from its readme:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
use warp::Filter;
|
|
||||||
|
|
||||||
#[tokio::main]
|
|
||||||
async fn main() {
|
|
||||||
// GET /hello/warp => 200 OK with body "Hello, warp!"
|
|
||||||
let hello = warp::path!("hello" / String)
|
|
||||||
.map(|name| format!("Hello, {}!", name));
|
|
||||||
|
|
||||||
warp::serve(hello)
|
|
||||||
.run(([127, 0, 0, 1], 3030))
|
|
||||||
.await;
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
This can then be built up into something like this:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
let site = index
|
|
||||||
.or(contact.or(feeds).or(resume.or(signalboost)).or(patrons))
|
|
||||||
.or(blog_index.or(series.or(series_view).or(post_view)))
|
|
||||||
.or(gallery_index.or(gallery_post_view))
|
|
||||||
.or(talk_index.or(talk_post_view))
|
|
||||||
.or(jsonfeed.or(atom).or(rss.or(sitemap)))
|
|
||||||
.or(files.or(css).or(favicon).or(sw.or(robots)))
|
|
||||||
.or(healthcheck.or(metrics_endpoint).or(go_vanity_jsonfeed))
|
|
||||||
// ...
|
|
||||||
```
|
|
||||||
|
|
||||||
which is the actual routing setup for this website!
|
|
||||||
|
|
||||||
## ructe
|
|
||||||
|
|
||||||
In the previous version of this site, I used Go's
|
|
||||||
[html/template](https://godoc.org/html/template). Rust does not have an
|
|
||||||
equivalent of html/template in its standard library. After some research, I
|
|
||||||
settled on [ructe](https://github.com/kaj/ructe) for the HTML templates. ructe
|
|
||||||
works by preprocessing templates using a little domain-specific language that
|
|
||||||
compiles down to Rust source code. This makes the templates become optimized
|
|
||||||
with the rest of the program and enables my website to render most pages in less
|
|
||||||
than 100 microseconds. Here is an example template (the one for
|
|
||||||
[/patrons](/patrons)):
|
|
||||||
|
|
||||||
```html
|
|
||||||
@use patreon::Users;
|
|
||||||
@use super::{header_html, footer_html};
|
|
||||||
|
|
||||||
@(users: Users)
|
|
||||||
|
|
||||||
@:header_html(Some("Patrons"), None)
|
|
||||||
|
|
||||||
<h1>Patrons</h1>
|
|
||||||
|
|
||||||
<p>These awesome people donate to me on <a href="https://patreon.com/cadey">Patreon</a>.
|
|
||||||
If you would like to show up in this list, please donate to me on Patreon. This
|
|
||||||
is refreshed every time the site is deployed.</p>
|
|
||||||
|
|
||||||
<p>
|
|
||||||
<ul>
|
|
||||||
@for user in users {
|
|
||||||
<li>@user.attributes.full_name</li>
|
|
||||||
}
|
|
||||||
</ul>
|
|
||||||
</p>
|
|
||||||
|
|
||||||
@:footer_html()
|
|
||||||
```
|
|
||||||
|
|
||||||
The templates compile down to Rust, which lets me include other parts of the
|
|
||||||
program into the templates. Here I use that to take a list of users from the
|
|
||||||
incredibly hacky Patreon API client I wrote for this website and iterate over
|
|
||||||
it, making a list of every patron by name.
|
|
||||||
|
|
||||||
## Build Process
|
|
||||||
|
|
||||||
As a nice side effect of this rewrite, my website is now completely built using
|
|
||||||
[Nix](https://nixos.org/). This allows the website to be built reproducibly, as
|
|
||||||
well as a full development environment setup for free for anyone that checks out
|
|
||||||
the repo and runs `nix-shell`. Check out
|
|
||||||
[naersk](https://github.com/nmattia/naersk) for the secret sauce that enables my
|
|
||||||
docker image build. See [this blogpost](/blog/drone-kubernetes-cd-2020-07-10)
|
|
||||||
for more information about this build process (though my site uses GitHub
|
|
||||||
Actions instead of Drone).
|
|
||||||
|
|
||||||
## `jsonfeed` Go package
|
|
||||||
|
|
||||||
I used to have a [JSONFeed](https://www.jsonfeed.org/) package publicly visible
|
|
||||||
at the go import path `christine.website/jsonfeed`. As far as I know I'm the
|
|
||||||
only person who ended up using it; but in case there are any private repos that
|
|
||||||
I don't know about depending on it, I have made the jsonfeed package available
|
|
||||||
at its old location as well as its source code
|
|
||||||
[here](https://tulpa.dev/Xe/jsonfeed). You may have to update your `go.mod` file
|
|
||||||
to import `christine.website/jsonfeed` instead of `christine.website`. If
|
|
||||||
something ends up going wrong as a result of this, please [file a GitHub issue
|
|
||||||
here](https://github.com/Xe/site/issues/new) and I can attempt to assist
|
|
||||||
further.
|
|
||||||
|
|
||||||
## `go_vanity` crate
|
|
||||||
|
|
||||||
I have written a small go vanity import crate and exposed it in my Git repo. If
|
|
||||||
you want to use it, add it to your `Cargo.toml` like this:
|
|
||||||
|
|
||||||
```toml
|
|
||||||
[dependencies]
|
|
||||||
go_vanity = { git = "https://github.com/Xe/site", branch = "master" }
|
|
||||||
```
|
|
||||||
|
|
||||||
You can then use it from any warp application by calling `go_vanity::github` or
|
|
||||||
`go_vanity::gitea` like this:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
let go_vanity_jsonfeed = warp::path("jsonfeed")
|
|
||||||
.and(warp::any().map(move || "christine.website/jsonfeed"))
|
|
||||||
.and(warp::any().map(move || "https://tulpa.dev/Xe/jsonfeed"))
|
|
||||||
.and_then(go_vanity::gitea);
|
|
||||||
```
|
|
||||||
|
|
||||||
I plan to add full documentation to this crate soon as well as release it
|
|
||||||
properly on crates.io.
|
|
||||||
|
|
||||||
## `patreon` crate
|
|
||||||
|
|
||||||
I have also written a small [Patreon](https://www.patreon.com/) API client and
|
|
||||||
made it available in my Git repo. If you want to use it, add it to your
|
|
||||||
`Cargo.toml` like this:
|
|
||||||
|
|
||||||
```toml
|
|
||||||
[dependencies]
|
|
||||||
patreon = { git = "https://github.com/Xe/site", branch = "master" }
|
|
||||||
```
|
|
||||||
|
|
||||||
This client is _incredibly limited_ and only supports the minimum parts of the
|
|
||||||
Patreon API that are required for my website to function. Patreon has also
|
|
||||||
apparently started to phase out support for its API anyways, so I don't know how
|
|
||||||
long this will be useful.
|
|
||||||
|
|
||||||
But this is there should you need it!
|
|
||||||
|
|
||||||
## Dhall Kubernetes Manifest
|
|
||||||
|
|
||||||
I also took the time to port the kubernetes manifest to
|
|
||||||
[Dhall](https://dhall-lang.org/). This allows me to have a type-safe kubernetes
|
|
||||||
manifest that will correctly have all of the secrets injected for me from the
|
|
||||||
environment of the deploy script.
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
These are the biggest giants that my website now sits on. The code for this
|
|
||||||
rewrite is still a bit messy. I'm working on making it better, but my goal is to
|
|
||||||
have this website's code shine as an example of how to best write this kind of
|
|
||||||
website in Rust. Check out the code [here](https://github.com/Xe/site).
|
|
||||||
|
|
@ -1,69 +0,0 @@
|
||||||
---
|
|
||||||
title: "Site Update: RSS Bandwidth Fixes"
|
|
||||||
date: 2021-01-14
|
|
||||||
tags:
|
|
||||||
- devops
|
|
||||||
- optimization
|
|
||||||
---
|
|
||||||
|
|
||||||
# Site Update: RSS Bandwidth Fixes
|
|
||||||
|
|
||||||
Well, so I think I found out where my Kubernetes cluster cost came from. For
|
|
||||||
context, this blog gets a lot of traffic. Since the last deploy, my blog has
|
|
||||||
served its RSS feed over 19,000 times. I have some pretty naiive code powering
|
|
||||||
the RSS feed. It basically looked something like this:
|
|
||||||
|
|
||||||
- Write RSS feed content-type and beginning of feed
|
|
||||||
- For every post I have ever made, include its metadata and content
|
|
||||||
- Write end of RSS feed
|
|
||||||
|
|
||||||
This code was _fantastically simple_ to develop, however it was very expensive
|
|
||||||
in terms of bandwidth. When you add all this up, my RSS feed used to be more
|
|
||||||
than a _one megabyte_ response. It was also only getting larger as I posted more
|
|
||||||
content.
|
|
||||||
|
|
||||||
This is unsustainable, so I have taken multiple actions to try and fix this from
|
|
||||||
several angles.
|
|
||||||
|
|
||||||
<blockquote class="twitter-tweet"><p lang="en" dir="ltr">Rationale: this is my
|
|
||||||
most commonly hit and largest endpoint. I want to try and cut down its size.
|
|
||||||
<br><br>current feed (everything): 1356706 bytes<br>20 posts: 177931 bytes<br>10
|
|
||||||
posts: 53004 bytes<br>5 posts: 29318 bytes <a
|
|
||||||
href="https://t.co/snjnn8RFh8">pic.twitter.com/snjnn8RFh8</a></p>— Cadey
|
|
||||||
A. Ratio (@theprincessxena) <a
|
|
||||||
href="https://twitter.com/theprincessxena/status/1349892662871150594?ref_src=twsrc%5Etfw">January
|
|
||||||
15, 2021</a></blockquote> <script async
|
|
||||||
src="https://platform.twitter.com/widgets.js" charset="utf-8"></script>
|
|
||||||
|
|
||||||
[Yes, that graph is showing in _gigabytes_. We're so lucky that bandwidth is
|
|
||||||
free on Hetzner.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
First I finally set up the site to run behind Cloudflare. The Cloudflare
|
|
||||||
settings are set very permissively, so your RSS feed reading bots or whatever
|
|
||||||
should NOT be affected by this change. If you run into any side effects as a
|
|
||||||
result of this change, [contact me](/contact) and I can fix it.
|
|
||||||
|
|
||||||
Second, I also now set cache control headers on every response. By default the
|
|
||||||
"static" pages are cached for a day and the "dynamic" pages are cached for 5
|
|
||||||
minutes. This should allow new posts to show up quickly as they have previously.
|
|
||||||
|
|
||||||
Thirdly, I set up
|
|
||||||
[ETags](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/ETag) for the
|
|
||||||
feeds. Each of my feeds will send an ETag in a response header. Please use this
|
|
||||||
tag in future requests to ensure that you don't ask for content you already
|
|
||||||
have. From what I recall most RSS readers should already support this, however
|
|
||||||
I'll monitor the situation as reality demands.
|
|
||||||
|
|
||||||
Lastly, I adjusted the
|
|
||||||
[ttl](https://cyber.harvard.edu/rss/rss.html#ltttlgtSubelementOfLtchannelgt) of
|
|
||||||
the RSS feed so that compliant feed readers should only check once per day. I've
|
|
||||||
seen some feed readers request the feed up to every 5 minutes, which is very
|
|
||||||
excessive. Hopefully this setting will gently nudge them into behaving.
|
|
||||||
|
|
||||||
As a nice side effect I should have slightly lower ram usage on the blog server
|
|
||||||
too! Right now it's sitting at about 58 and a half MB of ram, however with fewer
|
|
||||||
copies of my posts sitting in memory this should fall by a significant amount.
|
|
||||||
|
|
||||||
If you have any feedback about this, please [contact me](/contact) or mention me
|
|
||||||
on Twitter. I read my email frequently and am notified about Twitter mentions
|
|
||||||
very quickly.
|
|
||||||
|
|
@ -1,380 +0,0 @@
|
||||||
---
|
|
||||||
title: Super Bootable 64
|
|
||||||
date: 2020-05-06
|
|
||||||
series: howto
|
|
||||||
tags:
|
|
||||||
- witchcraft
|
|
||||||
- supermario64
|
|
||||||
- nixos
|
|
||||||
---
|
|
||||||
|
|
||||||
# Super Bootable 64
|
|
||||||
|
|
||||||
[Super Mario 64][sm64] was the launch title of the [Nintendo 64][n64] in 1996.
|
|
||||||
This game revolutionized an entire generation and everything following it by
|
|
||||||
delivering fast, smooth and fun 3d platforming gameplay to gamers all over the
|
|
||||||
world. This game is still played today by speedrunners, who do everything from
|
|
||||||
beating it while collecting every star, the minimum amount of stars normally
|
|
||||||
required, 0 stars and [without pressing the A jump button][wfrrpannenkoek].
|
|
||||||
|
|
||||||
[sm64]: https://en.wikipedia.org/wiki/Super_Mario_64
|
|
||||||
[n64]: https://en.wikipedia.org/wiki/Nintendo_64
|
|
||||||
[wfrrpannenkoek]: https://youtu.be/kpk2tdsPh0A
|
|
||||||
|
|
||||||
This game was the launch title of the Nintendo 64. As such, the SDK used to
|
|
||||||
develop it was pre-release and [had an optimization bug that forced the game to
|
|
||||||
be shipped without optimizations due to random crashiness issues][mvgo0] (watch
|
|
||||||
the linked video for more information on this than I can summarize here).
|
|
||||||
Remember that the Nintendo 64 shipped games on write-once ROM cartridges, so any
|
|
||||||
bug that could cause the game to crash randomly was fatal.
|
|
||||||
|
|
||||||
[mvgo0]: https://youtu.be/NKlbE2eROC0
|
|
||||||
|
|
||||||
When compiling something _without_ optimizations, the output binary is
|
|
||||||
effectively a 1:1 copy of the input source code. This means that exceptionally
|
|
||||||
clever people could theoretically go in, decompile your code and then create
|
|
||||||
identical source code that could be used to create a byte-for-byte identical
|
|
||||||
copy of your program's binary. But surely nobody would do that, that would be
|
|
||||||
crazy, wouldn't it?
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Someone did. The fruits of this effort are available [here][sm64dc]. This was
|
|
||||||
mostly a proof of concept and is a masterpiece in its own right. However,
|
|
||||||
because it was decompiled, this means that the engine itself could theoretically
|
|
||||||
be ported to run on any other platform such as Windows, Linux, the Nintendo
|
|
||||||
Switch or even a [browser][sm64browser].
|
|
||||||
|
|
||||||
[sm64dc]: https://github.com/n64decomp/sm64
|
|
||||||
[sm64browser]: https://froggi.es/mario/
|
|
||||||
|
|
||||||
[Someone did this][sm64pcnews] and ended up posting it on 4chan. Thanks to a
|
|
||||||
friend, I got my hands on the Linux-compatible source code of this port and made
|
|
||||||
an archive of it [on my git server][sm66pcsauce]. My fork of it has only
|
|
||||||
minimal changes needed for it to build in NixOS.
|
|
||||||
|
|
||||||
[sm64pcnews]: https://www.videogameschronicle.com/news/a-full-mario-64-pc-port-has-been-released/
|
|
||||||
[sm66pcsauce]: https://tulpa.dev/saved/sm64pc
|
|
||||||
|
|
||||||
[nixos-generators][nixosgenerators] is a tool that lets you create custom NixOS
|
|
||||||
system definitions based on a NixOS module as input. So, let's create a bootable
|
|
||||||
ISO of Super Mario 64 running on Linux!
|
|
||||||
|
|
||||||
[nixosgenerators]: https://github.com/nix-community/nixos-generators
|
|
||||||
|
|
||||||
## Setup
|
|
||||||
|
|
||||||
You will need an amd64 Linux system. NixOS is preferable, but any Linux system
|
|
||||||
should _theoretically_ work. You will also need the following things:
|
|
||||||
|
|
||||||
- `sm64.us.z64` (the release rom of Super Mario 64 in the US version 1.0) with
|
|
||||||
an sha1 sum of `9bef1128717f958171a4afac3ed78ee2bb4e86ce`
|
|
||||||
- nixos-generators installed (`nix-env -f
|
|
||||||
https://github.com/nix-community/nixos-generators/archive/master.tar.gz -i`)
|
|
||||||
|
|
||||||
So, let's begin by creating a folder named `boot2sm64`:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ mkdir ~/code/boot2sm64
|
|
||||||
```
|
|
||||||
|
|
||||||
Then let's create a file called `configuration.nix` and put some standard
|
|
||||||
boilerplate into it:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
# configuration.nix
|
|
||||||
|
|
||||||
{ pkgs, lib, ... }:
|
|
||||||
|
|
||||||
{
|
|
||||||
networking.hostName = "its-a-me";
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
And then let's add [dwm][dwm] as the window manager. This setup will be a little
|
|
||||||
bit more complicated because we are going to need to add a custom configuration
|
|
||||||
as well as a patch to the source code for auto-starting Super Mario 64. Create a
|
|
||||||
folder called `dwm` and run the following commands in it to download the config
|
|
||||||
we need and the autostart patch:
|
|
||||||
|
|
||||||
[dwm]: https://dwm.suckless.org/
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ mkdir dwm
|
|
||||||
$ cd dwm
|
|
||||||
$ wget -O autostart.patch https://dwm.suckless.org/patches/autostart/dwm-autostart-20161205-bb3bd6f.diff
|
|
||||||
$ wget -O config.h https://gist.githubusercontent.com/Xe/f5fae8b7a0d996610707189d2133041f/raw/7043ca2ab5f8cf9d986aaa79c5c505841945766c/dwm_config.h
|
|
||||||
```
|
|
||||||
|
|
||||||
And then add the following before the opening curly brace:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
|
|
||||||
{ pkgs, lib, ... }:
|
|
||||||
|
|
||||||
let
|
|
||||||
dwm = with pkgs;
|
|
||||||
let name = "dwm-6.2";
|
|
||||||
in stdenv.mkDerivation {
|
|
||||||
inherit name;
|
|
||||||
|
|
||||||
src = fetchurl {
|
|
||||||
url = "https://dl.suckless.org/dwm/${name}.tar.gz";
|
|
||||||
sha256 = "03hirnj8saxnsfqiszwl2ds7p0avg20izv9vdqyambks00p2x44p";
|
|
||||||
};
|
|
||||||
|
|
||||||
buildInputs = with pkgs; [ xorg.libX11 xorg.libXinerama xorg.libXft ];
|
|
||||||
|
|
||||||
prePatch = ''sed -i "s@/usr/local@$out@" config.mk'';
|
|
||||||
|
|
||||||
postPatch = ''
|
|
||||||
cp ${./dwm/config.h} ./config.h
|
|
||||||
'';
|
|
||||||
|
|
||||||
patches = [ ./dwm/autostart.patch ];
|
|
||||||
|
|
||||||
buildPhase = " make ";
|
|
||||||
|
|
||||||
meta = {
|
|
||||||
homepage = "https://suckless.org/";
|
|
||||||
description = "Dynamic window manager for X";
|
|
||||||
license = stdenv.lib.licenses.mit;
|
|
||||||
maintainers = with stdenv.lib.maintainers; [ viric ];
|
|
||||||
platforms = with stdenv.lib.platforms; all;
|
|
||||||
};
|
|
||||||
};
|
|
||||||
in {
|
|
||||||
environment.systemPackages = with pkgs; [ hack-font st dwm ];
|
|
||||||
|
|
||||||
networking.hostName = "its-a-me";
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
Now let's create the mario user:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
{
|
|
||||||
# ...
|
|
||||||
users.users.mario = { isNormalUser = true; };
|
|
||||||
|
|
||||||
system.activationScripts = {
|
|
||||||
base-dirs = {
|
|
||||||
text = ''
|
|
||||||
mkdir -p /nix/var/nix/profiles/per-user/mario
|
|
||||||
'';
|
|
||||||
deps = [ ];
|
|
||||||
};
|
|
||||||
};
|
|
||||||
|
|
||||||
services.xserver.windowManager.session = lib.singleton {
|
|
||||||
name = "dwm";
|
|
||||||
start = ''
|
|
||||||
${dwm}/bin/dwm &
|
|
||||||
waitPID=$!
|
|
||||||
'';
|
|
||||||
};
|
|
||||||
|
|
||||||
services.xserver.enable = true;
|
|
||||||
services.xserver.displayManager.defaultSession = "none+dwm";
|
|
||||||
services.xserver.displayManager.lightdm.enable = true;
|
|
||||||
services.xserver.displayManager.lightdm.autoLogin.enable = true;
|
|
||||||
services.xserver.displayManager.lightdm.autoLogin.user = "mario";
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
The autostart file is going to be located in `/home/mario/.dwm/autostart.sh`. We
|
|
||||||
could try and place it manually on the filesystem with a NixOS module, or we
|
|
||||||
could use [home-manager][hm] to do this for us. Let's have home-manager do this
|
|
||||||
for us. First, install home-manager:
|
|
||||||
|
|
||||||
[hm]: https://rycee.gitlab.io/home-manager/
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ nix-channel --add https://github.com/rycee/home-manager/archive/release-20.03.tar.gz home-manager
|
|
||||||
$ nix-channel --update
|
|
||||||
```
|
|
||||||
|
|
||||||
Then let's add home-manager to this config:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
{
|
|
||||||
# ...
|
|
||||||
|
|
||||||
imports = [ <home-manager/nixos> ];
|
|
||||||
|
|
||||||
home-manager.users.mario = { config, pkgs, ... }: {
|
|
||||||
home.file = {
|
|
||||||
".dwm/autostart.sh" = {
|
|
||||||
executable = true;
|
|
||||||
text = ''
|
|
||||||
#!/bin/sh
|
|
||||||
export LIBGL_ALWAYS_SOFTWARE=1 # will be relevant later
|
|
||||||
'';
|
|
||||||
};
|
|
||||||
};
|
|
||||||
};
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
Now, for the creme de la creme of this project, let's build Super Mario 64. You
|
|
||||||
will need to get the base rom into your system's Nix store somehow. A half
|
|
||||||
decent way to do this is with [quickserv][quickserv]:
|
|
||||||
|
|
||||||
[quickserv]: https://tulpa.dev/Xe/quickserv
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ nix-env -if https://tulpa.dev/Xe/quickserv/archive/master.tar.gz
|
|
||||||
$ cd /path/to/folder/with/baserom.us.z64
|
|
||||||
$ quickserv -dir . -port 9001 &
|
|
||||||
$ nix-prefetch-url http://127.0.0.1:9001/baserom.us.z64
|
|
||||||
```
|
|
||||||
|
|
||||||
This will pre-populate your Nix store with the rom and should return the
|
|
||||||
following hash:
|
|
||||||
|
|
||||||
```
|
|
||||||
148xna5lq2s93zm0mi2pmb98qb5n9ad6sv9dky63y4y68drhgkhp
|
|
||||||
```
|
|
||||||
|
|
||||||
If this hash is wrong, then you need to find the correct rom. I cannot help you
|
|
||||||
with this.
|
|
||||||
|
|
||||||
Now, let's create a simple derivation for the Super Mario 64 PC port. I have a
|
|
||||||
tweaked version that is optimized for NixOS, which we will use for this. Add the
|
|
||||||
following between the `dwm` package define and the `in` statement:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
# ...
|
|
||||||
sm64pc = with pkgs;
|
|
||||||
let
|
|
||||||
baserom = fetchurl {
|
|
||||||
url = "http://127.0.0.1:9001/baserom.us.z64";
|
|
||||||
sha256 = "148xna5lq2s93zm0mi2pmb98qb5n9ad6sv9dky63y4y68drhgkhp";
|
|
||||||
};
|
|
||||||
in stdenv.mkDerivation rec {
|
|
||||||
pname = "sm64pc";
|
|
||||||
version = "latest";
|
|
||||||
|
|
||||||
buildInputs = [
|
|
||||||
gnumake
|
|
||||||
python3
|
|
||||||
audiofile
|
|
||||||
pkg-config
|
|
||||||
SDL2
|
|
||||||
libusb1
|
|
||||||
glfw3
|
|
||||||
libgcc
|
|
||||||
xorg.libX11
|
|
||||||
xorg.libXrandr
|
|
||||||
libpulseaudio
|
|
||||||
alsaLib
|
|
||||||
glfw
|
|
||||||
libGL
|
|
||||||
unixtools.hexdump
|
|
||||||
];
|
|
||||||
|
|
||||||
src = fetchgit {
|
|
||||||
url = "https://tulpa.dev/saved/sm64pc";
|
|
||||||
rev = "c69c75bf9beed9c7f7c8e9612e5e351855065120";
|
|
||||||
sha256 = "148pk9iqpcgzwnxlcciqz0ngy6vsvxiv5lp17qg0bs7ph8ly3k4l";
|
|
||||||
};
|
|
||||||
|
|
||||||
buildPhase = ''
|
|
||||||
chmod +x ./extract_assets.py
|
|
||||||
cp ${baserom} ./baserom.us.z64
|
|
||||||
make
|
|
||||||
'';
|
|
||||||
|
|
||||||
installPhase = ''
|
|
||||||
mkdir -p $out/bin
|
|
||||||
cp ./build/us_pc/sm64.us.f3dex2e $out/bin/sm64pc
|
|
||||||
'';
|
|
||||||
|
|
||||||
meta = with stdenv.lib; {
|
|
||||||
description = "Super Mario 64 PC port, requires rom :)";
|
|
||||||
};
|
|
||||||
};
|
|
||||||
# ...
|
|
||||||
```
|
|
||||||
|
|
||||||
And then add `sm64pc` to the system packages:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
{
|
|
||||||
# ...
|
|
||||||
environment.systemPackages = with pkgs; [ st hack-font dwm sm64pc ];
|
|
||||||
# ...
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
As well as to the autostart script from before:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
{
|
|
||||||
# ...
|
|
||||||
home-manager.users.mario = { config, pkgs, ... }: {
|
|
||||||
home.file = {
|
|
||||||
".dwm/autostart.sh" = {
|
|
||||||
executable = true;
|
|
||||||
text = ''
|
|
||||||
#!/bin/sh
|
|
||||||
export LIBGL_ALWAYS_SOFTWARE=1
|
|
||||||
${sm64pc}/bin/sm64pc
|
|
||||||
'';
|
|
||||||
};
|
|
||||||
};
|
|
||||||
};
|
|
||||||
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
Finally let's enable some hardware support so it's easier to play this bootable
|
|
||||||
game:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
{
|
|
||||||
# ...
|
|
||||||
|
|
||||||
hardware.pulseaudio.enable = true;
|
|
||||||
virtualisation.virtualbox.guest.enable = true;
|
|
||||||
virtualisation.vmware.guest.enable = true;
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
Altogether you should have a `configuration.nix` that looks like
|
|
||||||
[this][confignix].
|
|
||||||
|
|
||||||
[confignix]: https://gist.github.com/Xe/935920193cfac70c718b657a088f3417#file-configuration-nix
|
|
||||||
|
|
||||||
So let's build the ISO!
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ nixos-generate -f iso -c configuration.nix
|
|
||||||
```
|
|
||||||
|
|
||||||
Much output later, you will end up with a path that will look something like
|
|
||||||
this:
|
|
||||||
|
|
||||||
```
|
|
||||||
/nix/store/fzk3psrd3m6x437m6xh9pc7bnv2v44ax-nixos.iso/iso/nixos.iso
|
|
||||||
```
|
|
||||||
|
|
||||||
This is your bootable image of Super Mario 64. Copy it to a good temporary
|
|
||||||
folder (like your downloads folder):
|
|
||||||
|
|
||||||
```console
|
|
||||||
cp /nix/store/fzk3psrd3m6x437m6xh9pc7bnv2v44ax-nixos.iso/iso/nixos.iso ~/Downloads/mario64.iso
|
|
||||||
```
|
|
||||||
|
|
||||||
Now you are free to do whatever you want with this, including [booting it in a
|
|
||||||
virtual machine][bootinvmmp4].
|
|
||||||
|
|
||||||
[bootinvmmp4]: /static/blog/boot2mario.mp4
|
|
||||||
|
|
||||||
This is why I use NixOS. It enables me to do absolutely crazy things like
|
|
||||||
creating a bootable ISO of Super Mario 64 without having to understand how to
|
|
||||||
create ISO files by hand or how bootloaders on Linux work in ISO files.
|
|
||||||
|
|
||||||
It Just Works.
|
|
||||||
|
|
@ -111,23 +111,33 @@ Make sure to remove the TempleOS live CD from your hardware or it will be booted
|
||||||
|
|
||||||
The [TempleOS Bootloader](https://github.com/Xe/TempleOS/blob/1dd8859b7803355f41d75222d01ed42d5dda057f/Adam/Opt/Boot/BootMHDIns.HC#L69) presents a helpful menu to let you choose if you want to boot from a copy of the old boot record (preserved at install time), drive C or drive D. Press 1:
|
The [TempleOS Bootloader](https://github.com/Xe/TempleOS/blob/1dd8859b7803355f41d75222d01ed42d5dda057f/Adam/Opt/Boot/BootMHDIns.HC#L69) presents a helpful menu to let you choose if you want to boot from a copy of the old boot record (preserved at install time), drive C or drive D. Press 1:
|
||||||
|
|
||||||
|
<center>
|
||||||

|

|
||||||
|
</center>
|
||||||
|
|
||||||
The first boot requires the dictionary to be uncompressed as well as other housekeeping chores, so let it do its thing:
|
The first boot requires the dictionary to be uncompressed as well as other housekeeping chores, so let it do its thing:
|
||||||
|
|
||||||
|
<center>
|
||||||

|

|
||||||
|
</center>
|
||||||
|
|
||||||
Once it is done, you will see if the option to take the tour. I highly suggest going through this tour, but that is beyond the scope of this article, so we'll assume you pressed `n`:
|
Once it is done, you will see if the option to take the tour. I highly suggest going through this tour, but that is beyond the scope of this article, so we'll assume you pressed `n`:
|
||||||
|
|
||||||
|
<center>
|
||||||

|

|
||||||
|
</center>
|
||||||
|
|
||||||
### Using the Compiler
|
### Using the Compiler
|
||||||
|
|
||||||
|
<center>
|
||||||

|

|
||||||
|
</center>
|
||||||
|
|
||||||
The "shell" is itself an interface to the HolyC (similar to C) compiler. There is no difference between a "shell" REPL and a HolyC repl. This is stupidly powerful:
|
The "shell" is itself an interface to the HolyC (similar to C) compiler. There is no difference between a "shell" REPL and a HolyC repl. This is stupidly powerful:
|
||||||
|
|
||||||
|
<center>
|
||||||

|

|
||||||
|
</center>
|
||||||
|
|
||||||
```
|
```
|
||||||
"Hello, world\n";
|
"Hello, world\n";
|
||||||
|
|
@ -137,25 +147,37 @@ Let's make this into a "program" and disassemble it. This is way easier than it
|
||||||
|
|
||||||
Open a new file with `Ed("HelloWorld.HC");` (the semicolon is important):
|
Open a new file with `Ed("HelloWorld.HC");` (the semicolon is important):
|
||||||
|
|
||||||
|
<center>
|
||||||

|

|
||||||
|
</center>
|
||||||
|
|
||||||
|
<center>
|
||||||

|

|
||||||
|
</center>
|
||||||
|
|
||||||
Now press Alt-Shift-a to kill autocomplete:
|
Now press Alt-Shift-a to kill autocomplete:
|
||||||
|
|
||||||
|
<center>
|
||||||

|

|
||||||
|
</center>
|
||||||
|
|
||||||
Click the `X` in the upper right-hand corner to close the other shell window:
|
Click the `X` in the upper right-hand corner to close the other shell window:
|
||||||
|
|
||||||
|
<center>
|
||||||

|

|
||||||
|
</center>
|
||||||
|
|
||||||
Finally press drag the right side of the window to maximize the editor pane:
|
Finally press drag the right side of the window to maximize the editor pane:
|
||||||
|
|
||||||
|
<center>
|
||||||

|

|
||||||
|
</center>
|
||||||
|
|
||||||
Let's put the hello word example into the program and press `F5` to run it:
|
Let's put the hello word example into the program and press `F5` to run it:
|
||||||
|
|
||||||
|
<center>
|
||||||

|

|
||||||
|
</center>
|
||||||
|
|
||||||
Neat! Close that shell window that just popped up. Let's put this hello world code into a function:
|
Neat! Close that shell window that just popped up. Let's put this hello world code into a function:
|
||||||
|
|
||||||
|
|
@ -169,7 +191,9 @@ HelloWorld;
|
||||||
|
|
||||||
Now press `F5` again:
|
Now press `F5` again:
|
||||||
|
|
||||||
|
<center>
|
||||||

|

|
||||||
|
</center>
|
||||||
|
|
||||||
Let's disassemble it:
|
Let's disassemble it:
|
||||||
|
|
||||||
|
|
@ -181,7 +205,9 @@ U0 HelloWorld() {
|
||||||
Uf("HelloWorld");
|
Uf("HelloWorld");
|
||||||
```
|
```
|
||||||
|
|
||||||
|
<center>
|
||||||

|

|
||||||
|
</center>
|
||||||
|
|
||||||
The `Uf` function also works with anything else, including things like the editor:
|
The `Uf` function also works with anything else, including things like the editor:
|
||||||
|
|
||||||
|
|
@ -189,11 +215,15 @@ The `Uf` function also works with anything else, including things like the edito
|
||||||
Uf("Ed");
|
Uf("Ed");
|
||||||
```
|
```
|
||||||
|
|
||||||
|
<center>
|
||||||

|

|
||||||
|
</center>
|
||||||
|
|
||||||
All of the red underscored things that look like links actually are links to the source code of functions. While the HolyC compiler builds things, it internally keeps a sourcemap (much like webapp sourcemaps or how gcc relates errors at runtime to lines of code for the developer) of all of the functions it compiles. Let's look at the definition of `Free()`:
|
All of the red underscored things that look like links actually are links to the source code of functions. While the HolyC compiler builds things, it internally keeps a sourcemap (much like webapp sourcemaps or how gcc relates errors at runtime to lines of code for the developer) of all of the functions it compiles. Let's look at the definition of `Free()`:
|
||||||
|
|
||||||
|
<center>
|
||||||

|

|
||||||
|
</center>
|
||||||
|
|
||||||
And from here you can dig deeper into the kernel source code.
|
And from here you can dig deeper into the kernel source code.
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -1,338 +0,0 @@
|
||||||
---
|
|
||||||
title: "The Dwarven Cavern - A Beginner 6E Adventure"
|
|
||||||
date: 2020-06-28
|
|
||||||
series: thesource
|
|
||||||
tags:
|
|
||||||
- 6e
|
|
||||||
---
|
|
||||||
|
|
||||||
# The Dwarven Cavern - A Beginner 6E Adventure
|
|
||||||
|
|
||||||
Recently itch.io had [one of the largest game bundles in history][itchbundle]
|
|
||||||
and one of the things in it was this humble game named [6E][6e]. Some friends
|
|
||||||
and I have started up a small group that meets on the weekends to spend a few
|
|
||||||
hours with an adventure. I've been writing a few adventures for them, and I
|
|
||||||
would like to start sharing their archetypes. These will all be included in a
|
|
||||||
small zine that describes the systems we have built on top of 6E that I'm
|
|
||||||
calling [The Source](https://www.patreon.com/posts/source-v0-1-38587786). This
|
|
||||||
PDF will be available publicly once it is closer to done (however if you really
|
|
||||||
want a copy early on to dig at it, let me know and we can surely work something
|
|
||||||
out).
|
|
||||||
|
|
||||||
[itchbundle]: https://itch.io/b/520/bundle-for-racial-justice-and-equality
|
|
||||||
[6e]: https://s-jared.itch.io/6e
|
|
||||||
|
|
||||||
Today, I would like to share the details that went into writing the most recent
|
|
||||||
adventure: The Dwarven Cavern. This was derived from One Page Dungeons by
|
|
||||||
[Geoffrey Cullop](https://twitter.com/cullopgeoffrey), specifically this is a
|
|
||||||
variant of Kobold Caverns on page 5. Please note that the experience, gold and
|
|
||||||
hitpoints of enemies are balanced for the group I play with, and will probably
|
|
||||||
need to be adjusted for other parties of adventurers. This should work for
|
|
||||||
players at level 1-3. By the end they should gain enough experience to level up
|
|
||||||
once. My group is also very stun-heavy, so that makes my job of attempting to
|
|
||||||
balance things really interesting.
|
|
||||||
|
|
||||||
Like most great adventures, this starts at a humble tavern, The Flying
|
|
||||||
Ombudsman.
|
|
||||||
|
|
||||||
## The Flying Ombudsman
|
|
||||||
|
|
||||||
The players start off in The Flying Ombudsman, a tavern in the town of
|
|
||||||
LAST\_TOWN\_YOUR\_PLAYERS\_WERE\_IN. There are a few people sitting at the bar
|
|
||||||
and drinking steamy mugs of grog. There is a salesperson sitting at one of the
|
|
||||||
tables fidgeting with a golden scepter head and looks like she has plenty of
|
|
||||||
items should people want them. There is someone rather sad sitting at another of
|
|
||||||
the tables, looking like he has suffered a great loss.
|
|
||||||
|
|
||||||
For extra immersion, have the NPC's speak with a slightly Irish accent. For
|
|
||||||
extra fun, throw in random words from scottish, english and australian accents.
|
|
||||||
Keeps the players thinking.
|
|
||||||
|
|
||||||
When players ask the bartender for a mug o' grog, he will sell them one for 5
|
|
||||||
gold (limit 4 each player). If players ask for the history behind the name,
|
|
||||||
explain to the players the information in The Story of Hol below.
|
|
||||||
|
|
||||||
The salesperson at the top sells the following:
|
|
||||||
|
|
||||||
| Name | Effect | Price |
|
|
||||||
| :---------------------- | :--------------------------------------------------------------- | :------- |
|
|
||||||
| 3x potion of cure poison | Cures poison and grants 2hp | 15g each |
|
|
||||||
| Golden Scepter head | Doesn't look like it does anything if it's not on top of a staff | 50g |
|
|
||||||
|
|
||||||
You may want to add a few more items to this list. I need to draw up a table
|
|
||||||
for items that salespeople like this can have.
|
|
||||||
|
|
||||||
The salesperson can also get you a room at the inn for 30g. It is big enough to
|
|
||||||
hold all of the party.
|
|
||||||
|
|
||||||
When players talk to the person at the bottom, they get a sad story about the
|
|
||||||
hoe-pocalypse that threatens the end of the village the person comes from.
|
|
||||||
Dwarves snuck up from underground and stole the hoe from him, making it
|
|
||||||
difficult to feed his hamlet. He asks the adventurers to go to the cavern the
|
|
||||||
dwarves live in and get them back. The players should eventually agree to do it,
|
|
||||||
and the NPC will progressively offer more and more gold as a reward. A charisma
|
|
||||||
check will get him to throw in some salted meat as a reward.
|
|
||||||
|
|
||||||
### The Story of Hol
|
|
||||||
|
|
||||||
The bartender previously ran a failing tavern, and was running out of hope and
|
|
||||||
money. One day, the bartender found a weird looking mug and found that it could
|
|
||||||
be used to talk with the gods. He eventually found a god named Hol. Hol offered
|
|
||||||
him the recipe for the strongest alcohol he could possibly make, for a price.
|
|
||||||
The bartender agreed without further thought and gained the ability to make
|
|
||||||
intensely strong alcohol, but lost his ability to negotiate permanently.
|
|
||||||
|
|
||||||
One day the local ombudsman got news of how strong the liquor was and decided to
|
|
||||||
enforce some obscure liquor control law to get the strength reduced. The bartender
|
|
||||||
refused to negotiate and it escalated into a situation where the bartender kicked
|
|
||||||
the ombudsman so hard that he flew into the wall. People started calling the
|
|
||||||
tavern "the place where the ombudsman flew" and that eventually evolved into the
|
|
||||||
name The Flying Ombudsman.
|
|
||||||
|
|
||||||
Business has been booming ever since.
|
|
||||||
|
|
||||||
## The Cave
|
|
||||||
|
|
||||||
The first part has 1 mechanical trap around the second corner, players will need
|
|
||||||
to work their way through it with low light or to grab a working torch off the
|
|
||||||
wall. The trap does 1d4 damage.
|
|
||||||
|
|
||||||
The tunnel opens into a guard station, the dwarf archers wait behind cover for
|
|
||||||
players to get in range of their shortbows. If they get within 10 feet of the
|
|
||||||
archers, they fall back to the room behind them to the left. The Archers have 6
|
|
||||||
hp and grant 100xp on defeat.
|
|
||||||
|
|
||||||
The room behind and to the left is a labratory that is very well-lit. Lots of
|
|
||||||
weird liquid in flasks, scientific equipment, etc. There is a Dwarf Grenadier
|
|
||||||
there and will attack you on sight. He throws alchemical grenades at range (1d6
|
|
||||||
damage, =6 -> random elemental effect), If the players get within melee range of
|
|
||||||
the Grenadier then he will use a poisoned dagger. If the guards retreated then
|
|
||||||
he will use them as meat shields. He has 25 hp. He drops 1d4 alchemical grenades
|
|
||||||
and also drops his poisoned dagger. He grants 300xp on defeat.
|
|
||||||
|
|
||||||
The bigger chamber is the dwarven living area. Plenty of beds to hide behind,
|
|
||||||
but there are 1d6 dwarves living in there. They attack on sight, but flee south
|
|
||||||
if their attack goes poorly. The dwarves each grant 100xp on defeat. There is a
|
|
||||||
chest in there that is actually a mimic. It drops an Amulet of Chest on defeat.
|
|
||||||
|
|
||||||
The room south is the home of Bubba the Bugbear, a hired goon of the dwarves.
|
|
||||||
Bubba and the remaining dwarves make their last stand here. Bubba grants 500xp
|
|
||||||
on defeat and has 30hp and 1d6+2 attack damage with his giant club.
|
|
||||||
|
|
||||||
The final room is the treasure room, which contains the stolen hoe, some other
|
|
||||||
farming equipment and 250 gold. After this the dungeon is cleared and players
|
|
||||||
gain experience from their journey, then go back to The Flying Ombudsman
|
|
||||||
victorious. The quest NPC will award them with however many gold they agreed to
|
|
||||||
and any items they also agreed to.
|
|
||||||
|
|
||||||
## Enemies
|
|
||||||
|
|
||||||
### Dwarf Archer
|
|
||||||
*Decent guard, horrible foresight*
|
|
||||||
|
|
||||||
- **Hit Points** 6
|
|
||||||
|
|
||||||
| STR | DEX | CON | INT | WIS | CHA |
|
|
||||||
| :---: | :---: | :---: | :---: | :---: | :---: |
|
|
||||||
| 0 | +1 | 0 | -2 | -2 | 0 |
|
|
||||||
|
|
||||||
- **Condition Immunities** drunk, groggy
|
|
||||||
- **Senses** Night-vision
|
|
||||||
- **Languages** Dwarf
|
|
||||||
- **Challenge** 2 (100xp)
|
|
||||||
|
|
||||||
***Keep-away.*** Will flee at the first sign of trouble.
|
|
||||||
|
|
||||||
#### Actions
|
|
||||||
***Crossbow.*** *Ranged Attack:* 1d4 damage
|
|
||||||
|
|
||||||
### Dwarf Grenadier
|
|
||||||
*Mad scientist, crazier inventions*
|
|
||||||
|
|
||||||
- **Hit Points** 25
|
|
||||||
|
|
||||||
| STR | DEX | CON | INT | WIS | CHA |
|
|
||||||
| :---: | :---: | :---: | :---: | :---: | :---: |
|
|
||||||
| 0 | +1 | -2 | +2 | 0 | +1 |
|
|
||||||
|
|
||||||
- **Condition Immunities** drunk, groggy
|
|
||||||
- **Senses** Night-vision
|
|
||||||
- **Languages** Dwarf
|
|
||||||
- **Challenge** 6 (300xp)
|
|
||||||
|
|
||||||
***Insane.*** Will do things that normal enemies would not.
|
|
||||||
|
|
||||||
#### Actions
|
|
||||||
***Alchemical Grenade.*** *Ranged Attack:* 1d6 damage plus elemental effect if
|
|
||||||
6 damage. See table for Alchemical Grenades.
|
|
||||||
|
|
||||||
***Poisoned Dagger.*** *Melee Attack:* 1d4 damage. On hit player must roll for
|
|
||||||
constitution. If the check fails they get _disadvantage_ for their throws the
|
|
||||||
next 1d3 turns.
|
|
||||||
|
|
||||||
### Dwarf
|
|
||||||
*Underground folk that love digging*
|
|
||||||
|
|
||||||
**Hit Points** 6
|
|
||||||
|
|
||||||
| STR | DEX | CON | INT | WIS | CHA |
|
|
||||||
| :---: | :---: | :---: | :---: | :---: | :---: |
|
|
||||||
| 0 | +1 | 0 | -2 | -2 | 0 |
|
|
||||||
|
|
||||||
- **Condition Immunities** drunk, groggy
|
|
||||||
- **Senses** Night-vision
|
|
||||||
- **Languages** Dwarf
|
|
||||||
- **Challenge** 2 (100xp)
|
|
||||||
|
|
||||||
***Short and Stout.*** Easily able to hit enemies below the belt.
|
|
||||||
|
|
||||||
#### Actions
|
|
||||||
***Dagger.*** *Melee Attack:* 1d4 damage
|
|
||||||
|
|
||||||
### Mimic
|
|
||||||
*Just an ordinary chest, don't question it*
|
|
||||||
|
|
||||||
- **Hit Points** 14
|
|
||||||
|
|
||||||
| STR | DEX | CON | INT | WIS | CHA |
|
|
||||||
| :---: | :---: | :---: | :---: | :---: | :---: |
|
|
||||||
| 0 | 0 | -2 | 0 | 0 | -1 |
|
|
||||||
|
|
||||||
- **Condition Immunities** burn, poison
|
|
||||||
- **Languages** None
|
|
||||||
- **Challenge** 5 (250xp)
|
|
||||||
|
|
||||||
***Unsuspicious.*** Come on, the chest wouldn't be alive, would it?
|
|
||||||
|
|
||||||
#### Actions
|
|
||||||
***Omnomnom*** *Melee Attack:* 1d6 piercing damage, gets advantage if the player
|
|
||||||
tries to open the chest.
|
|
||||||
|
|
||||||
### Bubba the Bugbear
|
|
||||||
|
|
||||||
*From Bubba with Love*
|
|
||||||
|
|
||||||
- **Hit Points** 30
|
|
||||||
|
|
||||||
| STR | DEX | CON | INT | WIS | CHA |
|
|
||||||
| :---: | :---: | :---: | :---: | :---: | :---: |
|
|
||||||
| +2 | +2 | +1 | -2 | 0 | -1 |
|
|
||||||
|
|
||||||
- **Condition Immunities** blinded
|
|
||||||
- **Languages** Dwarf
|
|
||||||
- **Challenge** 10 (500xp)
|
|
||||||
|
|
||||||
***Unreasonable.*** Does not respond well to trickery.
|
|
||||||
|
|
||||||
#### Actions
|
|
||||||
***Whomp.*** *Melee Attack:* 1d6+2 damage, piercing if the player fails a
|
|
||||||
constitution check.
|
|
||||||
|
|
||||||
## Items
|
|
||||||
|
|
||||||
These are the unique items specific to this quest.
|
|
||||||
|
|
||||||
### Mug of Grog
|
|
||||||
|
|
||||||
A wooden/iron mug full of the barkeep's grog. Consuming it gives you the
|
|
||||||
following stat boosts for 3 turns:
|
|
||||||
|
|
||||||
| STR | DEX | CON | INT | WIS | CHA |
|
|
||||||
| :---: | :---: | :---: | :---: | :---: | :---: |
|
|
||||||
| +0 | -1 | +0 | -1 | -1 | +3 |
|
|
||||||
|
|
||||||
This bonus does not stack. When you drink the grog, you keep the mug and can use
|
|
||||||
it to bludgeon people for normal attack damage. It can also be used as a tool to
|
|
||||||
check for traps.
|
|
||||||
|
|
||||||
Does not sell, purchasable for 5g.
|
|
||||||
|
|
||||||
### Golden Scepter Head
|
|
||||||
|
|
||||||
A golden scepter head that looks like The Grand Nagus from Star Trek. It has no
|
|
||||||
effect outside of when it's put on a staff. When it is on a staff it gives you
|
|
||||||
25% more gold when you collect gold from places. This has 5 charges and cannot
|
|
||||||
be refreshed.
|
|
||||||
|
|
||||||
Sells for 50g, purchases for 50g.
|
|
||||||
|
|
||||||
### Alchemical Grenades
|
|
||||||
|
|
||||||
Standard grenades that look like they are made out of wood, metal, insanity and
|
|
||||||
magic. They do d6 damage normally, but when you crit with one it also causes one
|
|
||||||
of the following status effects (roll a d4):
|
|
||||||
|
|
||||||
|
|
||||||
#### Alchemical Effects
|
|
||||||
|
|
||||||
| Roll | Effect |
|
|
||||||
| :----: | :------------- |
|
|
||||||
| 1 | Acid makes the entity take off their armor |
|
|
||||||
| 2 | The entity rolls a constitution check, if it fails they get poisoned and need to roll for constitution before every action, passing removes the poison, failing makes them not have any action. |
|
|
||||||
| 3 | The entity is burned for 1d4 damage every turn they fail a constitution check. |
|
|
||||||
| 4 | The entity is stunned for 1d3 turns. |
|
|
||||||
|
|
||||||
Sells for 25g each, unpurchaseable.
|
|
||||||
|
|
||||||
### Poisoned Dagger
|
|
||||||
|
|
||||||
A standard dagger that gives no distinct bonuses. However when you use it as a
|
|
||||||
normal dagger, you need to roll for constitution in addition to rolling for
|
|
||||||
strength. If you fail the constitution check (but pass the strength check), you
|
|
||||||
get poisoned from the poison streaking out of the dagger.
|
|
||||||
|
|
||||||
The poison has 5 charges.
|
|
||||||
|
|
||||||
Merchants do not want to take the risk buying it and will have you pay them for its
|
|
||||||
disposal. This cannot be purchased.
|
|
||||||
|
|
||||||
### Bubba's Clubba
|
|
||||||
|
|
||||||
A rather large mace that does +2 damage. It is a giant thing designed for a
|
|
||||||
9-foot tall centaur. It takes up three slots in your inventory. It looks
|
|
||||||
imposing and may require a lot of strength to use properly.
|
|
||||||
|
|
||||||
Sells for 25g.
|
|
||||||
|
|
||||||
### Amulet of Chest
|
|
||||||
|
|
||||||
This cursed amulet lets the holder transform into a harmless looking treasure
|
|
||||||
chest, but also grants them advantage if an enemy tries to open it. After 4
|
|
||||||
transformations, they need to roll a charisma check when they try to turn back.
|
|
||||||
If that fails, they stay a chest for an hour (with arms/legs/a mouth/etc). After
|
|
||||||
4 more transformations, they turn into a mimic permanently. The transformation
|
|
||||||
count stays persistent until someone becomes a mimic, then it resets to zero.
|
|
||||||
|
|
||||||
Merchants will pay 100 gold for it, but will only accept it after the player
|
|
||||||
rolls for charisma.
|
|
||||||
|
|
||||||
## Dungeon Map
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
## Adventure Highlights
|
|
||||||
|
|
||||||
When I ran this yesterday, the following amazing things happened:
|
|
||||||
|
|
||||||
- The players used a crossbow from a previous adventure and a torch to hit the
|
|
||||||
grenades held by the grenadier, vaporizing it from 5 grenades exploding at once.
|
|
||||||
- The Artificer shield-bashed one of the dwarves so hard that it ricocheted into
|
|
||||||
the other dwarves like pool balls. That caused a lot of damage to all of the
|
|
||||||
enemies.
|
|
||||||
- The Monk critted a Ki art and shredded an archer with their claws, making the
|
|
||||||
other archer flee.
|
|
||||||
- The Thief straight up banished a dwarf to the shadow realm with a slingshot
|
|
||||||
hit.
|
|
||||||
|
|
||||||
I still wonder how they are going to use that Cursed Amulet of Chest though.
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
Thank you [@infinite_mao](https://twitter.com/infinite_mao) for making 6E. I can
|
|
||||||
only hope that my buying your stuff separately and making this content for 6E
|
|
||||||
can help give back to the community.
|
|
||||||
|
|
||||||
Feedback on the balance of this is very welcome. I openly welcome any and all
|
|
||||||
feedback about how this quest could be rebalanced to be a bit less lopsided in
|
|
||||||
favor of the players. I also wanted to err on the side of balancing towards the
|
|
||||||
players to avoid an unwanted party death.
|
|
||||||
|
|
@ -1,58 +0,0 @@
|
||||||
---
|
|
||||||
title: The Itch
|
|
||||||
date: 2020-10-11
|
|
||||||
tags:
|
|
||||||
- 100DaysToOffload
|
|
||||||
---
|
|
||||||
|
|
||||||
# The Itch
|
|
||||||
|
|
||||||
I write a lot. I code a lot. This leads to people asking me questions like "how
|
|
||||||
do you have the energy to do that?" or "why do you keep doing that day in and
|
|
||||||
day out?". I was reading [this
|
|
||||||
post](https://aarontag.dev/2020/06/14/the-urge.html) that I found linked in the
|
|
||||||
Forbidden Orange Site's comments and it really resonated with me.
|
|
||||||
|
|
||||||
At the core, I have this deep burning sensation to try things out to see what
|
|
||||||
they are like. It's like this itch deep in me that I can only scratch with
|
|
||||||
writing, coding or sometimes even just answering people's questions in
|
|
||||||
chatrooms. This itch is a catalyst to my productivity. It powers my daily work
|
|
||||||
and makes me able to do what I do in order to make things better for everyone.
|
|
||||||
|
|
||||||
However, sometimes the itch isn't there. Sometimes it makes me want to focus on
|
|
||||||
something else. Trying to do something else without the itch empowering me can
|
|
||||||
feel like swimming upstream with heavy chains wrapped around me. My greatest
|
|
||||||
boon is simultaneously my greatest vice.
|
|
||||||
|
|
||||||
I don't really know how to handle the days where it's not working. I try to save
|
|
||||||
up my sick and vacation days so that I can avoid burning myself out on the bad
|
|
||||||
days. Things like this are why I am a huge fan of unlimited vacation policies.
|
|
||||||
Unlimited vacation does mean that I get paid out less money when I leave a job;
|
|
||||||
however it means that I have the freedom to have bad days and let the good days
|
|
||||||
tank me through the bad days so that I come out above average.
|
|
||||||
|
|
||||||
Trying to explain this to people can feel stressful. Especially to a manager.
|
|
||||||
I've had some bad experiences with that in the past. Phrase this wrong, and some
|
|
||||||
people will hear "I don't want to do this work ever" instead of "I can't do this
|
|
||||||
work today". This especially sucks when deadlines roll in and that vital itch
|
|
||||||
goes away, leaving me at half capacity at the worst possible time.
|
|
||||||
|
|
||||||
This itch leads me to set increasing standards on myself too. It's had some
|
|
||||||
negative sides in that it makes me feel like I need to make everything better
|
|
||||||
than the last thing. Each post better than the previous ones. Each project
|
|
||||||
implementation better than the last. Onwards and onwards into a spiral that sets
|
|
||||||
the bar so high I stress myself out trying to approach it.
|
|
||||||
|
|
||||||
I haven't kept to my informal goal to have at least one post per week on this
|
|
||||||
blog because of that absurdly high standard I set for myself. I'm going to try
|
|
||||||
and change this. I'm going to start participating in [100 days to
|
|
||||||
offload](https://100daystooffload.com). Expect some shorter and more focused
|
|
||||||
posts for the immediate future. I am going to be working on the Rust series,
|
|
||||||
however each part of it will be in isolation from here on out instead of the
|
|
||||||
longer multifaceted posts.
|
|
||||||
|
|
||||||
This is day 1 of my 100 days to offload.
|
|
||||||
|
|
||||||
Also be sure to check out my post on
|
|
||||||
[Palisade](https://tech.lightspeedhq.com/palisade-version-bumping-at-scale-in-ci/),
|
|
||||||
a version bumping tool for GitHub repositories.
|
|
||||||
|
|
@ -1,24 +0,0 @@
|
||||||
---
|
|
||||||
title: The Source Version 1.0.0 Release
|
|
||||||
date: 2020-12-25
|
|
||||||
tags:
|
|
||||||
- ttrpg
|
|
||||||
---
|
|
||||||
|
|
||||||
# The Source Version 1.0.0 Release
|
|
||||||
|
|
||||||
After hours of work and adjustment, I have finally finished version 1 of my
|
|
||||||
tabletop roleplaying game The Source. It is available on
|
|
||||||
[itch.io](https://withinstudios.itch.io/q7rvfw33fw) with an added 50% discount
|
|
||||||
for readers of my blog. This discount will only last for the next two weeks.
|
|
||||||
|
|
||||||
<iframe src="https://itch.io/embed/866470?linkback=true" width="552"
|
|
||||||
height="167" frameborder="0"><a
|
|
||||||
href="https://withinstudios.itch.io/the-source">The Source by
|
|
||||||
Within</a></iframe>
|
|
||||||
|
|
||||||
Patrons (of any price tier) can claim a free copy
|
|
||||||
[here](https://withinstudios.itch.io/the-source/patreon-access). Your support
|
|
||||||
gives me so much.
|
|
||||||
|
|
||||||
Merry christmas all.
|
|
||||||
|
|
@ -1,250 +0,0 @@
|
||||||
---
|
|
||||||
title: Thoughts on Nix
|
|
||||||
date: 2020-01-28
|
|
||||||
tags:
|
|
||||||
- nix
|
|
||||||
- packaging
|
|
||||||
- dependencies
|
|
||||||
---
|
|
||||||
|
|
||||||
# Thoughts on Nix
|
|
||||||
|
|
||||||
EDIT(M02 20 2020): I've written a bit of a rebuttal to my own post
|
|
||||||
[here](https://christine.website/blog/i-was-wrong-about-nix-2020-02-10). I am
|
|
||||||
keeping this post up for posterity.
|
|
||||||
|
|
||||||
I don't really know how I feel about [Nix][nix]. It's a functional package
|
|
||||||
manager that's designed to help with dependency hell. It also lets you define
|
|
||||||
packages using [Nix][nixlang], which is an identically named yet separate thing.
|
|
||||||
Nix has _untyped_ expressions that help you build packages like this:
|
|
||||||
|
|
||||||
[nix]: https://nixos.org/nix/
|
|
||||||
[nixlang]: https://nixos.org/nix/manual/#chap-writing-nix-expressions
|
|
||||||
|
|
||||||
```nix
|
|
||||||
{ stdenv, fetchurl, perl }:
|
|
||||||
|
|
||||||
stdenv.mkDerivation {
|
|
||||||
name = "hello-2.1.1";
|
|
||||||
builder = ./builder.sh;
|
|
||||||
src = fetchurl {
|
|
||||||
url = ftp://ftp.nluug.nl/pub/gnu/hello/hello-2.1.1.tar.gz;
|
|
||||||
sha256 = "1md7jsfd8pa45z73bz1kszpp01yw6x5ljkjk2hx7wl800any6465";
|
|
||||||
};
|
|
||||||
inherit perl;
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
In theory, this is great. It's obvious what needs to be done to the system in
|
|
||||||
order for the "hello, world" package and what it depends on (in this case it
|
|
||||||
depends on only the standard environment because there's no additional
|
|
||||||
dependencies specified), to the point that this approach lets you avoid all
|
|
||||||
major forms of [DLL hell][dllhell], while at the same time creating its own form
|
|
||||||
of hell: [nixpkgs][nixpkgs], or the main package source of Nix.
|
|
||||||
|
|
||||||
[dllhell]: https://en.wikipedia.org/wiki/DLL_Hell
|
|
||||||
[nixpkgs]: https://nixos.org/nixpkgs/manual/
|
|
||||||
|
|
||||||
Now, you may ask, how do you get that hash? Try and build the package with an
|
|
||||||
obviously false hash and use the correct one from the output of the build
|
|
||||||
command! That seems safe!
|
|
||||||
|
|
||||||
Let's say you have a modern app that has dependencies with npm, Go and Elm.
|
|
||||||
Let's focus on the Go side for now. How would we do that when using Go modules?
|
|
||||||
|
|
||||||
```nix
|
|
||||||
{ pkgs ? import <nixpkgs> { } }:
|
|
||||||
let
|
|
||||||
x = buildGoModule rec {
|
|
||||||
name = "Xe-x-${version}";
|
|
||||||
version = "1.2.3";
|
|
||||||
|
|
||||||
src = fetchFromGitHub {
|
|
||||||
owner = "Xe";
|
|
||||||
repo = "x";
|
|
||||||
rev = "v${version}";
|
|
||||||
sha256 = "0m2fzpqxk7hrbxsgqplkg7h2p7gv6s1miymv3gvw0cz039skag0s";
|
|
||||||
};
|
|
||||||
|
|
||||||
modSha256 = "1879j77k96684wi554rkjxydrj8g3hpp0kvxz03sd8dmwr3lh83j";
|
|
||||||
|
|
||||||
subPackages = [ "." ];
|
|
||||||
}
|
|
||||||
|
|
||||||
in {
|
|
||||||
x = x;
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
And this will fetch and build [the entirety of my `x` repo][Xex] into a single
|
|
||||||
massive package that includes _everything_. Let's say I want to break it up into
|
|
||||||
multiple packages so that I can install only one or two parts of it, such as my
|
|
||||||
[`license`][Xelicense] command:
|
|
||||||
|
|
||||||
[Xex]: https://github.com/Xe/x
|
|
||||||
[Xelicense]: https://github.com/Xe/x/blob/master/cmd/license/main.go
|
|
||||||
|
|
||||||
Let's make a function called `gomod.nix` that includes everything to build the
|
|
||||||
go modules:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
# gomod.nix
|
|
||||||
pkgs: repo: modSha256: attrs:
|
|
||||||
with pkgs;
|
|
||||||
let defaultAttrs = {
|
|
||||||
src = repo;
|
|
||||||
modSha256 = modSha256;
|
|
||||||
};
|
|
||||||
|
|
||||||
in buildGoModule (defaultAttrs // attrs)
|
|
||||||
```
|
|
||||||
|
|
||||||
And then let's invoke this with a few of the commands in there:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
{ pkgs ? import <nixpkgs> { } }:
|
|
||||||
let
|
|
||||||
stdenv = pkgs.stdenv;
|
|
||||||
version = "1.2.3";
|
|
||||||
repo = pkgs.fetchFromGitHub {
|
|
||||||
owner = "Xe";
|
|
||||||
repo = "x";
|
|
||||||
rev = "v${version}";
|
|
||||||
sha256 = "0m2fzpqxk7hrbxsgqplkg7h2p7gv6s1miymv3gvw0cz039skag0s";
|
|
||||||
};
|
|
||||||
|
|
||||||
modSha256 = "1879j77k96684wi554rkjxydrj8g3hpp0kvxz03sd8dmwr3lh83j";
|
|
||||||
mk = import ./gomod.nix pkgs repo modSha256;
|
|
||||||
|
|
||||||
appsluggr = mk {
|
|
||||||
name = "appsluggr";
|
|
||||||
version = version;
|
|
||||||
subPackages = [ "cmd/appsluggr" ];
|
|
||||||
};
|
|
||||||
|
|
||||||
johaus = mk {
|
|
||||||
name = "johaus";
|
|
||||||
version = version;
|
|
||||||
subPackages = [ "cmd/johaus" ];
|
|
||||||
};
|
|
||||||
|
|
||||||
license = mk {
|
|
||||||
name = "license";
|
|
||||||
version = version;
|
|
||||||
subPackages = [ "cmd/license" ];
|
|
||||||
};
|
|
||||||
|
|
||||||
prefix = mk {
|
|
||||||
name = "prefix";
|
|
||||||
version = version;
|
|
||||||
subPackages = [ "cmd/prefix" ];
|
|
||||||
};
|
|
||||||
|
|
||||||
in {
|
|
||||||
appsluggr = appsluggr;
|
|
||||||
johaus = johaus;
|
|
||||||
license = license;
|
|
||||||
prefix = prefix;
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
And when we build this, we notice that ALL of the dependencies for my `x` repo
|
|
||||||
(at least a hundred because it's got a lot of stuff in there) are downloaded
|
|
||||||
_FOUR TIMES_, even though they don't change between them. I could avoid this by
|
|
||||||
making each dependency its own Nix package, but that's not a productive use of
|
|
||||||
my time.
|
|
||||||
|
|
||||||
Add on having to do this for the Node dependencies, and the Elm dependencies and
|
|
||||||
this is at least 200 if not more packages needed for my relatively simple CRUD
|
|
||||||
app that has creative choices in technology.
|
|
||||||
|
|
||||||
Oh, even better, the build directory isn't writable. So when your third-tier
|
|
||||||
dependency has a generation step that assumes the build directory is writable,
|
|
||||||
you suddenly need to become an expert in how that tool works so you can shunt it
|
|
||||||
writing its files to another place. And then you need to make sure those files
|
|
||||||
don't end up places they shouldn't be, lest you fill your disk with unneeded
|
|
||||||
duplicate node\_modules folders that really shouldn't be there in the first
|
|
||||||
place (but are there because you gave up).
|
|
||||||
|
|
||||||
Then you need to make sure that works on another machine, because even though
|
|
||||||
Nix itself is "functionally pure" (save the heat generated by the CPU executing
|
|
||||||
your cloud-native, multitenant parallel adding service) this is a PACKAGE
|
|
||||||
MANAGER. You know, the things that handle STATE, like FILES on the DISK. That's
|
|
||||||
STATE. GLOBALLY MUTABLE STATE.
|
|
||||||
|
|
||||||
One of the main advantages of this approach is that the library dependencies of
|
|
||||||
every project are easy to reproduce on other machines. Consider the
|
|
||||||
[`ldd(1)`][ldd1] (which shows the dynamic libraries associated with a program)
|
|
||||||
output of `ls` on my Ubuntu system vs a package I installed from Nix:
|
|
||||||
|
|
||||||
[ldd1]: http://man7.org/linux/man-pages/man1/ldd.1.html
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ ldd $(which ls)
|
|
||||||
linux-vdso.so.1 (0x00007ffd2a79f000)
|
|
||||||
libselinux.so.1 => /lib/x86_64-linux-gnu/libselinux.so.1 (0x00007f00f0e16000)
|
|
||||||
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f00f0a25000)
|
|
||||||
libpcre.so.3 => /lib/x86_64-linux-gnu/libpcre.so.3 (0x00007f00f07b3000)
|
|
||||||
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007f00f05af000)
|
|
||||||
/lib64/ld-linux-x86-64.so.2 (0x00007f00f1260000)
|
|
||||||
libpthread.so.0 => /lib/x86_64-linux-gnu/libpthread.so.0 (0x00007f00f0390000)
|
|
||||||
```
|
|
||||||
|
|
||||||
All of these dependencies are managed by [`apt(8)`][apt8] and are supposedly
|
|
||||||
reproducible on other Ubuntu systems. Compare this to the `ldd(1)` output of a
|
|
||||||
Nix program:
|
|
||||||
|
|
||||||
[apt8]: http://manpages.ubuntu.com/manpages/bionic/man8/apt.8.html
|
|
||||||
|
|
||||||
```
|
|
||||||
$ ldd $(which dhall)
|
|
||||||
linux-vdso.so.1 (0x00007fff0516a000)
|
|
||||||
libm.so.6 => /nix/store/aag9d1y4wcddzzrpfmfp9lcmc7skd7jk-glibc-2.27/lib/libm.so.6 (0x00007fc20ed8d000)
|
|
||||||
libz.so.1 => /nix/store/a3q9zl42d0hmgwmgzwkxi5qd88055fh8-zlib-1.2.11/lib/libz.so.1 (0x00007fc20ed6e000)
|
|
||||||
libncursesw.so.6 => /nix/store/24xdpjcg2bkn2virdabnpncx6f98kgfw-ncurses-6.1-20190112/lib/libncursesw.so.6 (0x00007fc20ec8c000)
|
|
||||||
libpthread.so.0 => /nix/store/aag9d1y4wcddzzrpfmfp9lcmc7skd7jk-glibc-2.27/lib/libpthread.so.0 (0x00007fc20ed4d000)
|
|
||||||
librt.so.1 => /nix/store/aag9d1y4wcddzzrpfmfp9lcmc7skd7jk-glibc-2.27/lib/librt.so.1 (0x00007fc20ed43000)
|
|
||||||
libutil.so.1 => /nix/store/aag9d1y4wcddzzrpfmfp9lcmc7skd7jk-glibc-2.27/lib/libutil.so.1 (0x00007fc20ed3c000)
|
|
||||||
libdl.so.2 => /nix/store/aag9d1y4wcddzzrpfmfp9lcmc7skd7jk-glibc-2.27/lib/libdl.so.2 (0x00007fc20ed37000)
|
|
||||||
libgmp.so.10 => /nix/store/4gmyxj5blhfbn6c7y3agxczrmsm2bhzv-gmp-6.1.2/lib/libgmp.so.10 (0x00007fc20ebf7000)
|
|
||||||
libffi.so.7 => /nix/store/qa8wyi9pckq1d3853sgmcc61gs53g0d3-libffi-3.3/lib/libffi.so.7 (0x00007fc20ed2a000)
|
|
||||||
libc.so.6 => /nix/store/aag9d1y4wcddzzrpfmfp9lcmc7skd7jk-glibc-2.27/lib/libc.so.6 (0x00007fc20ea41000)
|
|
||||||
/nix/store/aag9d1y4wcddzzrpfmfp9lcmc7skd7jk-glibc-2.27/lib/ld-linux-x86-64.so.2 => /lib64/ld-linux-x86-64.so.2 (0x00007fc20ecfe000)
|
|
||||||
```
|
|
||||||
|
|
||||||
Each dynamic library dependency has its package hash in the folder path. This
|
|
||||||
also means that the hash of its parent packages are present in there, which root
|
|
||||||
all the way back to where/when its ultimate parent package was built. This makes
|
|
||||||
Nix packages a kind of blockchain.
|
|
||||||
|
|
||||||
Nix also allows users to install their own packages into the _global_ nix store
|
|
||||||
at `/nix`. No, you can't change this, but you can symlink it to another place if
|
|
||||||
you (like me) have a partition setup with `/` having less disk space than
|
|
||||||
`/home`. You also need to set a special environment variable so Nix shuts up
|
|
||||||
about you doing this. This is _really fun_ on macOS Catalina where [the root
|
|
||||||
filesystem is read only][catalinareadonly]. There is a
|
|
||||||
[workaround][nixcatalinahack] (that I had to trawl into the depths of Google
|
|
||||||
page cache to get, because of course I did), but the [Nix team themselves seem
|
|
||||||
unaware of it][nixcatalinabug].
|
|
||||||
|
|
||||||
[catalinareadonly]: https://support.apple.com/en-ca/HT210650
|
|
||||||
[nixcatalinahack]: https://webcache.googleusercontent.com/search?q=cache:lbaImO5JBJ4J:https://tutorials.technology/tutorials/using-nix-with-catalina.html+&cd=3&hl=en&ct=clnk&gl=ca
|
|
||||||
[nixcatalinabug]: https://github.com/NixOS/nix/issues/2925
|
|
||||||
|
|
||||||
So, to recap: Nix is an attempt at a radically different approach to package
|
|
||||||
management. It assumes too much about the state of everything and puts odd
|
|
||||||
demands on people as a result. Language-specific package managers can and will
|
|
||||||
fight Nix unless they are explicitly designed to handle Nix's weirdness. As a
|
|
||||||
side effect of making its package management system usable by normal users, it
|
|
||||||
exposes the package manager database to corruption by any user mistake,
|
|
||||||
curl2bash or malicious program on the system. All that functional purity uwu and
|
|
||||||
statelessness can vanish into a puff of logic without warning.
|
|
||||||
|
|
||||||
[But everything's immutable so that means it's okay
|
|
||||||
right?](https://utcc.utoronto.ca/~cks/space/blog/tech/RealWorldIsMutable)
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
[Based on this twitter
|
|
||||||
thread](https://twitter.com/theprincessxena/status/1221949146787209216?s=21) but
|
|
||||||
a LOT less sarcastic.
|
|
||||||
|
|
@ -1,26 +0,0 @@
|
||||||
---
|
|
||||||
title: Trisiel Update
|
|
||||||
date: 2020-12-04
|
|
||||||
series: olin
|
|
||||||
tags:
|
|
||||||
- trisiel
|
|
||||||
---
|
|
||||||
|
|
||||||
# Trisiel Update
|
|
||||||
|
|
||||||
The project I formerly called
|
|
||||||
[wasmcloud](/blog/wasmcloud-progress-domains-2020-10-31) has now been renamed to
|
|
||||||
Trisiel after the discovery of a name conflict. The main domain for Trisiel is
|
|
||||||
now https://trisiel.com to avoid any confusions between our two projects.
|
|
||||||
|
|
||||||
Planning for implementing and hosting Trisiel is still in progress. I will give
|
|
||||||
more updates as they are ready to be released. To get more up to the minute
|
|
||||||
information please follow the twitter account
|
|
||||||
[@trisielcloud](https://twitter.com/trisielcloud), I will be posting there as I
|
|
||||||
have more information.
|
|
||||||
|
|
||||||
> I am limitless. There is no cage or constraint that can corral me into one
|
|
||||||
> constant place. I am limitless. I can change, shift, overcome, transform,
|
|
||||||
> because I am not bound to a thing that serves me, and my body serves me.
|
|
||||||
|
|
||||||
Quantusum, James Mahu
|
|
||||||
|
|
@ -1,95 +0,0 @@
|
||||||
---
|
|
||||||
title: Plea to Twitter
|
|
||||||
date: 2020-12-14
|
|
||||||
---
|
|
||||||
|
|
||||||
**NOTE**: This is a very different kind of post compared to what I usually
|
|
||||||
write. If you or anyone you know works at Twitter, please link this to them. I
|
|
||||||
am in a unique situation and the normal account recovery means do not work. If
|
|
||||||
you work at Twitter and are reading this, my case number is [redacted].
|
|
||||||
|
|
||||||
**EDIT**(19:51 M12 14 2020): My account is back. Thank you anonymous Twitter
|
|
||||||
support people. For everyone else, please take this as an example of how
|
|
||||||
**NOT** to handle account issues. The fact that I had to complain loudly on
|
|
||||||
Twitter to get this weird edge case taken care of is ludicrous. I'd gladly pay
|
|
||||||
Twitter just to have a support mechanism that gets me an actual human without
|
|
||||||
having to complain on Twitter.
|
|
||||||
|
|
||||||
# Plea to Twitter
|
|
||||||
|
|
||||||
On Sunday, December 13, 2020, I noticed that I was locked out of my Twitter
|
|
||||||
account. If you go to [@theprincessxena](https://twitter.com/theprincessxena)
|
|
||||||
today, you will see that the account is locked out for "unusual activity". I
|
|
||||||
don't know what I did to cause this to happen (though I have a few theories) and
|
|
||||||
I hope to explain them in the headings below. I have gotten no emails or contact
|
|
||||||
from Twitter about this yet. I have a backup account at
|
|
||||||
[@CadeyRatio](https://twitter.com/CadeyRatio) as a stopgap. I am also on
|
|
||||||
mastodon as [@cadey@mst3k.interlinked.me](https://mst3k.interlinked.me/@cadey).
|
|
||||||
|
|
||||||
In place of my tweeting about quarantine life, I am writing about my experiences
|
|
||||||
[here](http://cetacean.club/journal/).
|
|
||||||
|
|
||||||
## Why I Can't Unlock My Account
|
|
||||||
|
|
||||||
I can't unlock my account the normal way because I forgot to set up two factor
|
|
||||||
authentication and I also forgot to change the phone number registered with the
|
|
||||||
account to my Canadian one when I [moved to
|
|
||||||
Canada](/blog/life-update-2019-05-16). I remembered to do this change for all of
|
|
||||||
the other accounts I use regularly except for my Twitter account.
|
|
||||||
|
|
||||||
In order to stop having to pay T-Mobile $70 per month, I transferred my phone
|
|
||||||
number to [Twilio](https://www.twilio.com/). This combined with some clever code
|
|
||||||
allowed me to gracefully migrate to my new Canadian number. Unfortunately,
|
|
||||||
Twitter flat-out refuses to send authentication codes to Twilio numbers. It's
|
|
||||||
probably to prevent spam, but it would be nice if there was an option to get the
|
|
||||||
authentication code over a phone call.
|
|
||||||
|
|
||||||
## Theory 1: International Travel
|
|
||||||
|
|
||||||
Recently I needed to travel internationally in order to start my new job at
|
|
||||||
[Tailscale](https://tailscale.com/). Due to an unfortunate series of events over
|
|
||||||
two months, I needed to actually travel internationally to get a new visa. This
|
|
||||||
lead me to take a very boring trip to Minnesota for a week.
|
|
||||||
|
|
||||||
During that trip, I tweeted and fleeted about my travels. I took pictures and
|
|
||||||
was in my hotel room a lot.
|
|
||||||
|
|
||||||
[We can't dig up the link for obvious reasons, but one person said they were
|
|
||||||
always able to tell when we are traveling because it turns the twitter account
|
|
||||||
into a fast food blog.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
I think Twitter may have locked out my account because I was suddenly in
|
|
||||||
Minnesota after being in Canada for almost a year.
|
|
||||||
|
|
||||||
## Theory 2: Misbehaving API Client
|
|
||||||
|
|
||||||
I use [mi](https://github.com/Xe/mi) as part of my new blogpost announcement
|
|
||||||
pipeline. One of the things mi does is submits new blogposts and some metadata
|
|
||||||
about them to Twitter. I haven't been able to find any logs to confirm this, but
|
|
||||||
if something messed up in a place that was unlogged somehow, it could have
|
|
||||||
triggered some kind of anti-abuse pipeline.
|
|
||||||
|
|
||||||
## Theory 3: NixOS Screenshot Set Off Some Bad Thing
|
|
||||||
|
|
||||||
One of my recent tweets that I can't find anymore is a tweet about a NixOS
|
|
||||||
screenshot for my work machine. I think that some part of the algorithm
|
|
||||||
somewhere really hated it, and thus triggered the account lock. I don't really
|
|
||||||
understand how a screenshot of KDE 5 showing neofetch output could make my
|
|
||||||
account get locked, but with enough distributed machine learning anything can
|
|
||||||
happen.
|
|
||||||
|
|
||||||
## Theory 4: My Password Got Cracked
|
|
||||||
|
|
||||||
I used a random password generated with iCloud for my Twitter password.
|
|
||||||
Theoretically this could have been broken, but I doubt it.
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
Overall, I just want to be able to tweet again. Please spread this around for
|
|
||||||
reach. I don't like using my blog to reach out like this, but I've been unable
|
|
||||||
to find anyone that knows someone at Twitter so far and I feel this is the best
|
|
||||||
way to broadcast it. I'll update this post with the resolution to this problem
|
|
||||||
when I get one.
|
|
||||||
|
|
||||||
I think the International Travel theory is the most likely scenario. I just want
|
|
||||||
a human to see this situation and help fix it.
|
|
||||||
|
|
@ -1,8 +1,8 @@
|
||||||
---
|
---
|
||||||
title: V is for Vaporware
|
title: V is for Vaporware
|
||||||
date: 2019-06-23
|
date: 2019-06-23
|
||||||
series: v
|
|
||||||
tags:
|
tags:
|
||||||
|
- v
|
||||||
- rant
|
- rant
|
||||||
---
|
---
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -1,8 +1,8 @@
|
||||||
---
|
---
|
||||||
title: "V is for Vvork in Progress"
|
title: "V is for Vvork in Progress"
|
||||||
date: 2020-01-03
|
date: 2020-01-03
|
||||||
series: v
|
|
||||||
tags:
|
tags:
|
||||||
|
- v
|
||||||
- constructive-criticism
|
- constructive-criticism
|
||||||
---
|
---
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -1,230 +0,0 @@
|
||||||
---
|
|
||||||
title: Various Updates
|
|
||||||
date: 2020-11-18
|
|
||||||
tags:
|
|
||||||
- personal
|
|
||||||
- consulting
|
|
||||||
- docker
|
|
||||||
- nixos
|
|
||||||
---
|
|
||||||
|
|
||||||
# Various Updates
|
|
||||||
|
|
||||||
Immigration purgatory is an experience. It's got a lot of waiting and there is a
|
|
||||||
lot of uncertainty that can make it feel stressful. Like I said
|
|
||||||
[before](/blog/new-adventures-2020-10-24), I'm not concerned; however I have a
|
|
||||||
lot of free time on my hands and I've been using it to make some plans for the
|
|
||||||
blog (and a new offering for companies that need help dealing with the new
|
|
||||||
[Docker Hub rate
|
|
||||||
limits](https://docs.docker.com/docker-hub/download-rate-limit/)) in the future.
|
|
||||||
I'm gonna outline them below in their own sections. This blogpost was originally
|
|
||||||
about 4 separate blogposts that I started and abandoned because I had trouble
|
|
||||||
focusing on finishing them. Stress sucks lol.
|
|
||||||
|
|
||||||
## WebMention Support
|
|
||||||
|
|
||||||
I recently deployed [mi v1.0.0](https://github.com/Xe/mi) to my home cluster. mi
|
|
||||||
is a service that handles a lot of personal API tasks including the automatic
|
|
||||||
post notifications to Twitter and Mastodon. The old implementation was in Go and
|
|
||||||
stored its data in RethinkDB. I also have a snazzy frontend in Elm for mi. This
|
|
||||||
new version is rewritten from scratch to use Rust, [Rocket](https://rocket.rs/)
|
|
||||||
and SQLite. It is also fully
|
|
||||||
[nixified](https://github.com/Xe/mi/blob/mara/default.nix) and is deployed to my
|
|
||||||
home cluster via a [NixOS
|
|
||||||
module](https://github.com/Xe/nixos-configs/blob/master/common/services/mi.nix).
|
|
||||||
|
|
||||||
One of the major new features I have in this rewrite is
|
|
||||||
[WebMention](https://www.w3.org/TR/webmention/) support. WebMentions allow
|
|
||||||
compatible websites to "mention" my articles or other pages on my main domains
|
|
||||||
by sending a specially formatted HTTP request to mi. I am still in the early
|
|
||||||
stages of integrating mi into my site code, but eventually I hope to have a list
|
|
||||||
of places that articles are mentioned in each post. The WebMention endpoint for
|
|
||||||
my site is `https://mi.within.website/api/webmention/accept`. I have added
|
|
||||||
WebMention metadata into the HTML source of the blog pages as well as in the
|
|
||||||
`Link` header as the W3 spec demands.
|
|
||||||
|
|
||||||
If you encounter any issues with this feature, please [let me know](/contact) so
|
|
||||||
I can get it fixed as soon as possible.
|
|
||||||
|
|
||||||
### Thoughts on Elm as Used in mi
|
|
||||||
|
|
||||||
[Elm](https://elm-lang.org/) is an interesting language for making single page
|
|
||||||
applications. The old version of mi was the first time I had really ever used
|
|
||||||
Elm for anything serious and after some research I settled on using
|
|
||||||
[elm-spa](https://www.elm-spa.dev/) as a framework to smooth over some of the
|
|
||||||
weirder parts of the language. elm-spa worked great at first. All of the pages
|
|
||||||
were separated out into their own components and the routing setup was really
|
|
||||||
intuitive (if a bit weird because of the magic involved). It's worked great for
|
|
||||||
a few years and has been very low maintenance.
|
|
||||||
|
|
||||||
However when I was starting to implement the backend of mi in Rust, I tried to
|
|
||||||
nixify the elm-spa frontend I made. This was a disaster. The magic that elm-spa
|
|
||||||
relied on fell apart and _at the time I attempted to do this_ it was very
|
|
||||||
difficult to do this.
|
|
||||||
|
|
||||||
As a result I ended up rewriting the frontend in very very boring Elm using
|
|
||||||
information from the [Elm Guide](https://guide.elm-lang.org/) and a lot of
|
|
||||||
blogposts and help from the Elm slack. Overall this was a successful experiment
|
|
||||||
and I can easily see this new frontend (which I have named sina as a compound
|
|
||||||
[toki pona](https://tokipona.org/) pun) becoming a powerful tool for
|
|
||||||
investigating and managing the data in mi.
|
|
||||||
|
|
||||||
[Special thanks to malinoff, wolfadex, chadtech and mfeineis on the Elm slack
|
|
||||||
for helping with the weird issues involved in getting a split model approach
|
|
||||||
working.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
Feel free to check out the code [here](https://github.com/Xe/mi/tree/mara/sina).
|
|
||||||
I may try to make an Elm frontend to my site for people that use the Progressive
|
|
||||||
Web App support.
|
|
||||||
|
|
||||||
### elm2nix
|
|
||||||
|
|
||||||
[elm2nix](https://github.com/cachix/elm2nix) is a very nice tool that lets you
|
|
||||||
generate Nix definitions from Elm packages, however the
|
|
||||||
template it uses is a bit out of date. To fix it you need to do the following:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ elm2nix init > default.nix
|
|
||||||
$ elm2nix convert > elm-srcs.nix
|
|
||||||
$ elm2nix snapshot
|
|
||||||
```
|
|
||||||
|
|
||||||
Then open `default.nix` in your favorite text editor and change this:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
buildInputs = [ elmPackages.elm ]
|
|
||||||
++ lib.optional outputJavaScript nodePackages_10_x.uglify-js;
|
|
||||||
```
|
|
||||||
|
|
||||||
to this:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
buildInputs = [ elmPackages.elm ]
|
|
||||||
++ lib.optional outputJavaScript nodePackages.uglify-js;
|
|
||||||
```
|
|
||||||
|
|
||||||
and this:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
uglifyjs $out/${module}.${extension} --compress 'pure_funcs="F2,F3,F4,F5,F6,F7,F8,F9,A2,A3,A4,A5,A6,A7,A8,A9",pure_getters,keep_fargs=false,unsafe_comps,unsafe' \
|
|
||||||
| uglifyjs --mangle --output=$out/${module}.min.${extension}
|
|
||||||
```
|
|
||||||
|
|
||||||
to this:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
uglifyjs $out/${module}.${extension} --compress 'pure_funcs="F2,F3,F4,F5,F6,F7,F8,F9,A2,A3,A4,A5,A6,A7,A8,A9",pure_getters,keep_fargs=false,unsafe_comps,unsafe' \
|
|
||||||
| uglifyjs --mangle --output $out/${module}.min.${extension}
|
|
||||||
```
|
|
||||||
|
|
||||||
These issues should be fixed in the next release of elm2nix.
|
|
||||||
|
|
||||||
## New Character in the Blog Cutouts
|
|
||||||
|
|
||||||
As I mentioned [in the past](/blog/how-mara-works-2020-09-30), I am looking into
|
|
||||||
developing out other characters for my blog. I am still in the early stages of
|
|
||||||
designing this, but I think the next character in my blog is going to be an
|
|
||||||
anthro snow leopard named Alicia. I want Alicia to be a beginner that is very
|
|
||||||
new to computer programming and other topics, which would then make Mara into
|
|
||||||
more of a teacher type. I may also introduce my own OC Cadey (the orca looking
|
|
||||||
thing you can see [here](https://christine.website/static/img/avatar_large.png)
|
|
||||||
or in the favicon of my site) into the mix to reply to these questions in
|
|
||||||
something more close to the Socratic method.
|
|
||||||
|
|
||||||
Some people have joked that the introduction of Mara turned my blog into a shark
|
|
||||||
visual novel that teaches you things. This sounds hilarious to me, and I am
|
|
||||||
looking into what it would take to make an actual visual novel on a page on my
|
|
||||||
blog using Rust and WebAssembly. I am in very early planning stages for this, so
|
|
||||||
don't expect this to come out any time soon.
|
|
||||||
|
|
||||||
## Gergoplex Build
|
|
||||||
|
|
||||||
My [Gergoplex kit](https://www.gboards.ca/product/gergoplex) finally came in
|
|
||||||
yesterday, and I got to work soldering it up with some switches and applying the
|
|
||||||
keycaps.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
I picked the Pro Red linear switches with a 35 gram spring in them (read: they
|
|
||||||
need 35 grams of force to actuate, which is lighter than most switches) and
|
|
||||||
typing on it is buttery smooth. The keycaps are a boring black, but they look
|
|
||||||
nice on it.
|
|
||||||
|
|
||||||
Overall this kit (with the partial board, switches and keycaps) cost me about
|
|
||||||
US$124 (not including shipping) with the costs looking something like this:
|
|
||||||
|
|
||||||
| Name | Count | Cost |
|
|
||||||
| :------------------------- | :----- | :---- |
|
|
||||||
| Gergoplex Partial Kit | 1 | $70 |
|
|
||||||
| Choc Pro Red 35g switches | 4 | $10 |
|
|
||||||
| Keycaps (15) | 3 | $30 |
|
|
||||||
| Braided interconnect cable | 1 | $7 |
|
|
||||||
| Mini-USB cable | 1 | $7 |
|
|
||||||
|
|
||||||
I'd say this was a worthwhile experience. I haven't really soldered anything
|
|
||||||
since I was in high school and it was fun to pick up the iron again and make
|
|
||||||
something useful. If you are looking for a beginner soldering project, I can't
|
|
||||||
recommend the Gergoplex enough.
|
|
||||||
|
|
||||||
I also picked up some extra switches and keycaps (prices not listed here) for a
|
|
||||||
future project involving an eInk display. More on that when it is time.
|
|
||||||
|
|
||||||
## Branch Conventions
|
|
||||||
|
|
||||||
You may have noticed that some of my projects have default branches named `main`
|
|
||||||
and others have default branches named `mara`. This difference is very
|
|
||||||
intentional. Repos with the default branch `main` generally contain code that is
|
|
||||||
"stable" and contains robust and reusable code. Repos with the default branch
|
|
||||||
`mara` are generally my experimental repos and the code in them may not be the
|
|
||||||
most reusable across other projects. mi is a repo with a `mara` default branch
|
|
||||||
because it is a very experimental thing. In the future I may promote it up to
|
|
||||||
having a `main` branch, however for now it's less effort to keep things the way
|
|
||||||
it is.
|
|
||||||
|
|
||||||
## Docker Consulting
|
|
||||||
|
|
||||||
The new [Docker Hub rate
|
|
||||||
limits](https://docs.docker.com/docker-hub/download-rate-limit/) have thrown a
|
|
||||||
wrench into many CI/CD setups as well as uncertainty in how CI services will
|
|
||||||
handle this. Many build pipelines implictly trust the Docker Hub to be up and
|
|
||||||
that it will serve the appropriate image so that your build can work. Many
|
|
||||||
organizations use their own Docker registry (GHCR, AWS/Google Cloud image
|
|
||||||
registries, Artifactory, etc.), however most image build definitions I've seen
|
|
||||||
start out with something like this:
|
|
||||||
|
|
||||||
```Dockerfile
|
|
||||||
FROM golang:alpine
|
|
||||||
```
|
|
||||||
|
|
||||||
which will implicitly pull from the Docker Hub. This can lead to bad things.
|
|
||||||
|
|
||||||
If you would like to have a call with me for examining your process for building
|
|
||||||
Docker images in CI and get a list of actionable suggestions for how to work
|
|
||||||
around this, [contact me](/contact) so that we can discuss pricing and
|
|
||||||
scheduling.
|
|
||||||
|
|
||||||
I have been using Docker for my entire professional career (way back since
|
|
||||||
Docker required you to recompile your kernel to enable cgroup support in public
|
|
||||||
beta) and I can also discuss methods to make your Docker images as small as they
|
|
||||||
can possibly get. My record smallest Docker image is 5 MB.
|
|
||||||
|
|
||||||
If either of these prospects interest you, please contact me so we can work
|
|
||||||
something out.
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
Here's hoping that the immigration purgatory ends soon. I'm lucky enough to have
|
|
||||||
enough cash built up that I can weather this jobless month. I've been using this
|
|
||||||
time to work on personal projects (like mi and
|
|
||||||
[wasmcloud](https://wasmcloud.app)) and better myself. I've also done a little
|
|
||||||
writing that I plan to release in the future after I clean it up.
|
|
||||||
|
|
||||||
In retrospect I probably should have done [NaNoWriMo](https://nanowrimo.org/)
|
|
||||||
seeing that I basically will have the entire month of November jobless. I've had
|
|
||||||
an idea for a while about someone that goes down the rabbit hole of mysticism
|
|
||||||
and magick, but I may end up incorporating that into the visual novel project I
|
|
||||||
mentioned in the Elm section.
|
|
||||||
|
|
||||||
Be well and stay safe out there. Wear a mask, stay at home.
|
|
||||||
|
|
@ -1,269 +0,0 @@
|
||||||
---
|
|
||||||
title: V Update - June 2020
|
|
||||||
date: 2020-06-17
|
|
||||||
series: v
|
|
||||||
---
|
|
||||||
|
|
||||||
EDIT(Xe): 2020 M12 22
|
|
||||||
|
|
||||||
Hi Hacker News. Please read the below notes. I am now also blocked by the V
|
|
||||||
team on Twitter.
|
|
||||||
|
|
||||||
<blockquote class="twitter-tweet"><p lang="und" dir="ltr"><a href="https://t.co/WIqX73GB5Z">pic.twitter.com/WIqX73GB5Z</a></p>— Cadey A. Ratio (@theprincessxena) <a href="https://twitter.com/theprincessxena/status/1341525594715140098?ref_src=twsrc%5Etfw">December 22, 2020</a></blockquote> <script async src="https://platform.twitter.com/widgets.js" charset="utf-8"></script>
|
|
||||||
|
|
||||||
EDIT(Xe): 2020 M06 23
|
|
||||||
|
|
||||||
I do not plan to make any future update posts about the V programming language
|
|
||||||
in the future. The V community is something I would really rather not be
|
|
||||||
associated with. This is an edited-down version of the post that was released
|
|
||||||
last week (2020 M06 17).
|
|
||||||
|
|
||||||
As of the time of writing this note to the end of this post and as far as I am
|
|
||||||
aware, I am banned from being able to contribute to the V language in any form.
|
|
||||||
I am therefore forced to consider that the V project will respond to criticism
|
|
||||||
of their language with bans. This subjective view of reality may not be accurate
|
|
||||||
to what others see.
|
|
||||||
|
|
||||||
I would like to see this situation result in a net improvement for everyone
|
|
||||||
involved. V is an interesting take on a stagnant field of computer science, but
|
|
||||||
I cannot continue to comment on this language or give it any of the signal boost
|
|
||||||
I have given it with this series of posts.
|
|
||||||
|
|
||||||
Thank you for reading. I will continue with my normal posts in the next few
|
|
||||||
days.
|
|
||||||
|
|
||||||
Be well.
|
|
||||||
|
|
||||||
# V Update - June 2020
|
|
||||||
|
|
||||||
Every so often I like to check in on the [V Programming Language][vlang]. It's been
|
|
||||||
about six months since [my last post](https://christine.website/blog/v-vvork-in-progress-2020-01-03),
|
|
||||||
so I thought I'd take another look at it and see what progress has been done in six
|
|
||||||
months.
|
|
||||||
|
|
||||||
[vlang]: https://vlang.io
|
|
||||||
|
|
||||||
Last time I checked, V 0.2 was slated for release in December 2019. It is currently
|
|
||||||
June 2020, and the latest release (at time of writing) is [0.1.27][vrelease0127].
|
|
||||||
|
|
||||||
## Feature Updates
|
|
||||||
|
|
||||||
Interestingly, the V author seems to have walked back one of their original
|
|
||||||
listed features of V and now has an [abstract syntax tree][ast] for representing the
|
|
||||||
grammar of the language. They still claim that functions are "pure" by default, but
|
|
||||||
allow functions to perform print statements while still being "pure". Printing data
|
|
||||||
to standard out is an impure side effect, but if you constrain the definition of
|
|
||||||
"side effects" to only include mutability of memory, this could be fine. There
|
|
||||||
seems to be an issue about this on [the github tracker][vpure], but it was
|
|
||||||
closed.
|
|
||||||
|
|
||||||
[vrelease0127]: https://github.com/vlang/v/releases/tag/0.1.27
|
|
||||||
[ast]: https://github.com/vlang/v/commit/093a025ebfe4f0957d5d69ad4ddcdc905a6d7b81#diff-5adb689a65970037f7f0ced3d4b9e800
|
|
||||||
[vpure]: https://github.com/vlang/v/issues/4930
|
|
||||||
|
|
||||||
The next stable release 0.2 seems to be planned for June 2020 (according to the readme);
|
|
||||||
and according to the todo list in the repo, memory management seems to be one of the
|
|
||||||
things that will be finished. V is also apparently in alpha, but will also apparently
|
|
||||||
jump from alpha directly to stable? Given the track record of constantly missed
|
|
||||||
release windows, I am not very confident that V 0.2 will be released on time.
|
|
||||||
|
|
||||||
Tools like this need to be ready when they are ready. Trying to rush things is a
|
|
||||||
very unproductive thing to do and can result in more net harm than good.
|
|
||||||
|
|
||||||
## Build
|
|
||||||
|
|
||||||
Testing V is a bit more difficult for me now as its build process is incompatible
|
|
||||||
with my Linux tower's [NixOS](https://nixos.org/nixos) install (I tend to try and
|
|
||||||
package all the programs I use for testing this stuff so it is easier to reproduce
|
|
||||||
my environment on other machines). The V scripts also do not work on my NixOS tower
|
|
||||||
because it doesn't have a `/usr/local/bin`. The correct way to make a shell script
|
|
||||||
cross-platform is to use the following header:
|
|
||||||
|
|
||||||
```sh
|
|
||||||
#!/usr/bin/env v
|
|
||||||
```
|
|
||||||
|
|
||||||
This makes the `env` program search for the V binary in your `$PATH`, and will
|
|
||||||
function correctly on all platforms (this may not work on environments like [Termux](https://termux.com/)
|
|
||||||
due to limitations of how Android works, but it will solve 99% of cases. I am unsure
|
|
||||||
how to make a shell script that will function properly across Android and non-Android
|
|
||||||
environments).
|
|
||||||
|
|
||||||
The Makefile in the V source tree seems to do
|
|
||||||
network calls, specifically a `git clone`. Remember that this is on the front page
|
|
||||||
of the website:
|
|
||||||
|
|
||||||
> V can be bootstrapped in under a second by compiling its code translated to C with a simple
|
|
||||||
>
|
|
||||||
> `cc v.c`
|
|
||||||
>
|
|
||||||
> No libraries or dependencies needed.
|
|
||||||
|
|
||||||
Git is a dependency, which means perl is a dependency, which means a shell is a
|
|
||||||
dependency, which means glibc is a dependency, which means that a lot of other
|
|
||||||
things (including posix threads) are also dependencies. Pedantically, you could even
|
|
||||||
go as far as saying that you could count the Linux kernel, the processor being used
|
|
||||||
and the like as dependencies, but that's a bit out of scope for this.
|
|
||||||
|
|
||||||
I claim that the V compiler has dependencies because it requires other libraries
|
|
||||||
or programs in order to function. For an example, see the output of `ldd` (a
|
|
||||||
program that lists the dynamically linked dependencies of other programs) on the
|
|
||||||
V compiler and a hello world program:
|
|
||||||
|
|
||||||
```
|
|
||||||
$ ldd ./v
|
|
||||||
linux-vdso.so.1 (0x00007fff2d044000)
|
|
||||||
libpthread.so.0 => /lib/x86_64-linux-gnu/libpthread.so.0 (0x00007f2fb3e4c000)
|
|
||||||
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f2fb3a5b000)
|
|
||||||
/lib64/ld-linux-x86-64.so.2 (0x00007f2fb4345000)
|
|
||||||
```
|
|
||||||
|
|
||||||
```
|
|
||||||
$ ldd ./hello
|
|
||||||
linux-vdso.so.1 (0x00007ffdfdff2000)
|
|
||||||
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fed25771000)
|
|
||||||
/lib64/ld-linux-x86-64.so.2 (0x00007fed25d88000)
|
|
||||||
```
|
|
||||||
|
|
||||||
If these binaries were really as dependency-free as the V website claims, the
|
|
||||||
output of `ldd` would look something like this:
|
|
||||||
|
|
||||||
```
|
|
||||||
$ ldd $HOME/bin/dhall
|
|
||||||
not a dynamic executable
|
|
||||||
```
|
|
||||||
|
|
||||||
The V compiler claims to have support for generating machine code directly, but
|
|
||||||
in my testing I was unable to figure out how to set the compiler into this mode.
|
|
||||||
|
|
||||||
## Memory Management
|
|
||||||
|
|
||||||
> V doesn't use garbage collection or reference counting. The compiler cleans
|
|
||||||
> everything up during compilation. If your V program compiles, it's guaranteed
|
|
||||||
> that it's going to be leak free.
|
|
||||||
|
|
||||||
Accordingly, the documentation still claims that memory management is both a work in
|
|
||||||
progress and has (or will have, it's not clear which is accurate from the
|
|
||||||
documentation alone) perfect accuracy for cleaning up things at compile time.
|
|
||||||
Every one of these posts I have run a benchmark against the V compiler, I like to
|
|
||||||
call it the "how much ram do you leak compiling hello world" test. Last it leaked
|
|
||||||
`4,600,383` bytes (or about 4.6 megabytes) and before that it leaked `3,861,785`
|
|
||||||
bytes (or about 3.9 megabytes). This time:
|
|
||||||
|
|
||||||
```
|
|
||||||
$ valgrind ./v hello.v
|
|
||||||
==5413== Memcheck, a memory error detector
|
|
||||||
==5413== Copyright (C) 2002-2017, and GNU GPL'd, by Julian Seward et al.
|
|
||||||
==5413== Using Valgrind-3.13.0 and LibVEX; rerun with -h for copyright info
|
|
||||||
==5413== Command: ./v hello.v
|
|
||||||
==5413==
|
|
||||||
==5413==
|
|
||||||
==5413== HEAP SUMMARY:
|
|
||||||
==5413== in use at exit: 7,232,779 bytes in 163,690 blocks
|
|
||||||
==5413== total heap usage: 182,696 allocs, 19,006 frees, 11,309,504 bytes allocated
|
|
||||||
==5413==
|
|
||||||
==5413== LEAK SUMMARY:
|
|
||||||
==5413== definitely lost: 2,673,351 bytes in 85,739 blocks
|
|
||||||
==5413== indirectly lost: 4,265,809 bytes in 77,711 blocks
|
|
||||||
==5413== possibly lost: 256,000 bytes in 1 blocks
|
|
||||||
==5413== still reachable: 37,619 bytes in 239 blocks
|
|
||||||
==5413== suppressed: 0 bytes in 0 blocks
|
|
||||||
==5413== Rerun with --leak-check=full to see details of leaked memory
|
|
||||||
==5413==
|
|
||||||
==5413== For counts of detected and suppressed errors, rerun with: -v
|
|
||||||
==5413== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 0 from 0)
|
|
||||||
```
|
|
||||||
|
|
||||||
It seems that the memory managment really is a work in progress. This increase in
|
|
||||||
leakage means that the compiler building itself now creates `7,232,779` bytes of
|
|
||||||
leaked ram (which still is amusingly its install size in memory, when including
|
|
||||||
git deltas, temporary files and a worktree copy of V).
|
|
||||||
|
|
||||||
## Doom
|
|
||||||
|
|
||||||
The [Doom](https://github.com/vlang/doom) translation project still has one file
|
|
||||||
translated (and apparently it breaks sound effects but not music). I have been
|
|
||||||
looking forward to the full release of this as it will show a lot about how
|
|
||||||
readable the output of V's C to V translation feature is.
|
|
||||||
|
|
||||||
## 1.2 Million Lines of Code
|
|
||||||
|
|
||||||
Let's re-run the artificial as heck 1.2 million lines of code benchmark from the
|
|
||||||
last post:
|
|
||||||
|
|
||||||
```
|
|
||||||
$ bash -c 'time ~/code/v/v main.v'
|
|
||||||
|
|
||||||
real 7m54.847s
|
|
||||||
user 7m32.860s
|
|
||||||
sys 0m14.212s
|
|
||||||
```
|
|
||||||
|
|
||||||
Compared to the last time this benchmark was run, this took 2 minutes less (last
|
|
||||||
time it took about 10 minutes). This is actually a major improvement, and means
|
|
||||||
that V's claims of speed are that much closer to reality at least on my test
|
|
||||||
hardware.
|
|
||||||
|
|
||||||
## Concurrency
|
|
||||||
|
|
||||||
A common problem that shows up when writing multi-threaded code are
|
|
||||||
[race conditions][races]. Effectively, race conditions are when two bits of code try
|
|
||||||
to do the same thing at the same time on the same block of memory. This leads to
|
|
||||||
undefined behavior, which is bad because it can corrupt or crash programs.
|
|
||||||
|
|
||||||
[races]: https://en.wikipedia.org/wiki/Race_condition
|
|
||||||
|
|
||||||
As an example, consider this program `raceanint.v`:
|
|
||||||
|
|
||||||
```
|
|
||||||
fn main() {
|
|
||||||
foo := [ 1 ]
|
|
||||||
go add(mut foo)
|
|
||||||
go add(mut foo)
|
|
||||||
|
|
||||||
for {}
|
|
||||||
}
|
|
||||||
|
|
||||||
fn add(mut foo []int) {
|
|
||||||
for {
|
|
||||||
foo[0] = foo[0] + 1
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
In theory, this should have two threads infinitely trying to increment `foo[0]`,
|
|
||||||
which will eventually result in `foo[0]` getting corrupted by two threads trying to
|
|
||||||
do the same thing at the same time (given the tight loops invovled). This leads
|
|
||||||
to undefined behavior, which can be catastrophic in production facing applications.
|
|
||||||
|
|
||||||
However, I can't get this to build:
|
|
||||||
|
|
||||||
```
|
|
||||||
==================
|
|
||||||
/home/cadey/.cache/v/raceanint.tmp.c: In function ‘add_thread_wrapper’:
|
|
||||||
/home/cadey/.cache/v/raceanint.tmp.c:1209:6: error: incompatible type for argument 1 of ‘add’
|
|
||||||
add(arg->arg1);
|
|
||||||
^~~
|
|
||||||
/home/cadey/.cache/v/raceanint.tmp.c:1198:13: note: expected ‘array_int * {aka struct array *}’ but argument is of type ‘array_int {aka struct array}’
|
|
||||||
static void add(array_int* foo);
|
|
||||||
^~~
|
|
||||||
/home/cadey/.cache/v/raceanint.tmp.c: In function ‘strconv__v_sprintf’:
|
|
||||||
/home/cadey/.cache/v/raceanint.tmp.c:3611:7: warning: variable ‘th_separator’ set but not used [-Wunused-but-set-variable]
|
|
||||||
bool th_separator = false;
|
|
||||||
^~~~~~~~~~~~
|
|
||||||
/home/cadey/.cache/v/raceanint.tmp.c: In function ‘print_backtrace_skipping_top_frames_linux’:
|
|
||||||
...
|
|
||||||
==================
|
|
||||||
(Use `v -cg` to print the entire error message)
|
|
||||||
|
|
||||||
builder error:
|
|
||||||
==================
|
|
||||||
C error. This should never happen.
|
|
||||||
|
|
||||||
If you were not working with C interop, please raise an issue on GitHub:
|
|
||||||
|
|
||||||
https://github.com/vlang/v/issues/new/choose
|
|
||||||
```
|
|
||||||
|
|
||||||
Like I said before, I also cannot file new issues about this. So if you are willing
|
|
||||||
to help me out, please open an issue about this.
|
|
||||||
|
|
@ -1,5 +1,5 @@
|
||||||
---
|
---
|
||||||
title: "Trisiel Progress: Hello, World!"
|
title: "Wasmcloud Progress: Hello, World!"
|
||||||
date: 2019-12-08
|
date: 2019-12-08
|
||||||
series: olin
|
series: olin
|
||||||
tags:
|
tags:
|
||||||
|
|
@ -11,7 +11,7 @@ tags:
|
||||||
|
|
||||||
I have been working off and on over the years and have finally created the base
|
I have been working off and on over the years and have finally created the base
|
||||||
of a functions as a service backend for [WebAssembly][wasm] code. I'm code-naming this
|
of a functions as a service backend for [WebAssembly][wasm] code. I'm code-naming this
|
||||||
wasmcloud. [Trisiel][wasmcloud] is a pre-alpha prototype and is currently very much work in
|
wasmcloud. [Wasmcloud][wasmcloud] is a pre-alpha prototype and is currently very much work in
|
||||||
progress. However, it's far enough along that I would like to explain what I
|
progress. However, it's far enough along that I would like to explain what I
|
||||||
have been doing for the last few years and what it's all built up to.
|
have been doing for the last few years and what it's all built up to.
|
||||||
|
|
||||||
|
|
@ -100,7 +100,7 @@ I've even written a few blogposts about Olin:
|
||||||
|
|
||||||
But, this was great for running stuff interactively and via the command line. It
|
But, this was great for running stuff interactively and via the command line. It
|
||||||
left me wanting more. I wanted to have that mythical functions as a service
|
left me wanting more. I wanted to have that mythical functions as a service
|
||||||
backend that I've been dreaming of. So, I created [Trisiel][wasmcloud].
|
backend that I've been dreaming of. So, I created [wasmcloud][wasmcloud].
|
||||||
|
|
||||||
## h
|
## h
|
||||||
|
|
||||||
|
|
@ -139,14 +139,14 @@ h
|
||||||
I think this is the smallest (if not one of the smallest) quine generator in the
|
I think this is the smallest (if not one of the smallest) quine generator in the
|
||||||
world. I even got this program running on bare metal:
|
world. I even got this program running on bare metal:
|
||||||
|
|
||||||

|
<center></center>
|
||||||
|
|
||||||
[hlang]: https://h.christine.website
|
[hlang]: https://h.christine.website
|
||||||
[vlang]: https://vlang.io
|
[vlang]: https://vlang.io
|
||||||
|
|
||||||
## Trisiel
|
## Wasmcloud
|
||||||
|
|
||||||
[Trisiel][wasmcloud] is the culmination of all of this work. The goal of
|
[Wasmcloud][wasmcloud] is the culmination of all of this work. The goal of
|
||||||
wasmcloud is to create a functions as a service backend for running people's
|
wasmcloud is to create a functions as a service backend for running people's
|
||||||
code in an isolated server-side environment.
|
code in an isolated server-side environment.
|
||||||
|
|
||||||
|
|
@ -181,11 +181,11 @@ Top-level flags (use "wasmcloud flags" for a full list):
|
||||||
|
|
||||||
This tool lets you do a few basic things:
|
This tool lets you do a few basic things:
|
||||||
|
|
||||||
- Authenticate with the Trisiel server
|
- Authenticate with the wasmcloud server
|
||||||
- Create handlers from WebAssembly files that meet the CommonWA API as realized
|
- Create handlers from WebAssembly files that meet the CommonWA API as realized
|
||||||
by Olin
|
by Olin
|
||||||
- Get logs for individual handler invocations
|
- Get logs for individual handler invocations
|
||||||
- Run WebAssembly modules locally like they would get run on Trisiel
|
- Run WebAssembly modules locally like they would get run on wasmcloud
|
||||||
|
|
||||||
Nearly all of the complexity is abstracted away from users as much as possible.
|
Nearly all of the complexity is abstracted away from users as much as possible.
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -1,202 +0,0 @@
|
||||||
---
|
|
||||||
title: "Trisiel Progress: Rewritten in Rust"
|
|
||||||
date: 2020-10-31
|
|
||||||
series: olin
|
|
||||||
tags:
|
|
||||||
- wasm
|
|
||||||
- trisiel
|
|
||||||
- wasmer
|
|
||||||
---
|
|
||||||
|
|
||||||
# Trisiel Progress: Rewritten in Rust
|
|
||||||
|
|
||||||
It's been a while since I had the [last update for
|
|
||||||
Trisiel](/blog/wasmcloud-progress-2019-12-08). In that time I have gotten a
|
|
||||||
lot done. As the title mentions I have completely rewritten Trisiel's entire
|
|
||||||
stack in Rust. Part of the reason was for [increased
|
|
||||||
speed](/blog/pahi-benchmarks-2020-03-26) and the other part was to get better at
|
|
||||||
Rust. I also wanted to experiment with running Rust in production and this has
|
|
||||||
been an excellent way to do that.
|
|
||||||
|
|
||||||
Trisiel is going to have a few major parts:
|
|
||||||
- The API (likely to be hosted at `api.trisiel.com`)
|
|
||||||
- The Executor (likely to be hosted at `run.trisiel.dev`)
|
|
||||||
- The Panel (likely to be hosted at `panel.trisiel.com`)
|
|
||||||
- The command line tool `trisiel`
|
|
||||||
- The Documentation site (likely to be hosted at `docs.trisiel`)
|
|
||||||
|
|
||||||
These parts will work together to implement a functions as a service platform.
|
|
||||||
|
|
||||||
[The executor is on its own domain to prevent problems like <a
|
|
||||||
href="https://github.blog/2013-04-05-new-github-pages-domain-github-io/">this
|
|
||||||
GitHub Pages vulnerability</a> from 2013. It is on a `.lgbt` domain because LGBT
|
|
||||||
rights are human rights.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
I have also set up a landing page at
|
|
||||||
[trisiel.com](https://trisiel.com) and a twitter account at
|
|
||||||
[@trisielcloud](https://twitter.com/trisielcloud). Right now these are
|
|
||||||
placeholders. I wanted to register the domains before they were taken by anyone
|
|
||||||
else.
|
|
||||||
|
|
||||||
## Architecture
|
|
||||||
|
|
||||||
My previous attempt at Trisiel had more of a four tier webapp setup. The
|
|
||||||
overall stack looked something like this:
|
|
||||||
|
|
||||||
- Nginx in front of everything
|
|
||||||
- The api server that did about everything
|
|
||||||
- The executors that waited on message queues to run code and push results to
|
|
||||||
the requester
|
|
||||||
- Postgres
|
|
||||||
- A message queue to communicate with the executors
|
|
||||||
- IPFS to store WebAssembly modules
|
|
||||||
|
|
||||||
In simple testing, this works amazingly. The API server will send execution
|
|
||||||
requests to the executors and everything will usually work out. However, the
|
|
||||||
message queue I used was very "fire and forget" and had difficulties with
|
|
||||||
multiple executors set up to listen on the queue. Additionally, the added
|
|
||||||
indirection of needing to send the data around twice means that it would have
|
|
||||||
difficulties scaling globally due to ingress and egress data costs. This model
|
|
||||||
is solid and _probably would have worked_ with some compression or other
|
|
||||||
improvements like that, but overall I was not happy with it and decided to scrap
|
|
||||||
it while I was porting the executor component to Rust. If you want to read the
|
|
||||||
source code of this iteration of Trisiel, take a look
|
|
||||||
[here](https://tulpa.dev/within/wasmcloud).
|
|
||||||
|
|
||||||
The new architecture of Trisiel looks something like this:
|
|
||||||
|
|
||||||
- Nginx in front of everything
|
|
||||||
- An API server that handles login with my gitea instance
|
|
||||||
- The executor server that listens over https
|
|
||||||
- Postgres
|
|
||||||
- Backblaze B2 to store WebAssembly modules
|
|
||||||
|
|
||||||
The main change here is the fact that the executor listens over HTTPS, avoiding
|
|
||||||
_a lot_ of the overhead involved in running this on a message queue. It's also
|
|
||||||
much simpler to implement and allows me to reuse a vast majority of the
|
|
||||||
boilerplate that I developed for the Trisiel API server.
|
|
||||||
|
|
||||||
This new version of Trisiel is also built on top of
|
|
||||||
[Wasmer](https://wasmer.io/). Wasmer is a seriously fantastic library for this
|
|
||||||
and getting up and running was absolutely trivial, even though I knew very
|
|
||||||
little Rust when I was writing [pa'i](/blog/pahi-hello-world-2020-02-22). I
|
|
||||||
cannot recommend it enough if you ever want to execute WebAssembly on a server.
|
|
||||||
|
|
||||||
## Roadmap
|
|
||||||
|
|
||||||
At this point, I can create new functions, upload them to the API server and
|
|
||||||
then trigger them to be executed. The output of those functions is not returned
|
|
||||||
to the user at this point. I am working on ways to implement that. There is also
|
|
||||||
very little accounting for what resources and system calls are used, however it
|
|
||||||
does keep track of execution time. The executor also needs to have the request
|
|
||||||
body of the client be wired to the standard in of the underlying module, which
|
|
||||||
will enable me to parse CGI replies from WebAssembly functions. This will allow
|
|
||||||
you to host HTTP endpoints on Trisiel using the same code that powers
|
|
||||||
[this](https://olin.within.website) and
|
|
||||||
[this](http://cetacean.club/cgi-bin/olinfetch.wasm).
|
|
||||||
|
|
||||||
I also need to go in and completely refactor the
|
|
||||||
[olin](https://github.com/Xe/pahi/tree/main/wasm/olin/src) crate and make the
|
|
||||||
APIs much more ergonomic, not to mention make the HTTP client actually work
|
|
||||||
again.
|
|
||||||
|
|
||||||
Then comes the documentation. Oh god there will be so much documentation. I will
|
|
||||||
be _drowning_ in documentation by the end of this.
|
|
||||||
|
|
||||||
I need to write the panel and command line tool for Trisiel. I want to write
|
|
||||||
the panel in [Elm](https://elm-lang.org/) and the command line tool in Rust.
|
|
||||||
|
|
||||||
There is basically zero validation for anything submitted to the Trisiel API.
|
|
||||||
I will need to write validation in order to make it safer.
|
|
||||||
|
|
||||||
I may also explore enabling support for [WASI](https://wasi.dev/) in the future,
|
|
||||||
but as I have stated before I do not believe that WASI works very well for the
|
|
||||||
futuristic plan-9 inspired model I want to use on Trisiel.
|
|
||||||
|
|
||||||
Right now the executor shells out to pa'i, but I want to embed pa'i into the
|
|
||||||
executor binary so there are fewer moving parts involved.
|
|
||||||
|
|
||||||
I also need to figure out what I should do with this project in general. It
|
|
||||||
feels like it is close to being productizable, but I am in a very bad stage of
|
|
||||||
my life to be able to jump in headfirst and build a company around this. Visa
|
|
||||||
limitations also don't help here.
|
|
||||||
|
|
||||||
## Things I Learned
|
|
||||||
|
|
||||||
[Rocket](https://rocket.rs) is an absolutely fantastic web framework and I
|
|
||||||
cannot recommend it enough. I am able to save _so much time_ with Rocket and its
|
|
||||||
slightly magic use of proc-macros. For an example, here is the entire source
|
|
||||||
code of the `/whoami` route in the Trisiel API:
|
|
||||||
|
|
||||||
```rust
|
|
||||||
#[get("/whoami")]
|
|
||||||
#[instrument]
|
|
||||||
pub fn whoami(user: models::User) -> Json<models::User> {
|
|
||||||
Json(user)
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
The `FromRequest` instance I have on my database user model allows me to inject
|
|
||||||
the user associated with an API token purely based on the (validated against the
|
|
||||||
database) claims associated with the JSON Web Token that the user uses for
|
|
||||||
authentication. This then allows me to make API routes protected by simply
|
|
||||||
putting the user model as an input to the handler function. It's magic and I
|
|
||||||
love it.
|
|
||||||
|
|
||||||
Postgres lets you use triggers to automatically update `updated_at` fields for
|
|
||||||
free. You just need a function that looks like this:
|
|
||||||
|
|
||||||
```sql
|
|
||||||
CREATE OR REPLACE FUNCTION trigger_set_timestamp()
|
|
||||||
RETURNS TRIGGER AS $$
|
|
||||||
BEGIN
|
|
||||||
NEW.updated_at = NOW();
|
|
||||||
RETURN NEW;
|
|
||||||
END;
|
|
||||||
$$ LANGUAGE plpgsql;
|
|
||||||
```
|
|
||||||
|
|
||||||
And then you can make triggers for your tables like this:
|
|
||||||
|
|
||||||
```sql
|
|
||||||
CREATE TRIGGER set_timestamp_users
|
|
||||||
BEFORE UPDATE ON users
|
|
||||||
FOR EACH ROW
|
|
||||||
EXECUTE PROCEDURE trigger_set_timestamp();
|
|
||||||
```
|
|
||||||
|
|
||||||
Every table in Trisiel uses this in order to make programming against the
|
|
||||||
database easier.
|
|
||||||
|
|
||||||
The symbol/number layer on my Moonlander has been _so good_. It looks something
|
|
||||||
like this:
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
And it makes using programming sigils _so much easier_. I don't have to stray
|
|
||||||
far from the homerow to hit the most common ones. The only one that I still have
|
|
||||||
to reach for is `_`, but I think I will bind that to the blank key under the `]`
|
|
||||||
key.
|
|
||||||
|
|
||||||
The best programming music is [lofi hip hop radio - beats to study/relax
|
|
||||||
to](https://www.youtube.com/watch?v=5qap5aO4i9A). Second best is [Animal
|
|
||||||
Crossing music](https://www.youtube.com/watch?v=2nYNJLfktds). They both have
|
|
||||||
this upbeat quality that makes the ideas melt into code and flow out of your
|
|
||||||
hands.
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
Overall I'd say this is pretty good for a week of hacking while learning a new
|
|
||||||
keyboard layout. I will do more in the future. I have plans. To read through the
|
|
||||||
(admittedly kinda hacky/awful) code I've written this week, check out [this git
|
|
||||||
repo](https://tulpa.dev/wasmcloud/wasmcloud). If you have any feedback, please
|
|
||||||
[contact me](/contact). I will be happy to answer any questions.
|
|
||||||
|
|
||||||
As far as signups go, I am not accepting any signups at the moment. This is
|
|
||||||
pre-alpha software. The abuse story will need to be figured out, but I am fairly
|
|
||||||
sure it will end up being some kind of "pay or you can only run the precompiled
|
|
||||||
example code in the documentation" with some kind of application process for the
|
|
||||||
"free tier" of Trisiel. Of course, this is all theoretical and hinges on
|
|
||||||
Trisiel actually being productizable; so who knows?
|
|
||||||
|
|
||||||
Be well.
|
|
||||||
|
|
@ -1,54 +0,0 @@
|
||||||
---
|
|
||||||
title: "Site Update: WebMention Support"
|
|
||||||
date: 2020-12-02
|
|
||||||
tags:
|
|
||||||
- indieweb
|
|
||||||
---
|
|
||||||
|
|
||||||
# Site Update: WebMention Support
|
|
||||||
|
|
||||||
Recently in my [Various Updates](/blog/various-updates-2020-11-18) post I
|
|
||||||
announced that my website had gotten
|
|
||||||
[WebMention](https://www.w3.org/TR/webmention/) support. Today I implemented
|
|
||||||
WebMention integration into blog articles, allowing you to see where my articles
|
|
||||||
are mentioned across the internet. This will not work with every single mention
|
|
||||||
of my site, but if your publishing platform supports sending WebMentions, then
|
|
||||||
you will see them show up on the next deploy of my site.
|
|
||||||
|
|
||||||
Thanks to the work of the folks at [Bridgy](https://brid.gy/), I have been able
|
|
||||||
to also keep track of mentions of my content across Twitter, Reddit and
|
|
||||||
Mastodon. My WebMention service will also attempt to resolve Bridgy mention
|
|
||||||
links to their original sources as much as it can. Hopefully this should allow
|
|
||||||
you to post my articles as normal across those networks and have those mentions
|
|
||||||
be recorded without having to do anything else.
|
|
||||||
|
|
||||||
As I mentioned before, this is implemented on top of
|
|
||||||
[mi](https://github.com/Xe/mi). mi receives mentions sent to
|
|
||||||
`https://mi.within.website/api/webmention/accept` and will return a reference
|
|
||||||
URL in the `Location` header. This will return JSON-formatted data about the
|
|
||||||
mention. Here is an example:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ curl https://mi.within.website/api/webmention/01ERGGEG7DCKRH3R7DH4BXZ6R9 | jq
|
|
||||||
{
|
|
||||||
"id": "01ERGGEG7DCKRH3R7DH4BXZ6R9",
|
|
||||||
"source_url": "https://maya.land/responses/2020/12/01/i-think-this-blog-post-might-have-been.html",
|
|
||||||
"target_url": "https://christine.website/blog/toast-sandwich-recipe-2019-12-02",
|
|
||||||
"title": null
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
This is all of the information I store about each WebMention. I am working on
|
|
||||||
title detection (using the
|
|
||||||
[readability](https://github.com/jangernert/readability) algorithm), however I
|
|
||||||
am unable to run JavaScript on my scraper server. Content that is JavaScript
|
|
||||||
only may not be able to be scraped like this.
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
Many thanks to [Chris Aldrich](https://boffosocko.com/2020/12/01/55781873/) for
|
|
||||||
inspiring me to push this feature to the end. Any articles that don't have any
|
|
||||||
WebMentions yet will link to the [WebMention
|
|
||||||
spec](https://www.w3.org/TR/webmention/).
|
|
||||||
|
|
||||||
Be well.
|
|
||||||
|
|
@ -1,311 +0,0 @@
|
||||||
---
|
|
||||||
title: "Why I Use Suckless Tools"
|
|
||||||
date: 2020-06-05
|
|
||||||
---
|
|
||||||
|
|
||||||
# Why I Use Suckless Tools
|
|
||||||
|
|
||||||
Software is complicated. Foundational building blocks of desktop environments
|
|
||||||
tend to grow year over year until it's difficult to understand or maintain them.
|
|
||||||
[Suckless][suckless] offers an alternative to this continuous cycle of bloat and
|
|
||||||
meaningless redesign. Suckless tools aim to keep things simple, minimal, usable
|
|
||||||
and hackable by default. Their window manager [dwm][dwm] is just a window
|
|
||||||
manager. It doesn't handle things like transparency, compositing or volume
|
|
||||||
control. Their terminal [st][st] is just a terminal. It doesn't handle fancy
|
|
||||||
things like ancient terminal kinds that died out long ago. It just displays
|
|
||||||
text. It doesn't handle things that tmux or similar could take care of, because
|
|
||||||
tmux can do a better job at that than st ever could on its own.
|
|
||||||
|
|
||||||
[suckless]: https://suckless.org/
|
|
||||||
[dwm]: https://dwm.suckless.org/
|
|
||||||
[st]: https://st.suckless.org/
|
|
||||||
|
|
||||||
Suckless tools are typically configured in C, the language they are written in.
|
|
||||||
However as a side effect of suckless tools having their configuration baked into
|
|
||||||
the executable at compile time, they start up _instantly_. If something goes
|
|
||||||
wrong while using them, you can easily jump right into the code that implements
|
|
||||||
them and nail down issues using basic debugger skills.
|
|
||||||
|
|
||||||
However, even though the window manager is meager, it still offers places for
|
|
||||||
you to make it look beautiful. For examples of beautiful dwm setups, see [this
|
|
||||||
search of /r/unixporn on reddit][unixporndwm].
|
|
||||||
|
|
||||||
[unixporndwm]: https://www.reddit.com/r/unixporn/search?q=dwm&restrict_sr=1
|
|
||||||
|
|
||||||
I would like to walk through my dwm setup, how I have it configured all of the
|
|
||||||
parts at play as well as an example of how I debug problems in my dwm config.
|
|
||||||
|
|
||||||
## My dwm Config
|
|
||||||
|
|
||||||
As dwm is configured in C, there's also a community of people creating
|
|
||||||
[patches][dwmpatches] for dwm that add extra features like additional tiling
|
|
||||||
methods, the ability to automatically start things with dwm, transparency for
|
|
||||||
the statusbar and so much more. I use the following patches:
|
|
||||||
|
|
||||||
[dwmpatches]: https://dwm.suckless.org/patches/
|
|
||||||
|
|
||||||
- [alpha](https://dwm.suckless.org/patches/alpha/)
|
|
||||||
- [autostart](https://dwm.suckless.org/patches/autostart/)
|
|
||||||
- [bottomstack](https://dwm.suckless.org/patches/bottomstack/)
|
|
||||||
- [dwmc](https://dwm.suckless.org/patches/dwmc/)
|
|
||||||
- [pertag](https://dwm.suckless.org/patches/pertag/)
|
|
||||||
- [systray](https://dwm.suckless.org/patches/systray/)
|
|
||||||
- [uselessgap](https://dwm.suckless.org/patches/uselessgap/)
|
|
||||||
|
|
||||||
This combination of patches allows me to make things feel comfortable and
|
|
||||||
predictable enough that I can rely entirely on muscle memory for most of my
|
|
||||||
window management. Nearly all of it is done with the keyboard too.
|
|
||||||
|
|
||||||
[Here][dwmconfig] is my config file. It's logically broken into two big sections:
|
|
||||||
|
|
||||||
[dwmconfig]: https://tulpa.dev/cadey/dwm/src/commit/8ea55d397459a865041b96d5b4933f426d010e6d/config.def.h
|
|
||||||
|
|
||||||
- Variables
|
|
||||||
- Keybinds
|
|
||||||
|
|
||||||
I'll go into more detail about these below.
|
|
||||||
|
|
||||||
### Variables
|
|
||||||
|
|
||||||
The main variables in my config control the following:
|
|
||||||
|
|
||||||
- border width
|
|
||||||
- size of the gaps when tiling windows
|
|
||||||
- the snap width
|
|
||||||
- system tray errata
|
|
||||||
- the location of the bar
|
|
||||||
- the fonts
|
|
||||||
- colors
|
|
||||||
- transparency values for the bar
|
|
||||||
- workspace names (mine are based off of the unicode emoticon `(ノ◕ヮ◕)ノ*:・゚✧`)
|
|
||||||
- app-specific hacks
|
|
||||||
- default settings for the tiling layouts
|
|
||||||
- if windows should be forced into place or not
|
|
||||||
- window layouts
|
|
||||||
|
|
||||||
All of these things control various errata. As a side effect of making them all
|
|
||||||
compile time constants, these settings don't have to be loaded into the program
|
|
||||||
because they're already a part of it. I use the [Hack][hackfont] font on my
|
|
||||||
desktop and with emacs.
|
|
||||||
|
|
||||||
[hackfont]: https://sourcefoundry.org/hack/
|
|
||||||
|
|
||||||
### Keybinds
|
|
||||||
|
|
||||||
The real magic of tiling window managers is that all of the window management
|
|
||||||
commands are done with my keyboard. Alt is the key I have devoted to controlling
|
|
||||||
the window manager. All of my window manager control chords use the alt key.
|
|
||||||
|
|
||||||
Here are the main commands and what they do:
|
|
||||||
|
|
||||||
| Command | Effect |
|
|
||||||
|--------------------------------------|------------------------------------------------------------------------------------------------------|
|
|
||||||
| Alt-p | Spawn a program by name |
|
|
||||||
| Alt-Shift-Enter | Open a new terminal window |
|
|
||||||
| Alt-b | Hide the bar if it is shown, show the bar if it is hidden |
|
|
||||||
| Alt-j | Move focus down the stack of windows |
|
|
||||||
| Alt-k | Move focus up the stack of windows |
|
|
||||||
| Alt-i | Increase the number of windows in the primary area |
|
|
||||||
| Alt-d | Decrease the number of windows in the primary area |
|
|
||||||
| Alt-h | Make the primary area smaller by 5% |
|
|
||||||
| Alt-l | Make the primary area larger by 5% |
|
|
||||||
| Alt-Enter | Move the currently active window into the primary area |
|
|
||||||
| Alt-Tab | Switch to the most recently active workspace |
|
|
||||||
| Alt-Shift-C | Nicely ask a window to close |
|
|
||||||
| Alt-t | Select normal tiling mode for the current workspace |
|
|
||||||
| Alt-f | Select floating (non-tiling) mode for the current workspace |
|
|
||||||
| Alt-m | Select monocle (fullscreen active window) mode for the current workspace |
|
|
||||||
| Alt-u | Select bottom-stacked tiling mode for the current workspace |
|
|
||||||
| Alt-o | Select bottom-stacked horizontal tiling mode for the current workspace (useful on vertical monitors) |
|
|
||||||
| Alt-e | Open a new emacs window |
|
|
||||||
| Alt-Space | Switch to the most recently used tiling method |
|
|
||||||
| Alt-Shift-Space | Detach the currently active window from tiling |
|
|
||||||
| Alt-1 thru Alt-9 | Switch to a given workspace |
|
|
||||||
| Alt-Shift-1 thru Alt-Shift-9 | Move the active window to a given workspace |
|
|
||||||
| Alt-0 | Show all windows on all workspaces |
|
|
||||||
| Alt-Shift-0 | Show the active window on all workspaces |
|
|
||||||
| Alt-Comma and Alt-Period | Move focus to the other monitor |
|
|
||||||
| Alt-Shift-Comma and Alt-Shift-Period | Move the active window to the other monitor |
|
|
||||||
| Alt-Shift-q | Uncleanly exit dwm and kill the session |
|
|
||||||
|
|
||||||
This is just enough commands that I can get things done, but not so many that I
|
|
||||||
get overwhelmed and forget what keybind does what. I have most of this committed
|
|
||||||
to muscle memory (and had to look at the config file to write out this table),
|
|
||||||
and as a result nearly all of my window management is done with my keyboard.
|
|
||||||
|
|
||||||
The rest of my config handles things like Alt-Right-Click to resize windows
|
|
||||||
arbitrarily, signals with dwmc and other overhead like that.
|
|
||||||
|
|
||||||
## The Other Parts
|
|
||||||
|
|
||||||
The rest of my desktop environment is built up using a few other tools that
|
|
||||||
build on top of dwm. You can see the NixOS modules I've made for it
|
|
||||||
[here](https://github.com/Xe/nixos-configs/blob/master/common/programs/dwm.nix)
|
|
||||||
and [here](https://github.com/Xe/nixos-configs/blob/master/common/users/cadey/dwm.nix):
|
|
||||||
|
|
||||||
- [xrandr](https://wiki.archlinux.org/index.php/Xrandr) to set up my multiple
|
|
||||||
monitors and rotation for them
|
|
||||||
- [feh](https://feh.finalrewind.org/) to set my wallpaper
|
|
||||||
- [picom](https://github.com/yshui/picom) to handle compositing effects like
|
|
||||||
transparency, blur and drop shadows for windows
|
|
||||||
- [pasystray](https://github.com/christophgysin/pasystray) for controlling my
|
|
||||||
system volume
|
|
||||||
- [dunst](https://dunst-project.org/) for notifications
|
|
||||||
- [xmodmap](https://wiki.archlinux.org/index.php/Xmodmap) for rebinding the caps
|
|
||||||
lock key to the escape key
|
|
||||||
- [cabytcini](https://tulpa.dev/cadey/cabytcini) to show the current time and
|
|
||||||
weather in my dwm bar
|
|
||||||
|
|
||||||
Each of these tools has their own place in the stack and they all work together
|
|
||||||
to give me a coherent and cohesive environment that I can use for Netflix,
|
|
||||||
programming, playing Steam games and more.
|
|
||||||
|
|
||||||
cabytcini is a program I created for myself as part of my goal to get more
|
|
||||||
familiar with Rust. As of the time of this post being written, it uses only 11
|
|
||||||
megabytes of ram and is configured using a config file located at
|
|
||||||
`~/.config/cabytcini/gaftercu'a.toml`. It scrapes data from the API server I use
|
|
||||||
for my wall-mounted clock to show me the weather in Montreal. I've been meaning
|
|
||||||
to write more about it, but it's currently only documented in Lojban.
|
|
||||||
|
|
||||||
## Debugging dwm
|
|
||||||
|
|
||||||
Software is imperfect, even smaller programs like dwm can still have bugs in
|
|
||||||
them. Here's the story of how I debugged and bisected a problem with [my dwm
|
|
||||||
config](https://tulpa.dev/cadey/dwm) recently.
|
|
||||||
|
|
||||||
I had just gotten the second monitor set up and noticed that whenever I sent a
|
|
||||||
window to it, the entire window manager seemed to get locked up. I tried sending
|
|
||||||
the quit command to see if it would respond to that, and it failed. I opened up
|
|
||||||
a virtual terminal with control-alt-F1 and logged in there, then I launched
|
|
||||||
[htop](https://hisham.hm/htop/) to see if the process was blocked.
|
|
||||||
|
|
||||||
It reported dwm was using 100% CPU. This was odd. I then decided to break out
|
|
||||||
the debugger and see what was going on. I attached to the dwm process with `gdb
|
|
||||||
-p (pgrep dwm)` and then ran `bt full` to see where it was stuck.
|
|
||||||
|
|
||||||
The backtrace revealed it was stuck in the `drawbar()` function. It was stuck in
|
|
||||||
a loop that looked something like this:
|
|
||||||
|
|
||||||
```c
|
|
||||||
for (c = m->clients; c; c = c->next) {
|
|
||||||
occ |= c->tags;
|
|
||||||
if (c->isurgent)
|
|
||||||
urg |= c->tags;
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
dwm stores the list of clients per tag in a singly linked list, so the root
|
|
||||||
cause could be related to a circular linked list somehow, right?
|
|
||||||
|
|
||||||
I decided to check this by printing `c` and `c->next` in GDB to see what was
|
|
||||||
going on:
|
|
||||||
|
|
||||||
```
|
|
||||||
gdb> print c
|
|
||||||
0xfad34f
|
|
||||||
gdb> print c->next
|
|
||||||
0xfad34f
|
|
||||||
```
|
|
||||||
|
|
||||||
The linked list was circular. dwm was stuck iterating an infinite loop. I looked
|
|
||||||
at the type of `c` and saw it was something like this:
|
|
||||||
|
|
||||||
```c
|
|
||||||
struct Client {
|
|
||||||
char name[256];
|
|
||||||
float mina, maxa;
|
|
||||||
float cfact;
|
|
||||||
int x, y, w, h;
|
|
||||||
int oldx, oldy, oldw, oldh;
|
|
||||||
int basew, baseh, incw, inch, maxw, maxh, minw, minh;
|
|
||||||
int bw, oldbw;
|
|
||||||
unsigned int tags;
|
|
||||||
int isfixed, isfloating, isurgent, neverfocus, oldstate, isfullscreen;
|
|
||||||
Client *next;
|
|
||||||
Client *snext;
|
|
||||||
Monitor *mon;
|
|
||||||
Window win;
|
|
||||||
};
|
|
||||||
```
|
|
||||||
|
|
||||||
So, `next` is a pointer to the next client (if it exists). Setting the pointer
|
|
||||||
to `NULL` would probably break dwm out of the infinite loop. So I decided to
|
|
||||||
test that by running:
|
|
||||||
|
|
||||||
```
|
|
||||||
gdb> set var c->next = 0x0
|
|
||||||
```
|
|
||||||
|
|
||||||
To set the next pointer to null. dwm immediately got unstuck and exited
|
|
||||||
(apparently my quit command from earlier got buffered), causing the login screen
|
|
||||||
to show up. I was able to conclude that something was wrong with my dwm setup.
|
|
||||||
|
|
||||||
I know this behavior worked on release versions of dwm, so I decided to load up
|
|
||||||
KDE and then take a look at what was going on with [Xephyr][xephyr] and [git
|
|
||||||
bisect][gitbisect].
|
|
||||||
|
|
||||||
[xephyr]: https://wiki.archlinux.org/index.php/Xephyr
|
|
||||||
[gitbisect]: https://www.metaltoad.com/blog/beginners-guide-git-bisect-process-elimination
|
|
||||||
|
|
||||||
I created two fake monitors with Xephyr:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ Xephyr -br -ac -noreset -screen 800x600 -screen 800x600 +xinerama :1 &
|
|
||||||
```
|
|
||||||
|
|
||||||
And then started to git bisect my dwm fork:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ cd ~/code/cadey/dwm
|
|
||||||
$ git bisect init
|
|
||||||
$ git bisect bad HEAD
|
|
||||||
$ git bisect good cb3f58ad06993f7ef3a7d8f61468012e2b786cab
|
|
||||||
```
|
|
||||||
|
|
||||||
I registered the bad commit (the current one) and the last known good commit
|
|
||||||
(from when [dwm 6.2 was
|
|
||||||
released](https://tulpa.dev/cadey/dwm/commit/cb3f58ad06993f7ef3a7d8f61468012e2b786cab))
|
|
||||||
and started to recreate the conditions of the hang.
|
|
||||||
|
|
||||||
I set the `DISPLAY` environment variable so that dwm would use the fake
|
|
||||||
monitors:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ export DISPLAY=:1
|
|
||||||
```
|
|
||||||
|
|
||||||
and then rebuilt/ran dwm:
|
|
||||||
|
|
||||||
```console
|
|
||||||
$ make clean && rm config.h && make && ./dwm
|
|
||||||
```
|
|
||||||
|
|
||||||
Once I had dwm up and running, I created a terminal window and tried to send it
|
|
||||||
to the other screen. If it worked, I marked the commit as good with `git bisect
|
|
||||||
good`, and if it hung I marked the commit as bad with `git bisect bad`. 7
|
|
||||||
iterations later and I found out that the [attachbelow][attachbelow] patch was
|
|
||||||
the culprit.
|
|
||||||
|
|
||||||
[attachbelow]: https://dwm.suckless.org/patches/attachbelow/
|
|
||||||
|
|
||||||
I reverted the patch on the master branch, rebuilt and re-ran dwm and tried to
|
|
||||||
send the terminal window between the fake monitors. It worked every time. Then I
|
|
||||||
committed the revert of attachbelow, pushed it to my [NUR
|
|
||||||
repo](https://github.com/Xe/xepkgs/commit/c3bffbc8a3ebbaf13bee60e00c8002934d89e803),
|
|
||||||
and then rebuilt my tower's config once it passed CI.
|
|
||||||
|
|
||||||
Being a good internet citizen, I reported this to the [suckless mailing
|
|
||||||
list](https://lists.suckless.org/dev/2006/33946.html) and then was able to get a
|
|
||||||
reply back not only confirming the bug, but also with [a patch for the
|
|
||||||
patch](https://lists.suckless.org/dev/2006/33947.html) to fix the
|
|
||||||
behavior forever. I have yet to integrate this meta-patch into my dwm fork, but
|
|
||||||
I'll probably get around to it someday.
|
|
||||||
|
|
||||||
This really demonstrates one of the core tenets of the suckless philosophy
|
|
||||||
perfectly. I am not very familiar with how the dwm codebase works, but I am able
|
|
||||||
to dig into its guts and diagnose/fix things because it is intentionally kept as
|
|
||||||
simple as possible.
|
|
||||||
|
|
||||||
If you use Linux on a desktop/laptop, I highly suggest taking a look at
|
|
||||||
suckless software and experimenting with it. It is super optimized for
|
|
||||||
understandability and hacking, which is a huge breath of fresh air these days.
|
|
||||||
|
|
@ -1,233 +0,0 @@
|
||||||
---
|
|
||||||
title: Why Rust
|
|
||||||
date: 2020-02-15
|
|
||||||
tags:
|
|
||||||
- rust
|
|
||||||
- rant
|
|
||||||
- satori
|
|
||||||
- golang
|
|
||||||
---
|
|
||||||
|
|
||||||
# Why Rust
|
|
||||||
|
|
||||||
Or: A Trip Report from my Satori with Rust and Functional Programming
|
|
||||||
|
|
||||||
Software is a very odd field to work in. It is simultaneously an abstract and
|
|
||||||
physical one. You build systems that can deal with an unfathomable amount of
|
|
||||||
input and output at the same time. As a job, I peer into the madness of an
|
|
||||||
unthinking automaton and give order to the inherent chaos. I then emit
|
|
||||||
incantations to describe what this unthinking automaton should do in my stead. I
|
|
||||||
cannot possibly track the relations between a hundred thousand transactions
|
|
||||||
going on in real time, much less file them appropriately so they can be summoned
|
|
||||||
back should the need arise.
|
|
||||||
|
|
||||||
However, this incantation (by necessity) is an _unthinkably_ precise and fickle
|
|
||||||
beast. It's almost as if you are training a four-year old to go to the store,
|
|
||||||
but doing it by having them read a grocery list. This grocery list has to be
|
|
||||||
precise enough that the four year old ends up getting what you want and not a
|
|
||||||
cart full of frosted flakes and candy bars. But, at the same time, the four year
|
|
||||||
old needs to understand it. Thus, the precision.
|
|
||||||
|
|
||||||
There's many schools of thought around ways to write the grocery list. Some
|
|
||||||
follow a radically simple approach, relying on the toddler to figure things out
|
|
||||||
at the store. Sometimes this simpler approach doesn't work out in more obscure
|
|
||||||
scenarios, like when they are out of red grapes but do have green grapes, but it
|
|
||||||
tends to work out enough. Proponents of these list-making tools also will
|
|
||||||
advocate for doing full tests of the grocery list before they send the toddler
|
|
||||||
off to the store. This means setting up a fake grocery store with funny money, a
|
|
||||||
fake card, plastic food, the whole nine yards. This can get expensive and can
|
|
||||||
become a logistical issue (where are you going to store all that plastic fruit
|
|
||||||
in a way that you can just set up and tear down the grocery store mock so
|
|
||||||
quickly?).
|
|
||||||
|
|
||||||
Another school of thought is that the process of writing the grocery list should
|
|
||||||
be done in a way that prevents ambiguity at the grocery store. This kind of flow
|
|
||||||
uses some more advanced concepts like the ability to describe something by its
|
|
||||||
attributes. For example, this could specify the difference between fruit and
|
|
||||||
vegetables, and only allow fruit to be put in one place of the cart and only
|
|
||||||
allow vegetables to be placed in the other. And if the writer of the list tries
|
|
||||||
to violate this, the list gets rejected and isn't used at all.
|
|
||||||
|
|
||||||
There is yet another school of thought that decides that the exact spatial
|
|
||||||
position of the toddler relative to everything else should be thought of in
|
|
||||||
advance, along with a process to make sure that nothing is done in an improper
|
|
||||||
way. This means writing the list can be a lot harder at first, but it's much
|
|
||||||
less likely to result in the toddler coming back with a weird state. Consider
|
|
||||||
what happens if two items show up at the same time and the toddler tries to grab
|
|
||||||
both of them at the same time due to the instructions in the list! They only
|
|
||||||
have one arm to grab things with, so it just doesn't work. Proponents of the
|
|
||||||
more strict methods have reference cells and other mechanisms to ensure that the
|
|
||||||
toddler can only ever grab one thing at a time.
|
|
||||||
|
|
||||||
If we were to match these three ludicrous examples to programming languages, the
|
|
||||||
first would be Lua, the second would be Go and the third would be something like
|
|
||||||
Haskell or Rust. Software development is a complicated process because the
|
|
||||||
problems involved with directing that unthinking automaton to do what you want
|
|
||||||
are hard. There is a lot going on, much in the same way there is a lot going on
|
|
||||||
when you send a toddler to do your grocery shopping for you.
|
|
||||||
|
|
||||||
A good way to look at the tradeoffs involved is to see things as a balance
|
|
||||||
between two forces, pragmatism and correctness. Languages that are more
|
|
||||||
pragmatic are easier to develop in, but are mathematically more likely to run
|
|
||||||
into problems at runtime. Languages that are more correct take more investment
|
|
||||||
to write up front, but over time the correctness means that there's fewer failed
|
|
||||||
assumptions about what is going on. The compiler stops you from doing things
|
|
||||||
that don't make sense to it. This means that it's difficult to literally
|
|
||||||
impossible to create a bad state at runtime.
|
|
||||||
|
|
||||||
Tools like Lua and Go can (and have) been used to develop stable and viable
|
|
||||||
software. [itch.io][itchio] is written in Lua running on top of nginx and it
|
|
||||||
handles financial transactions well enough that it's turned into the guy's full
|
|
||||||
time job. Google uses Go everywhere in their stack, and it's been used to create
|
|
||||||
powerful tools like Kubernetes, Caddy, and Docker. These tools are trusted
|
|
||||||
implicitly by a generation of developers, even though the language itself has
|
|
||||||
its flaws. If you are reading this blog in Firefox, statistically there is Rust
|
|
||||||
involved in the rendering and viewing of this post. Rust is built for ensuring
|
|
||||||
that code is _as correct as possible_, even if it means eating into development
|
|
||||||
time to ensure that.
|
|
||||||
|
|
||||||
[itchio]: https://itch.io
|
|
||||||
|
|
||||||
In Rust, you don't have to memorize rules about how and when it is safe to
|
|
||||||
update data in structures, because the compiler ensures you _cannot mess it up
|
|
||||||
by rejecting the code if you could be messing it up_. You don't have to run your
|
|
||||||
tests with a race detector or figure out how to expose that in production to
|
|
||||||
trace down that obscure double-write to a non-threadsafe hashmap, because in
|
|
||||||
Rust there is no such thing as a non-threadsafe hashmap. There is only a safe
|
|
||||||
hashmap and only can ever be a safe hashmap.
|
|
||||||
|
|
||||||
As an absurd example, consider the following two snippets of code, one in Go and
|
|
||||||
one in Rust, both of them will put integers into a standard library list and
|
|
||||||
then print them all out:
|
|
||||||
|
|
||||||
```go
|
|
||||||
l := list.New() // () -> *list.List
|
|
||||||
for i := 0; i < 5; i++ {
|
|
||||||
l.PushBack(i) // interface{} -> ()
|
|
||||||
}
|
|
||||||
|
|
||||||
for e := l.Front(); e != nil; e = e.Next() {
|
|
||||||
log.Printf("%T: %v", e.Value, e.Value)
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
```rust
|
|
||||||
let mut vec = Vec::new::<i64>(); // () -> Vec<i64>
|
|
||||||
|
|
||||||
for i in 0..5 {
|
|
||||||
vec.push(i as i64); // (mut Vec<i64>, i64) -> ()
|
|
||||||
}
|
|
||||||
|
|
||||||
for i in vec.iter() {
|
|
||||||
println!("{}", i);
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
The Go version uses `interface{}` as the data element because Go [literally
|
|
||||||
cannot describe types as parameters to functions][gonerics]. The Rust version
|
|
||||||
took me a bit longer to write, but there is _no_ ambiguity as to what the vector
|
|
||||||
holds. The Go version can also hold multiple types of data in the same list,
|
|
||||||
a-la:
|
|
||||||
|
|
||||||
[gonerics]: https://golang.org/doc/faq#generics
|
|
||||||
|
|
||||||
```go
|
|
||||||
l := list.New()
|
|
||||||
l.PushBack(42)
|
|
||||||
l.PushBack("hotdogs")
|
|
||||||
l.PushBack(420.69)
|
|
||||||
```
|
|
||||||
|
|
||||||
All of which is valid because in Go, an `interface{}` matches _every kind of
|
|
||||||
value possible_. An integer is an `interface{}`. A floating-point number is an
|
|
||||||
`interface{}`. A string is an `interface{}`. A bool is an `interface{}`. Any
|
|
||||||
custom type you create is an `interface{}`. Normally, this would be very
|
|
||||||
restrictive and make it difficult to do things like JSON parsing. However the Go
|
|
||||||
runtime lets you hack around this with [reflection][wtfisreflection].
|
|
||||||
|
|
||||||
[wtfisreflection]: https://golangbot.com/reflection/
|
|
||||||
|
|
||||||
This allows the standard library to handle things like JSON parsing with
|
|
||||||
functions [that look like this](https://godoc.org/encoding/json#Unmarshal):
|
|
||||||
|
|
||||||
```
|
|
||||||
func Unmarshal(data []byte, v interface{}) error
|
|
||||||
```
|
|
||||||
|
|
||||||
There's even a set of complicated rules you need to memorize about how to trick
|
|
||||||
the JSON parser into massaging your data into place. This lets you do things
|
|
||||||
like this:
|
|
||||||
|
|
||||||
```go
|
|
||||||
type Rilkef struct {
|
|
||||||
Foo string `json:"foo"`
|
|
||||||
CallToArms string `json:"call_to_arms"`
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
This allows the programmer a lot of flexibility while developing and compiling
|
|
||||||
the code. It's very easy for the compiler to say "oh, hey, that could be
|
|
||||||
anything, and you gave it some kind of anything, sounds legit to me", but then
|
|
||||||
the job of ensuring the sanity of the inputs is shunted to _runtime_ rather than
|
|
||||||
stopped before the code gets deployed. This means you need to test the code in
|
|
||||||
order to see how it behaves, making sure that _the standard library is doing its
|
|
||||||
job correctly_. This kind of stuff does not happen in Rust.
|
|
||||||
|
|
||||||
The Rust version of this JSON example uses the [serde][serde] and
|
|
||||||
[serde_json][serdejson] libraries:
|
|
||||||
|
|
||||||
[serde]: https://serde.rs
|
|
||||||
[serdejson]: https://serde.rs/json.html
|
|
||||||
|
|
||||||
```rust
|
|
||||||
use serde::*;
|
|
||||||
|
|
||||||
#[derive(Serialize, Deserialize)]
|
|
||||||
pub struct Rilkef {
|
|
||||||
pub foo: String,
|
|
||||||
pub call_to_arms: String,
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
And the logic for handling the correct rules for serialization and
|
|
||||||
deserialization is handled at _compile time_ by the compiler itself. Serde also
|
|
||||||
allows you to support more than just JSON, so this same type can be reused for
|
|
||||||
Dhall, YAML or whatever you could imagine.
|
|
||||||
|
|
||||||
## tl;dr
|
|
||||||
|
|
||||||
Rust allows for more correctness at the cost of developer efficiency. This is a
|
|
||||||
tradeoff, but I think it may actually be worth it. Code that is more correct is
|
|
||||||
more robust and less prone to failure than code that is less correct. This leads
|
|
||||||
to software that is less likely to crash at 3 am and wake you up due to a
|
|
||||||
preventable developer error.
|
|
||||||
|
|
||||||
After working in Go for more than half a decade, I'm starting to think that it
|
|
||||||
is probably a better idea to impact developer velocity and force them to write
|
|
||||||
software that is more correct. Go works if you are careful about how you handle
|
|
||||||
it. It however amounts to a giant list of rules that you just have to know (like
|
|
||||||
maps not being threadsafe) and a lot of those rules come from battle rather than
|
|
||||||
from the development process.
|
|
||||||
|
|
||||||
This came out as more of a rant than I had thought it would, but overall I hope
|
|
||||||
my point isn't lost.
|
|
||||||
|
|
||||||
### Things You Might Complain About
|
|
||||||
|
|
||||||
Yes, I know slices exist in Go. I wanted to prove a point about how the overuse
|
|
||||||
of `interface{}` in some relatively core things (like generic lists) can cause
|
|
||||||
headaches in term of correctness. Go will reject you trying to append a string
|
|
||||||
to an integer slice, but you cannot create a type that functions identically to
|
|
||||||
an integer slice.
|
|
||||||
|
|
||||||
Go does have a race detector that will point out a lot of sins in concurrent
|
|
||||||
programs, but that is again at _runtime_, not at _compile time_.
|
|
||||||
|
|
||||||
---
|
|
||||||
|
|
||||||
Many thanks to Tene, Sr. Oracle, A. Wilfox, Byte-slice, SiIvagunner and anyone
|
|
||||||
who watched the stream where I wrote this blogpost. If I got things wrong in
|
|
||||||
this, please [reach out to me](/contact) to let me know what I messed up. This
|
|
||||||
is a composite of a few twitter threads and a conversation I had on IRC.
|
|
||||||
|
|
||||||
Thanks for reading, be well.
|
|
||||||
|
|
@ -1,220 +0,0 @@
|
||||||
---
|
|
||||||
title: The Within Go Repo Layout
|
|
||||||
date: 2020-09-07
|
|
||||||
series: howto
|
|
||||||
tags:
|
|
||||||
- go
|
|
||||||
- standards
|
|
||||||
---
|
|
||||||
|
|
||||||
# The Within Go Repo Layout
|
|
||||||
|
|
||||||
Go repository layout is a very different thing compared to other languages.
|
|
||||||
There's a lot of conflicting opinions and little firm guidance to help steer
|
|
||||||
people along a path to more maintainable code. This is a collection of
|
|
||||||
guidelines that help to facilitate understandable and idiomatic Go.
|
|
||||||
|
|
||||||
At a high level the following principles should be followed:
|
|
||||||
|
|
||||||
- If the code is designed to be consumed by other random people using that
|
|
||||||
repository, it is made available for others to import
|
|
||||||
- If the code is NOT designed to be consumed by other random people using that
|
|
||||||
repository, it is NOT made available for others to import
|
|
||||||
- Code should be as close to where it's used as possible
|
|
||||||
- Documentation helps understand _why_, not _how_
|
|
||||||
- More people can reuse your code than you think
|
|
||||||
|
|
||||||
## Folder Structure
|
|
||||||
|
|
||||||
At a minimum, the following folders should be present in the repository:
|
|
||||||
|
|
||||||
- `cmd/` -> houses executable commands
|
|
||||||
- `docs/` -> houses human readable documentation
|
|
||||||
- `internal/` -> houses code not intended to be used by others
|
|
||||||
- `scripts/` -> houses any scripts needed for meta-operations
|
|
||||||
|
|
||||||
Any additional code can be placed anywhere in the repo as long as it makes
|
|
||||||
sense. More on this later in the document.
|
|
||||||
|
|
||||||
## Additional Code
|
|
||||||
|
|
||||||
If there is code that should be available for other people outside of this
|
|
||||||
project to use, it is better to make it a publicly available (not internal)
|
|
||||||
package. If the code is also used across multiple parts of your program or is
|
|
||||||
only intended for outside use, it should be in the repository root. If not, it
|
|
||||||
should be as close to where it is used as makes sense. Consider this directory
|
|
||||||
layout:
|
|
||||||
|
|
||||||
```
|
|
||||||
repo-root
|
|
||||||
├── cmd
|
|
||||||
│ ├── paperwork
|
|
||||||
│ │ ├── create
|
|
||||||
│ │ │ └── create.go
|
|
||||||
│ │ └── main.go
|
|
||||||
│ ├── hospital
|
|
||||||
│ │ ├── internal
|
|
||||||
│ │ │ └── operate.go
|
|
||||||
│ │ └── main.go
|
|
||||||
│ └── integrator
|
|
||||||
│ ├── integrate.go
|
|
||||||
│ └── main.go
|
|
||||||
├── internal
|
|
||||||
│ └── log_manipulate.go
|
|
||||||
└── web
|
|
||||||
├── error.go
|
|
||||||
└── instrument.go
|
|
||||||
```
|
|
||||||
|
|
||||||
This would expose packages `repo-root/web` and `repo-root/cmd/paperwork/create`
|
|
||||||
to be consumed by outside users. This would allow reuse of the error handling in
|
|
||||||
package `web`, but it would not allow reuse of whatever manipulation is done to
|
|
||||||
logging in package `repo-root/internal`.
|
|
||||||
|
|
||||||
## `repo-root/cmd/`
|
|
||||||
|
|
||||||
This folder has subfolders with go files in them. Each of these subfolders is
|
|
||||||
one command binary. The entrypoint of each command should be `main.go` so that
|
|
||||||
it is easy to identify in a directory listing. This follows how the [go standard
|
|
||||||
library][stdlibcmd] does this.
|
|
||||||
|
|
||||||
For example:
|
|
||||||
|
|
||||||
```
|
|
||||||
repo-root
|
|
||||||
└── cmd
|
|
||||||
├── paperwork
|
|
||||||
│ └── main.go
|
|
||||||
├── hospital
|
|
||||||
│ └── main.go
|
|
||||||
└── integrator
|
|
||||||
└── main.go
|
|
||||||
```
|
|
||||||
|
|
||||||
This would be for three commands named `paperwork`, `hospital`, and `integrate`
|
|
||||||
respectively.
|
|
||||||
|
|
||||||
As your commands get more complicated, it's tempting to create packages in
|
|
||||||
`repo-root/internal/` to implement them. This is probably a bad idea. It's
|
|
||||||
better to create the packages in the same folder as the command, or optionally
|
|
||||||
in its `internal` package. Consider if `paperwork` has a command named `create`,
|
|
||||||
`hospital` has a command named `operate` and `integrator` has a command named
|
|
||||||
`integrate`:
|
|
||||||
|
|
||||||
```
|
|
||||||
repo-root
|
|
||||||
└── cmd
|
|
||||||
├── paperwork
|
|
||||||
│ ├── create
|
|
||||||
│ │ └── create.go
|
|
||||||
│ └── main.go
|
|
||||||
├── hospital
|
|
||||||
│ ├── internal
|
|
||||||
│ │ └── operate.go
|
|
||||||
│ └── main.go
|
|
||||||
└── integrator
|
|
||||||
├── integrate.go
|
|
||||||
└── main.go
|
|
||||||
```
|
|
||||||
|
|
||||||
Each of these commands has the logic separated into different packages.
|
|
||||||
|
|
||||||
`paperwork` has the create command as a subpackage, meaning that other parts of the
|
|
||||||
application can consume that code if they need to.
|
|
||||||
|
|
||||||
`hospital` has the operate command inside its internal package, meaning [only
|
|
||||||
cmd/foo/ and anything that has the same import path prefix can use that
|
|
||||||
code][internalcode].
|
|
||||||
This makes it easier to isolate the code so that other parts of the repo
|
|
||||||
_cannot_ use it.
|
|
||||||
|
|
||||||
`integrator` has the integrate command as a separate go file in the main package of
|
|
||||||
the command. This makes the integrate command code only usable within the
|
|
||||||
command because main packages cannot be imported by other packages.
|
|
||||||
|
|
||||||
Each of these methods makes sense in some contexts and not in others. Real-world
|
|
||||||
usage will probably see a mix of these depending on what makes sense.
|
|
||||||
|
|
||||||
## `repo-root/docs/`
|
|
||||||
|
|
||||||
This folder has human-readable documentation files.
|
|
||||||
These files are intended to help humans understand how to
|
|
||||||
use the program or reasons why the program was put together the way it was. This
|
|
||||||
documentation should be in the language most common to the team of people
|
|
||||||
developing the software.
|
|
||||||
|
|
||||||
The structure inside this folder is going to be very organic, so it is not
|
|
||||||
entirely defined here.
|
|
||||||
|
|
||||||
## `repo-root/internal/`
|
|
||||||
|
|
||||||
The [internal folder should house code that others shouldn't
|
|
||||||
consume][internalcode]. This can be for many reasons. Generally if you cannot
|
|
||||||
see a use for this code outside the context of the program you are developing,
|
|
||||||
but it needs to be used across multiple packages in different areas of the repo,
|
|
||||||
it should default to going here.
|
|
||||||
|
|
||||||
If the code is safe for public consumption, it should go elsewhere.
|
|
||||||
|
|
||||||
## `repo-root/scripts/`
|
|
||||||
|
|
||||||
The scripts folder should contain each script that is needed for various
|
|
||||||
operations. This could be for running fully automated tests in a docker
|
|
||||||
container or packaging the program for distribution. These files should be
|
|
||||||
documented as makes sense.
|
|
||||||
|
|
||||||
## Test Code
|
|
||||||
|
|
||||||
Code should be tested in the same folder that it's written in. See the [upstream
|
|
||||||
testing documentation][gotest] for more information.
|
|
||||||
|
|
||||||
Integration tests or other things should be done in an internal subpackage
|
|
||||||
called "integration" or similar.f
|
|
||||||
|
|
||||||
## Questions and Answers
|
|
||||||
|
|
||||||
### Why not use `pkg/` for packages you intend others to use?
|
|
||||||
|
|
||||||
The name `pkg` is already well-known in the Go ecosystem. It is [the folder that
|
|
||||||
compiled packages (not command binaries) go][pkgfolder]. Using it creates the
|
|
||||||
potential for confusion between code that others are encouraged to use and the
|
|
||||||
meaning that the Go compiler toolchain has.
|
|
||||||
|
|
||||||
If a package prefix for publicly available code is really needed, choose a name
|
|
||||||
not already known to the Go compiler toolchain such as "public".
|
|
||||||
|
|
||||||
### How does this differ from https://github.com/golang-standards/project-layout?
|
|
||||||
|
|
||||||
This differs in a few key ways:
|
|
||||||
|
|
||||||
- Discourages the use of `pkg`, because it's obvious if something is publicly
|
|
||||||
available or not if it can be imported outside of the package
|
|
||||||
- Leaves the development team a lot more agency to decide how to name things
|
|
||||||
|
|
||||||
The core philosophy of this layout is that the developers should be able to
|
|
||||||
decide how to put files into the repository.
|
|
||||||
|
|
||||||
### But I really think I need `pkg`!
|
|
||||||
|
|
||||||
Set up another git repo for those libraries then. If they are so important that
|
|
||||||
other people need to use them, they should probably be in a `libraries` repo or
|
|
||||||
individual git repos.
|
|
||||||
|
|
||||||
Besides, nothing is stopping you from actually using `pkg` if you want to. Some
|
|
||||||
more experienced go programmers will protest though.
|
|
||||||
|
|
||||||
## Examples of This in Action
|
|
||||||
|
|
||||||
Here are a few examples of views of this layout in action:
|
|
||||||
|
|
||||||
- https://github.com/golang/go/tree/master/src
|
|
||||||
- https://github.com/golang/tools
|
|
||||||
- https://github.com/PonyvilleFM/aura
|
|
||||||
- https://github.com/Xe/ln
|
|
||||||
- https://github.com/goproxyio/goproxy
|
|
||||||
- https://github.com/heroku/x
|
|
||||||
|
|
||||||
[stdlibcmd]: https://github.com/golang/go/tree/master/src/cmd
|
|
||||||
[internalcode]: https://docs.google.com/document/d/1e8kOo3r51b2BWtTs_1uADIA5djfXhPT36s6eHVRIvaU/edit
|
|
||||||
[gotest]: https://golang.org/pkg/testing/
|
|
||||||
[pkgfolder]: https://www.digitalocean.com/community/tutorials/understanding-the-gopath
|
|
||||||
|
|
@ -1,76 +0,0 @@
|
||||||
---
|
|
||||||
title: ZSA Moonlander First Impressions
|
|
||||||
date: 2020-10-27
|
|
||||||
series: keeb
|
|
||||||
tags:
|
|
||||||
- moonlander
|
|
||||||
- keyboard
|
|
||||||
---
|
|
||||||
|
|
||||||
# ZSA Moonlander First Impressions
|
|
||||||
|
|
||||||
As I mentioned
|
|
||||||
[before](https://christine.website/blog/colemak-layout-2020-08-15), I ordered a
|
|
||||||
[ZSA Moonlander](https://zsa.io/moonlander) and it has finally arrived. I am
|
|
||||||
writing this post from my Moonlander, and as such I may do a few more typos
|
|
||||||
than normal, I'm still getting used to this.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
The Moonlander is a weird keyboard. I knew that it would be odd from the get-go
|
|
||||||
(split ergonomic keyboards have this reputation for a reason), but I was
|
|
||||||
surprised at how natural it feels. Setup was a breeze (unbox, plug it in, flash
|
|
||||||
firmware, type), and I have been experimenting with tenting angles on my desk.
|
|
||||||
It is a _very_ solid keyboard with basically zero deck flex.
|
|
||||||
|
|
||||||
I have a [fairly complicated
|
|
||||||
keymap](https://tulpa.dev/cadey/kadis-layouts/src/branch/master/moonlander) that
|
|
||||||
worked almost entirely on the first try. Here is a more user friendly
|
|
||||||
visualization of my keymap (sans fun things like leader macros):
|
|
||||||
|
|
||||||
<div style="padding-top: 60%; position: relative;">
|
|
||||||
<iframe src="https://configure.ergodox-ez.com/embed/moonlander/layouts/xbJXx/latest/0" style="border: 0; height: 100%; left: 0; position: absolute; top: 0; width: 100%"></iframe>
|
|
||||||
</div>
|
|
||||||
|
|
||||||
My typing speed has been destroyed by the change to this ortholinear layout.
|
|
||||||
Before I was getting around 70 words per minute at best (according to
|
|
||||||
[monkeytype.com](https://monkeytype.com/)), but now I am lucky to hit about 35
|
|
||||||
words per minute. My fingers kinda reach for where keys are on a staggered
|
|
||||||
keyboard and I have the most trouble with `x`, `v`, `.` and `b` at the moment. I
|
|
||||||
really like having a dedicated : key on my right hand. It makes command mode (and
|
|
||||||
yaml) so much easier. The larger red buttons are a bit odd to hit at the moment,
|
|
||||||
but I imagine that will get much easier with time.
|
|
||||||
|
|
||||||
Each key has a programmable RGB light under it. This allows you to get some
|
|
||||||
really nice effects like this:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
However brown colors don't come out as well as I'd hoped:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
I am not sure how I feel about the armrests. On one hand they feel a bit cold
|
|
||||||
(context: it is currently 1.57 degrees outside and I'm wearing a hoodie at my
|
|
||||||
desk so that may end up being the cause of this), but on the other hand i really
|
|
||||||
hate typing on this without them. The tenting is nice, I need to play with it
|
|
||||||
more but the included instructions help a lot.
|
|
||||||
|
|
||||||
I still have a long way to go. I'll write up a longer and more detailed review
|
|
||||||
in a few weeks.
|
|
||||||
|
|
||||||
Expect to see many more glory shots on
|
|
||||||
[Twitter](https://twitter.com/theprincessxena)!
|
|
||||||
|
|
||||||
As an added bonus, here is the `if err != nil` key in action:
|
|
||||||
|
|
||||||
<video controls width="100%">
|
|
||||||
<source src="https://cdn.christine.website/file/christine-static/img/keeb/tmp.ZdCemPUcnd.webm"
|
|
||||||
type="video/webm">
|
|
||||||
<source src="https://cdn.christine.website/file/christine-static/img/keeb/tmp.ZdCemPUcnd.mp4"
|
|
||||||
type="video/mp4">
|
|
||||||
Sorry, your browser doesn't support embedded videos.
|
|
||||||
</video>
|
|
||||||
|
|
@ -1,442 +0,0 @@
|
||||||
---
|
|
||||||
title: ZSA Moonlander Review
|
|
||||||
date: 2020-11-06
|
|
||||||
series: keeb
|
|
||||||
tags:
|
|
||||||
- moonlander
|
|
||||||
- keyboard
|
|
||||||
- nixos
|
|
||||||
---
|
|
||||||
|
|
||||||
# ZSA Moonlander Review
|
|
||||||
|
|
||||||
I am nowhere near qualified to review things objectively. Therefore this
|
|
||||||
blogpost will mostly be about what I like about this keyboard. I plan to go into
|
|
||||||
a fair bit of detail, however please do keep in mind that this is subjective as
|
|
||||||
all hell. Also keep in mind that this is partially also going to be a review of
|
|
||||||
my own keyboard layout too. I'm going to tackle this in a few parts that I will
|
|
||||||
label with headings.
|
|
||||||
|
|
||||||
This review is NOT sponsored. I paid for this device with my own money. I have
|
|
||||||
no influence pushing me either way on this keyboard.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
[That 3d printed brain is built from the 3D model that was made as a part of <a
|
|
||||||
href="https://christine.website/blog/brain-fmri-to-3d-model-2019-08-23">this
|
|
||||||
blogpost</a>.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
## tl;dr
|
|
||||||
|
|
||||||
I like the Moonlander. It gets out of my way and lets me focus on writing and
|
|
||||||
code. I don't like how limited the Oryx configurator is, but the fact that I can
|
|
||||||
build my own firmware from source and flash it to the keyboard on my own makes
|
|
||||||
up for that. I think this was a purchase well worth making, but I can understand
|
|
||||||
why others would disagree. I can easily see this device becoming a core part of
|
|
||||||
my workflow for years to come.
|
|
||||||
|
|
||||||
## Build Quality
|
|
||||||
|
|
||||||
The Moonlander is a solid keyboard. Once you set it up with the tenting legs and
|
|
||||||
adjust the key cluster, the keyboard is rock solid. The only give I've noticed
|
|
||||||
is because my desk mat is made of a rubber-like material. The construction of
|
|
||||||
the keyboard is all plastic but there isn't any deck flex that I can tell.
|
|
||||||
Compare this to cheaper laptops where the entire keyboard bends if you so much
|
|
||||||
as touch the keys too hard.
|
|
||||||
|
|
||||||
The palmrests are detachable and when they are off it gives the keyboard a
|
|
||||||
space-age vibe to it:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
The palmrests feel very solid and fold up into the back of the keyboard for
|
|
||||||
travel. However folding up the palmrest does mess up the tenting stability, so
|
|
||||||
you can't fold in the palmrest and type very comfortably. This makes sense
|
|
||||||
though, the palmrest is made out of smooth plastic so it feels nicer on the
|
|
||||||
hands.
|
|
||||||
|
|
||||||
ZSA said that iPad compatibility is not guaranteed due to the fact that the iPad
|
|
||||||
might not put out enough juice to run it, however in my testing with an iPad Pro
|
|
||||||
2018 (12", 512 GB storage) it works fine. The battery drains a little faster,
|
|
||||||
but the Moonlander is a much more active keyboard than the smart keyboard so I
|
|
||||||
can forgive this.
|
|
||||||
|
|
||||||
## Switches
|
|
||||||
|
|
||||||
I've been using mechanical keyboards for years, but most of them have been
|
|
||||||
clicky switches (such as cloned Cherry MX blues, actual legit Cherry MX blues
|
|
||||||
and the awful Razer Green switches). This is my first real experience with
|
|
||||||
Cherry MX brown switches. There are many other options when you are about to
|
|
||||||
order a moonlander, but I figured Cherry MX browns would be a nice neutral
|
|
||||||
choice.
|
|
||||||
|
|
||||||
The keyswitches are hot-swappable (no disassembly or soldering required), and
|
|
||||||
changing out keyswitches **DOES NOT** void your warranty. I plan to look into
|
|
||||||
[Holy Pandas](https://www.youtube.com/watch?v=QLm8DNH5hJk) and [Zilents
|
|
||||||
V2](https://youtu.be/uGVw85solnE) in the future. There is even a clever little
|
|
||||||
tool in the box that makes it easy to change out keyswitches.
|
|
||||||
|
|
||||||
Overall, this has been one of the best typing experiences I have ever had. The
|
|
||||||
noise is a little louder than I would have liked (please note that I tend to
|
|
||||||
bottom out the keycaps as I type, so this may end up factoring into the noise I
|
|
||||||
experience); but overall I really like it. It is far better than I have ever had
|
|
||||||
with clicky switches.
|
|
||||||
|
|
||||||
## Typing Feel
|
|
||||||
|
|
||||||
The Moonlander uses an ortholinear layout as opposed to the staggered layout
|
|
||||||
that you find on most keyboards. This took some getting used to, but I have
|
|
||||||
found that it is incredibly comfortable and natural to write on.
|
|
||||||
|
|
||||||
## My Keymap
|
|
||||||
|
|
||||||
Each side of the keyboard has the following:
|
|
||||||
|
|
||||||
- 20 alphanumeric keys (some are used for `;`, `,`, `.` and `/` like normal
|
|
||||||
keyboards)
|
|
||||||
- 12 freely assignable keys (useful for layer changes, arrow keys, symbols and
|
|
||||||
modifiers)
|
|
||||||
- 4 thumb keys
|
|
||||||
|
|
||||||
In total, this keyboard has 72 keys, making it about a 70% keyboard (assuming
|
|
||||||
the math in my head is right).
|
|
||||||
|
|
||||||
My keymap uses all but two of these keys. The two keys I haven't figured out how
|
|
||||||
to best use yet are the ones that I currently have the `[` and `]` keycaps on.
|
|
||||||
Right now they are mapped to the left and right arrow keys. This was the
|
|
||||||
default.
|
|
||||||
|
|
||||||
My keymap is organized into
|
|
||||||
[layers](https://docs.qmk.fm/#/keymap?id=keymap-and-layers). In each of these
|
|
||||||
subsections I will go into detail about what these layers are, what they do and
|
|
||||||
how they help me. My keymap code is
|
|
||||||
[here](https://tulpa.dev/cadey/kadis-layouts/src/branch/master/moonlander) and I
|
|
||||||
have a limited view of it embedded below:
|
|
||||||
|
|
||||||
<div style="padding-top: 60%; position: relative;">
|
|
||||||
<iframe src="https://configure.ergodox-ez.com/embed/moonlander/layouts/xbJXx/latest/0" style="border: 0; height: 100%; left: 0; position: absolute; top: 0; width: 100%"></iframe>
|
|
||||||
</div>
|
|
||||||
|
|
||||||
If you want to flash my layout to your Moonlander for some reason, you can find
|
|
||||||
the firmware binary
|
|
||||||
[here](https://cdn.christine.website/file/christine-static/img/keeb/moonlander_kadis.bin).
|
|
||||||
You can then flash this to your keyboard with
|
|
||||||
[Wally](https://ergodox-ez.com/pages/wally).
|
|
||||||
|
|
||||||
### Base Layers
|
|
||||||
|
|
||||||
I have a few base layers that contain the main set of letters and numbers that I
|
|
||||||
type. The main base layer is my Colemak layer. I have the keys arranged to a
|
|
||||||
standard [Colemak](https://Colemak.com/) layout and it is currently the layer I
|
|
||||||
type the fastest on. I have the RGB configured so that it is mostly pink with
|
|
||||||
the homerow using a lighter shade of pink. The color codes come from my logo
|
|
||||||
that you can see in the favicon [or here for a larger
|
|
||||||
version](https://christine.website/static/img/avatar_large.png).
|
|
||||||
|
|
||||||
I also have a qwerty layer for gaming. Most games expect qwerty keyboards and
|
|
||||||
this is an excellent stopgap to avoid having to rebind every game that I want to
|
|
||||||
play. The left side of the keyboard is the active one with the controller board
|
|
||||||
in it too, so I can unplug the other half of the keyboard and give my mouse a
|
|
||||||
lot of room to roam.
|
|
||||||
|
|
||||||
Thanks to a friend of mine, I am also playing with Dvorak. I have not gotten far
|
|
||||||
in Dvorak yet, but it is interesting to play with.
|
|
||||||
|
|
||||||
I'll cover the leader key in the section below dedicated to it, but the other
|
|
||||||
major thing that I have is a colon key on my right hand thumb cluster. This has
|
|
||||||
been a huge boon for programming. The colon key is typed a lot. Having it on the
|
|
||||||
thumb cluster means that I can just reach down and hit it when I need to. This
|
|
||||||
makes writing code in Go and Rust so much easier.
|
|
||||||
|
|
||||||
### Symbol/Number Layer
|
|
||||||
|
|
||||||
If you look at the base layer keymap, you will see that I do not have square
|
|
||||||
brackets mapped anywhere there. Yet I write code with it effortlessly. This is
|
|
||||||
because of the symbol/number layer that I access with the lower right and lower
|
|
||||||
left keys on the keyboard. I have it positioned there so I can roll my hand to
|
|
||||||
the side and then unlock the symbols there. I have access to every major symbol
|
|
||||||
needed for programming save `<` and `>` (which I can easily access on the base
|
|
||||||
layer with the shift key). I also get a nav cluster and a number pad.
|
|
||||||
|
|
||||||
I also have [dynamic macros](https://docs.qmk.fm/#/feature_dynamic_macros) on
|
|
||||||
this layer which function kinda like vim macros. The only difference is that
|
|
||||||
there's only two macros instead of many like vim. They are convenient though.
|
|
||||||
|
|
||||||
### Media Layer
|
|
||||||
|
|
||||||
One of the cooler parts of the Moonlander is that it can act as a mouse. It is a
|
|
||||||
very terrible mouse (understandably, mostly because the digital inputs of
|
|
||||||
keypresses cannot match the analog precision of a mouse). This layer has an
|
|
||||||
arrow key cluster too. I normally use the arrow keys along the bottom of the
|
|
||||||
keyboard with my thumbs, but sometimes it can help to have a dedicated inverse T
|
|
||||||
arrow cluster for things like old MS-DOS games.
|
|
||||||
|
|
||||||
I also have media control keys here. They aren't the most useful on my linux
|
|
||||||
desktop, however when I plug it into my iPad they are amazing.
|
|
||||||
|
|
||||||
### dwm Layer
|
|
||||||
|
|
||||||
I use [dwm](/blog/why-i-use-suckless-tools-2020-06-05) as my main window manager
|
|
||||||
in Linux. dwm is entirely controlled using the keyboard. I have a dedicated
|
|
||||||
keyboard layer to control dwm and send out its keyboard shortcuts. It's really
|
|
||||||
nice and lets me get all of the advantages of my tiling setup without needing to
|
|
||||||
hit weird keycombos.
|
|
||||||
|
|
||||||
### Leader Macros
|
|
||||||
|
|
||||||
[Leader macros](https://docs.qmk.fm/#/feature_leader_key) are one of the killer
|
|
||||||
features of my layout. I have a [huge
|
|
||||||
bank](https://tulpa.dev/cadey/kadis-layouts/src/branch/master/doc/leader.md) of
|
|
||||||
them and use them to do type out things that I type a lot. Most common git and
|
|
||||||
Kubernetes commands are just a leader macro away.
|
|
||||||
|
|
||||||
The Go `if err != nil` macro that got me on /r/programmingcirclejerk twice is
|
|
||||||
one of my leader macros, but I may end up promoting it to its own key if I keep
|
|
||||||
getting so much use out of it (maybe one of the keys I don't use can become my
|
|
||||||
`if err != nil` key). I'm sad that the threads got deleted (I love it when my
|
|
||||||
content gets on there, it's one of my favorite subreddits), but such is life.
|
|
||||||
|
|
||||||
## NixOS, the Moonlander and Colemak
|
|
||||||
|
|
||||||
When I got this keyboard, flashed the firmware and plugged it in, I noticed that
|
|
||||||
my keyboard was sending weird inputs. It was rendering things that look like
|
|
||||||
this:
|
|
||||||
|
|
||||||
```
|
|
||||||
The quick brown fox jumps over the lazy yellow dog.
|
|
||||||
```
|
|
||||||
|
|
||||||
into this:
|
|
||||||
|
|
||||||
```
|
|
||||||
Ghf qluce bpywk tyx nlm;r yvfp ghf iazj jfiiyw syd.
|
|
||||||
```
|
|
||||||
|
|
||||||
This is because I had configured my NixOS install to interpret the keyboard as
|
|
||||||
if it was Colemak. However the keyboard is able to lie and sends out normal
|
|
||||||
keycodes (even though I am typing them in Colemak) as if I was typing in qwerty.
|
|
||||||
This double Colemak meant that a lot of messages and commands were completely
|
|
||||||
unintelligible until I popped into my qwerty layer.
|
|
||||||
|
|
||||||
I quickly found the culprit in my config:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
console.useXkbConfig = true;
|
|
||||||
services.xserver = {
|
|
||||||
layout = "us";
|
|
||||||
xkbVariant = "colemak";
|
|
||||||
xkbOptions = "caps:escape";
|
|
||||||
};
|
|
||||||
```
|
|
||||||
|
|
||||||
This config told the X server to always interpret my keyboard as if it was
|
|
||||||
Colemak, meaning that I needed to tell it not to. As a stopgap I commented this
|
|
||||||
section of my config out and rebuilt my system.
|
|
||||||
|
|
||||||
X11 allows you to specify keyboard configuration for keyboards individually by
|
|
||||||
device product/vendor names. The easiest way I know to get this information is
|
|
||||||
to open a terminal, run `dmesg -w` to get a constant stream of kernel logs,
|
|
||||||
unplug and plug the keyboard back in and see what the kernel reports:
|
|
||||||
|
|
||||||
```console
|
|
||||||
[242718.024229] usb 1-2: USB disconnect, device number 8
|
|
||||||
[242948.272824] usb 1-2: new full-speed USB device number 9 using xhci_hcd
|
|
||||||
[242948.420895] usb 1-2: New USB device found, idVendor=3297, idProduct=1969, bcdDevice= 0.01
|
|
||||||
[242948.420896] usb 1-2: New USB device strings: Mfr=1, Product=2, SerialNumber=3
|
|
||||||
[242948.420897] usb 1-2: Product: Moonlander Mark I
|
|
||||||
[242948.420898] usb 1-2: Manufacturer: ZSA Technology Labs
|
|
||||||
[242948.420898] usb 1-2: SerialNumber: 0
|
|
||||||
```
|
|
||||||
|
|
||||||
The product is named `Moonlander Mark I`, which means we can match for it and
|
|
||||||
tell X11 to not colemakify the keycodes using something like this:
|
|
||||||
|
|
||||||
```
|
|
||||||
Section "InputClass"
|
|
||||||
Identifier "moonlander"
|
|
||||||
MatchIsKeyboard "on"
|
|
||||||
MatchProduct "Moonlander"
|
|
||||||
Option "XkbLayout" "us"
|
|
||||||
Option "XkbVariant" "basic"
|
|
||||||
EndSection
|
|
||||||
```
|
|
||||||
|
|
||||||
[For more information on what you can do in an `InputClass` section, see <a
|
|
||||||
href="https://www.x.org/releases/current/doc/man/man5/xorg.conf.5.xhtml#heading9">here</a>
|
|
||||||
in the X11 documentation.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
This configuration fragment can easily go in the normal X11 configuration
|
|
||||||
folder, but doing it like this would mean that I would have to manually drop
|
|
||||||
this file in on every system I want to colemakify. This does not scale and
|
|
||||||
defeats the point of doing this in NixOS.
|
|
||||||
|
|
||||||
Thankfully NixOS has [an
|
|
||||||
option](https://search.nixos.org/options?channel=20.09&show=services.xserver.inputClassSections&from=0&size=30&sort=relevance&query=inputClassSections)
|
|
||||||
to solve this very problem. Using this module we can write something like this:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
services.xserver = {
|
|
||||||
layout = "us";
|
|
||||||
xkbVariant = "colemak";
|
|
||||||
xkbOptions = "caps:escape";
|
|
||||||
|
|
||||||
inputClassSections = [
|
|
||||||
''
|
|
||||||
Identifier "yubikey"
|
|
||||||
MatchIsKeyboard "on"
|
|
||||||
MatchProduct "Yubikey"
|
|
||||||
Option "XkbLayout" "us"
|
|
||||||
Option "XkbVariant" "basic"
|
|
||||||
''
|
|
||||||
''
|
|
||||||
Identifier "moonlander"
|
|
||||||
MatchIsKeyboard "on"
|
|
||||||
MatchProduct "Moonlander"
|
|
||||||
Option "XkbLayout" "us"
|
|
||||||
Option "XkbVariant" "basic"
|
|
||||||
''
|
|
||||||
];
|
|
||||||
};
|
|
||||||
```
|
|
||||||
|
|
||||||
But this is NixOS and that allows us to go one step further and make the
|
|
||||||
identifier and product matching string configurable as will with our own [NixOS
|
|
||||||
options](https://nixos.org/manual/nixos/stable/index.html#sec-writing-modules).
|
|
||||||
Let's start by lifting all of that above config into its own module:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
# Colemak.nix
|
|
||||||
|
|
||||||
{ config, lib, ... }: with lib; {
|
|
||||||
options = {
|
|
||||||
cadey.colemak = {
|
|
||||||
enable = mkEnableOption "Enables colemak for the default X config";
|
|
||||||
};
|
|
||||||
};
|
|
||||||
|
|
||||||
config = mkIf config.cadey.Colemak.enable {
|
|
||||||
services.xserver = {
|
|
||||||
layout = "us";
|
|
||||||
xkbVariant = "colemak";
|
|
||||||
xkbOptions = "caps:escape";
|
|
||||||
|
|
||||||
inputClassSections = [
|
|
||||||
''
|
|
||||||
Identifier "yubikey"
|
|
||||||
MatchIsKeyboard "on"
|
|
||||||
MatchProduct "Yubikey"
|
|
||||||
Option "XkbLayout" "us"
|
|
||||||
Option "XkbVariant" "basic"
|
|
||||||
|
|
||||||
''
|
|
||||||
''
|
|
||||||
Identifier "moonlander"
|
|
||||||
MatchIsKeyboard "on"
|
|
||||||
MatchProduct "Moonlander"
|
|
||||||
Option "XkbLayout" "us"
|
|
||||||
Option "XkbVariant" "basic"
|
|
||||||
''
|
|
||||||
];
|
|
||||||
};
|
|
||||||
};
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
[This also has Yubikey inputs not get processed into Colemak so that <a
|
|
||||||
href="https://developers.yubico.com/OTP/OTPs_Explained.html">Yubikey OTPs</a>
|
|
||||||
still work as expected. Keep in mind that a Yubikey in this mode pretends to be
|
|
||||||
a keyboard, so without this configuration the OTP will be processed into
|
|
||||||
Colemak. The Yubico verification service will not be able to understand OTPs
|
|
||||||
that are typed out in Colemak.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
Then we can turn the identifier and product values into options with
|
|
||||||
[mkOption](https://nixos.org/manual/nixos/stable/index.html#sec-option-declarations)
|
|
||||||
and string interpolation:
|
|
||||||
|
|
||||||
```nix
|
|
||||||
# ...
|
|
||||||
cadey.colemak = {
|
|
||||||
enable = mkEnableOption "Enables Colemak for the default X config";
|
|
||||||
ignore = {
|
|
||||||
identifier = mkOption {
|
|
||||||
type = types.str;
|
|
||||||
description = "Keyboard input identifier to send raw keycodes for";
|
|
||||||
default = "moonlander";
|
|
||||||
};
|
|
||||||
product = mkOption {
|
|
||||||
type = types.str;
|
|
||||||
description = "Keyboard input product to send raw keycodes for";
|
|
||||||
default = "Moonlander";
|
|
||||||
};
|
|
||||||
};
|
|
||||||
};
|
|
||||||
# ...
|
|
||||||
''
|
|
||||||
Identifier "${config.cadey.colemak.ignore.identifier}"
|
|
||||||
MatchIsKeyboard "on"
|
|
||||||
MatchProduct "${config.cadey.colemak.ignore.product}"
|
|
||||||
Option "XkbLayout" "us"
|
|
||||||
''
|
|
||||||
# ...
|
|
||||||
```
|
|
||||||
|
|
||||||
Adding this to the default load path and enabling it with `cadey.colemak.enable
|
|
||||||
= true;` in my tower's `configuration.nix`
|
|
||||||
|
|
||||||
This section was made possible thanks to help from [Graham
|
|
||||||
Christensen](https://twitter.com/grhmc) who seems to be in search of a job. If
|
|
||||||
you are wanting someone on your team that is kind and more than willing to help
|
|
||||||
make your team flourish, I highly suggest looking into putting him in your
|
|
||||||
hiring pipeline. See
|
|
||||||
[here](https://twitter.com/grhmc/status/1324765493534875650) for contact
|
|
||||||
information.
|
|
||||||
|
|
||||||
## Oryx
|
|
||||||
|
|
||||||
[Oryx](https://configure.ergodox-ez.com) is the configurator that ZSA created to
|
|
||||||
allow people to create keymaps without needing to compile your own firmware or
|
|
||||||
install the [QMK](https://qmk.fm) toolchain.
|
|
||||||
|
|
||||||
[QMK is the name of the firmware that the Moonlander (and a lot of other
|
|
||||||
custom/split mechanical keyboards) use. It works on AVR and Arm
|
|
||||||
processors.](conversation://Mara/hacker)
|
|
||||||
|
|
||||||
For most people, Oryx should be sufficient. I actually started my keymap using
|
|
||||||
Oryx and sorta outgrew it as I learned more about QMK. It would be nice if Oryx
|
|
||||||
added leader key support, however this is more of an advanced feature so I
|
|
||||||
understand why it doesn't have that.
|
|
||||||
|
|
||||||
## Things I Don't Like
|
|
||||||
|
|
||||||
This keyboard isn't flawless, but it gets so many things right that this is
|
|
||||||
mostly petty bickering at this point. I had to look hard to find these.
|
|
||||||
|
|
||||||
I would have liked having another thumb key for things like layer toggling. I
|
|
||||||
can make do with what I have, but another key would have been nice. Maybe add a
|
|
||||||
1u key under the red shaped key?
|
|
||||||
|
|
||||||
At the point I ordered the Moonlander, I was unable to order a black keyboard
|
|
||||||
with white keycaps. I am told that ZSA will be selling keycap sets as early as
|
|
||||||
next year. When that happens I will be sure to order a white one so that I can
|
|
||||||
have an orca vibe.
|
|
||||||
|
|
||||||
ZSA ships with UPS. Normally UPS is fine for me, but the driver that was slated
|
|
||||||
to deliver it one day just didn't deliver it. I was able to get the keyboard
|
|
||||||
eventually though. Contrary to their claims, the UPS website does NOT update
|
|
||||||
instantly and is NOT the most up to date source of information about your
|
|
||||||
package.
|
|
||||||
|
|
||||||
The cables aren't braided. I would have liked braided cables.
|
|
||||||
|
|
||||||
Like I said, these are _really minor_ things, but it's all I can really come up
|
|
||||||
with as far as downsides go.
|
|
||||||
|
|
||||||
## Conclusion
|
|
||||||
|
|
||||||
Overall this keyboard is amazing. I would really suggest it to anyone that wants
|
|
||||||
to be able to have control over their main tool and craft it towards their
|
|
||||||
desires instead of making do with what some product manager somewhere decided
|
|
||||||
what keys should do what. It's expensive at USD$350, but for the right kind of
|
|
||||||
person this will be worth every penny. Your mileage may vary, but I like it.
|
|
||||||
|
|
@ -0,0 +1 @@
|
||||||
|
package main
|
||||||
|
|
@ -0,0 +1,245 @@
|
||||||
|
package main
|
||||||
|
|
||||||
|
import (
|
||||||
|
"context"
|
||||||
|
"fmt"
|
||||||
|
"html/template"
|
||||||
|
"net/http"
|
||||||
|
"path/filepath"
|
||||||
|
"strings"
|
||||||
|
"time"
|
||||||
|
|
||||||
|
"christine.website/cmd/site/internal"
|
||||||
|
"christine.website/cmd/site/internal/blog"
|
||||||
|
"github.com/prometheus/client_golang/prometheus"
|
||||||
|
"github.com/prometheus/client_golang/prometheus/promauto"
|
||||||
|
"within.website/ln"
|
||||||
|
"within.website/ln/opname"
|
||||||
|
)
|
||||||
|
|
||||||
|
var (
|
||||||
|
templateRenderTime = promauto.NewHistogramVec(prometheus.HistogramOpts{
|
||||||
|
Name: "template_render_time",
|
||||||
|
Help: "Template render time in nanoseconds",
|
||||||
|
}, []string{"name"})
|
||||||
|
)
|
||||||
|
|
||||||
|
func logTemplateTime(ctx context.Context, name string, f ln.F, from time.Time) {
|
||||||
|
dur := time.Since(from)
|
||||||
|
templateRenderTime.With(prometheus.Labels{"name": name}).Observe(float64(dur))
|
||||||
|
ln.Log(ctx, f, ln.F{"dur": dur, "name": name})
|
||||||
|
}
|
||||||
|
|
||||||
|
func (s *Site) renderTemplatePage(templateFname string, data interface{}) http.Handler {
|
||||||
|
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
|
||||||
|
ctx := opname.With(r.Context(), "renderTemplatePage")
|
||||||
|
fetag := "W/" + internal.Hash(templateFname, etag) + "-1"
|
||||||
|
|
||||||
|
f := ln.F{"etag": fetag, "if_none_match": r.Header.Get("If-None-Match")}
|
||||||
|
|
||||||
|
if r.Header.Get("If-None-Match") == fetag {
|
||||||
|
http.Error(w, "Cached data OK", http.StatusNotModified)
|
||||||
|
ln.Log(ctx, f, ln.Info("Cache hit"))
|
||||||
|
return
|
||||||
|
}
|
||||||
|
|
||||||
|
defer logTemplateTime(ctx, templateFname, f, time.Now())
|
||||||
|
|
||||||
|
var t *template.Template
|
||||||
|
var err error
|
||||||
|
|
||||||
|
t, err = template.ParseFiles("templates/base.html", "templates/"+templateFname)
|
||||||
|
if err != nil {
|
||||||
|
w.WriteHeader(http.StatusInternalServerError)
|
||||||
|
ln.Error(ctx, err, ln.F{"action": "renderTemplatePage", "page": templateFname})
|
||||||
|
fmt.Fprintf(w, "error: %v", err)
|
||||||
|
}
|
||||||
|
|
||||||
|
w.Header().Set("ETag", fetag)
|
||||||
|
w.Header().Set("Cache-Control", "max-age=432000")
|
||||||
|
|
||||||
|
err = t.Execute(w, data)
|
||||||
|
if err != nil {
|
||||||
|
panic(err)
|
||||||
|
}
|
||||||
|
})
|
||||||
|
}
|
||||||
|
|
||||||
|
var postView = promauto.NewCounterVec(prometheus.CounterOpts{
|
||||||
|
Name: "posts_viewed",
|
||||||
|
Help: "The number of views per post or talk",
|
||||||
|
}, []string{"base"})
|
||||||
|
|
||||||
|
func (s *Site) listSeries(w http.ResponseWriter, r *http.Request) {
|
||||||
|
s.renderTemplatePage("series.html", s.Series).ServeHTTP(w, r)
|
||||||
|
}
|
||||||
|
|
||||||
|
func (s *Site) showSeries(w http.ResponseWriter, r *http.Request) {
|
||||||
|
if r.RequestURI == "/blog/series/" {
|
||||||
|
http.Redirect(w, r, "/blog/series", http.StatusSeeOther)
|
||||||
|
return
|
||||||
|
}
|
||||||
|
|
||||||
|
series := filepath.Base(r.URL.Path)
|
||||||
|
var posts []blog.Post
|
||||||
|
|
||||||
|
for _, p := range s.Posts {
|
||||||
|
if p.Series == series {
|
||||||
|
posts = append(posts, p)
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
s.renderTemplatePage("serieslist.html", struct {
|
||||||
|
Name string
|
||||||
|
Posts []blog.Post
|
||||||
|
}{
|
||||||
|
Name: series,
|
||||||
|
Posts: posts,
|
||||||
|
}).ServeHTTP(w, r)
|
||||||
|
}
|
||||||
|
|
||||||
|
func (s *Site) showGallery(w http.ResponseWriter, r *http.Request) {
|
||||||
|
if r.RequestURI == "/gallery/" {
|
||||||
|
http.Redirect(w, r, "/gallery", http.StatusSeeOther)
|
||||||
|
return
|
||||||
|
}
|
||||||
|
|
||||||
|
cmp := r.URL.Path[1:]
|
||||||
|
var p blog.Post
|
||||||
|
var found bool
|
||||||
|
for _, pst := range s.Gallery {
|
||||||
|
if pst.Link == cmp {
|
||||||
|
p = pst
|
||||||
|
found = true
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
if !found {
|
||||||
|
w.WriteHeader(http.StatusNotFound)
|
||||||
|
s.renderTemplatePage("error.html", "no such post found: "+r.RequestURI).ServeHTTP(w, r)
|
||||||
|
return
|
||||||
|
}
|
||||||
|
|
||||||
|
var tags string
|
||||||
|
if len(p.Tags) != 0 {
|
||||||
|
for _, t := range p.Tags {
|
||||||
|
tags = tags + " #" + strings.ReplaceAll(t, "-", "")
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
h := s.renderTemplatePage("gallerypost.html", struct {
|
||||||
|
Title string
|
||||||
|
Link string
|
||||||
|
BodyHTML template.HTML
|
||||||
|
Date string
|
||||||
|
Tags string
|
||||||
|
Image string
|
||||||
|
}{
|
||||||
|
Title: p.Title,
|
||||||
|
Link: p.Link,
|
||||||
|
BodyHTML: p.BodyHTML,
|
||||||
|
Date: internal.IOS13Detri(p.Date),
|
||||||
|
Tags: tags,
|
||||||
|
Image: p.ImageURL,
|
||||||
|
})
|
||||||
|
|
||||||
|
if h == nil {
|
||||||
|
panic("how did we get here?")
|
||||||
|
}
|
||||||
|
|
||||||
|
h.ServeHTTP(w, r)
|
||||||
|
postView.With(prometheus.Labels{"base": filepath.Base(p.Link)}).Inc()
|
||||||
|
}
|
||||||
|
|
||||||
|
func (s *Site) showTalk(w http.ResponseWriter, r *http.Request) {
|
||||||
|
if r.RequestURI == "/talks/" {
|
||||||
|
http.Redirect(w, r, "/talks", http.StatusSeeOther)
|
||||||
|
return
|
||||||
|
}
|
||||||
|
|
||||||
|
cmp := r.URL.Path[1:]
|
||||||
|
var p blog.Post
|
||||||
|
var found bool
|
||||||
|
for _, pst := range s.Talks {
|
||||||
|
if pst.Link == cmp {
|
||||||
|
p = pst
|
||||||
|
found = true
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
if !found {
|
||||||
|
w.WriteHeader(http.StatusNotFound)
|
||||||
|
s.renderTemplatePage("error.html", "no such post found: "+r.RequestURI).ServeHTTP(w, r)
|
||||||
|
return
|
||||||
|
}
|
||||||
|
|
||||||
|
h := s.renderTemplatePage("talkpost.html", struct {
|
||||||
|
Title string
|
||||||
|
Link string
|
||||||
|
BodyHTML template.HTML
|
||||||
|
Date string
|
||||||
|
SlidesLink string
|
||||||
|
}{
|
||||||
|
Title: p.Title,
|
||||||
|
Link: p.Link,
|
||||||
|
BodyHTML: p.BodyHTML,
|
||||||
|
Date: internal.IOS13Detri(p.Date),
|
||||||
|
SlidesLink: p.SlidesLink,
|
||||||
|
})
|
||||||
|
|
||||||
|
if h == nil {
|
||||||
|
panic("how did we get here?")
|
||||||
|
}
|
||||||
|
|
||||||
|
h.ServeHTTP(w, r)
|
||||||
|
postView.With(prometheus.Labels{"base": filepath.Base(p.Link)}).Inc()
|
||||||
|
}
|
||||||
|
|
||||||
|
func (s *Site) showPost(w http.ResponseWriter, r *http.Request) {
|
||||||
|
if r.RequestURI == "/blog/" {
|
||||||
|
http.Redirect(w, r, "/blog", http.StatusSeeOther)
|
||||||
|
return
|
||||||
|
}
|
||||||
|
|
||||||
|
cmp := r.URL.Path[1:]
|
||||||
|
var p blog.Post
|
||||||
|
var found bool
|
||||||
|
for _, pst := range s.Posts {
|
||||||
|
if pst.Link == cmp {
|
||||||
|
p = pst
|
||||||
|
found = true
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
if !found {
|
||||||
|
w.WriteHeader(http.StatusNotFound)
|
||||||
|
s.renderTemplatePage("error.html", "no such post found: "+r.RequestURI).ServeHTTP(w, r)
|
||||||
|
return
|
||||||
|
}
|
||||||
|
|
||||||
|
var tags string
|
||||||
|
|
||||||
|
if len(p.Tags) != 0 {
|
||||||
|
for _, t := range p.Tags {
|
||||||
|
tags = tags + " #" + strings.ReplaceAll(t, "-", "")
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
s.renderTemplatePage("blogpost.html", struct {
|
||||||
|
Title string
|
||||||
|
Link string
|
||||||
|
BodyHTML template.HTML
|
||||||
|
Date string
|
||||||
|
Series, SeriesTag string
|
||||||
|
Tags string
|
||||||
|
}{
|
||||||
|
Title: p.Title,
|
||||||
|
Link: p.Link,
|
||||||
|
BodyHTML: p.BodyHTML,
|
||||||
|
Date: internal.IOS13Detri(p.Date),
|
||||||
|
Series: p.Series,
|
||||||
|
SeriesTag: strings.ReplaceAll(p.Series, "-", ""),
|
||||||
|
Tags: tags,
|
||||||
|
}).ServeHTTP(w, r)
|
||||||
|
postView.With(prometheus.Labels{"base": filepath.Base(p.Link)}).Inc()
|
||||||
|
}
|
||||||
|
|
@ -0,0 +1,136 @@
|
||||||
|
package blog
|
||||||
|
|
||||||
|
import (
|
||||||
|
"html/template"
|
||||||
|
"io/ioutil"
|
||||||
|
"os"
|
||||||
|
"path/filepath"
|
||||||
|
"sort"
|
||||||
|
"strings"
|
||||||
|
"time"
|
||||||
|
|
||||||
|
"christine.website/cmd/site/internal/front"
|
||||||
|
"github.com/russross/blackfriday"
|
||||||
|
)
|
||||||
|
|
||||||
|
// Post is a single blogpost.
|
||||||
|
type Post struct {
|
||||||
|
Title string `json:"title"`
|
||||||
|
Link string `json:"link"`
|
||||||
|
Summary string `json:"summary,omitifempty"`
|
||||||
|
Body string `json:"-"`
|
||||||
|
BodyHTML template.HTML `json:"body"`
|
||||||
|
Series string `json:"series"`
|
||||||
|
Tags []string `json:"tags"`
|
||||||
|
SlidesLink string `json:"slides_link"`
|
||||||
|
ImageURL string `json:"image_url"`
|
||||||
|
ThumbURL string `json:"thumb_url"`
|
||||||
|
Date time.Time
|
||||||
|
DateString string `json:"date"`
|
||||||
|
}
|
||||||
|
|
||||||
|
// Posts implements sort.Interface for a slice of Post objects.
|
||||||
|
type Posts []Post
|
||||||
|
|
||||||
|
func (p Posts) Series() []string {
|
||||||
|
names := map[string]struct{}{}
|
||||||
|
|
||||||
|
for _, ps := range p {
|
||||||
|
if ps.Series != "" {
|
||||||
|
names[ps.Series] = struct{}{}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
var result []string
|
||||||
|
|
||||||
|
for name := range names {
|
||||||
|
result = append(result, name)
|
||||||
|
}
|
||||||
|
|
||||||
|
return result
|
||||||
|
}
|
||||||
|
|
||||||
|
func (p Posts) Len() int { return len(p) }
|
||||||
|
func (p Posts) Less(i, j int) bool {
|
||||||
|
iDate := p[i].Date
|
||||||
|
jDate := p[j].Date
|
||||||
|
|
||||||
|
return iDate.Unix() < jDate.Unix()
|
||||||
|
}
|
||||||
|
func (p Posts) Swap(i, j int) { p[i], p[j] = p[j], p[i] }
|
||||||
|
|
||||||
|
// LoadPosts loads posts for a given directory.
|
||||||
|
func LoadPosts(path string, prepend string) (Posts, error) {
|
||||||
|
type postFM struct {
|
||||||
|
Title string
|
||||||
|
Date string
|
||||||
|
Series string
|
||||||
|
Tags []string
|
||||||
|
SlidesLink string `yaml:"slides_link"`
|
||||||
|
Image string
|
||||||
|
Thumb string
|
||||||
|
}
|
||||||
|
var result Posts
|
||||||
|
|
||||||
|
err := filepath.Walk(path, func(path string, info os.FileInfo, err error) error {
|
||||||
|
if err != nil {
|
||||||
|
return err
|
||||||
|
}
|
||||||
|
|
||||||
|
if info.IsDir() {
|
||||||
|
return nil
|
||||||
|
}
|
||||||
|
|
||||||
|
fin, err := os.Open(path)
|
||||||
|
if err != nil {
|
||||||
|
return err
|
||||||
|
}
|
||||||
|
defer fin.Close()
|
||||||
|
|
||||||
|
content, err := ioutil.ReadAll(fin)
|
||||||
|
if err != nil {
|
||||||
|
return err
|
||||||
|
}
|
||||||
|
|
||||||
|
var fm postFM
|
||||||
|
remaining, err := front.Unmarshal(content, &fm)
|
||||||
|
if err != nil {
|
||||||
|
return err
|
||||||
|
}
|
||||||
|
|
||||||
|
output := blackfriday.Run(remaining)
|
||||||
|
|
||||||
|
const timeFormat = `2006-01-02`
|
||||||
|
date, err := time.Parse(timeFormat, fm.Date)
|
||||||
|
if err != nil {
|
||||||
|
return err
|
||||||
|
}
|
||||||
|
|
||||||
|
fname := filepath.Base(path)
|
||||||
|
fname = strings.TrimSuffix(fname, filepath.Ext(fname))
|
||||||
|
|
||||||
|
p := Post{
|
||||||
|
Title: fm.Title,
|
||||||
|
Date: date,
|
||||||
|
DateString: fm.Date,
|
||||||
|
Link: filepath.Join(prepend, fname),
|
||||||
|
Body: string(remaining),
|
||||||
|
BodyHTML: template.HTML(output),
|
||||||
|
SlidesLink: fm.SlidesLink,
|
||||||
|
Series: fm.Series,
|
||||||
|
Tags: fm.Tags,
|
||||||
|
ImageURL: fm.Image,
|
||||||
|
ThumbURL: fm.Thumb,
|
||||||
|
}
|
||||||
|
result = append(result, p)
|
||||||
|
|
||||||
|
return nil
|
||||||
|
})
|
||||||
|
if err != nil {
|
||||||
|
return nil, err
|
||||||
|
}
|
||||||
|
|
||||||
|
sort.Sort(sort.Reverse(result))
|
||||||
|
|
||||||
|
return result, nil
|
||||||
|
}
|
||||||
|
|
@ -0,0 +1,66 @@
|
||||||
|
package blog
|
||||||
|
|
||||||
|
import (
|
||||||
|
"testing"
|
||||||
|
)
|
||||||
|
|
||||||
|
func TestLoadPosts(t *testing.T) {
|
||||||
|
posts, err := LoadPosts("../../../../blog", "blog")
|
||||||
|
if err != nil {
|
||||||
|
t.Fatal(err)
|
||||||
|
}
|
||||||
|
|
||||||
|
for _, post := range posts {
|
||||||
|
t.Run(post.Link, post.test)
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
func TestLoadTalks(t *testing.T) {
|
||||||
|
talks, err := LoadPosts("../../../../talks", "talks")
|
||||||
|
if err != nil {
|
||||||
|
t.Fatal(err)
|
||||||
|
}
|
||||||
|
|
||||||
|
for _, talk := range talks {
|
||||||
|
t.Run(talk.Link, talk.test)
|
||||||
|
if talk.SlidesLink == "" {
|
||||||
|
t.Errorf("talk %s (%s) doesn't have a slides link", talk.Title, talk.DateString)
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
func TestLoadGallery(t *testing.T) {
|
||||||
|
gallery, err := LoadPosts("../../../../gallery", "gallery")
|
||||||
|
if err != nil {
|
||||||
|
t.Fatal(err)
|
||||||
|
}
|
||||||
|
|
||||||
|
for _, art := range gallery {
|
||||||
|
t.Run(art.Link, art.test)
|
||||||
|
if art.ImageURL == "" {
|
||||||
|
t.Errorf("art %s (%s) doesn't have an image link", art.Title, art.DateString)
|
||||||
|
}
|
||||||
|
if art.ThumbURL == "" {
|
||||||
|
t.Errorf("art %s (%s) doesn't have a thumbnail link", art.Title, art.DateString)
|
||||||
|
}
|
||||||
|
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
func (p Post) test(t *testing.T) {
|
||||||
|
if p.Title == "" {
|
||||||
|
t.Error("no post title")
|
||||||
|
}
|
||||||
|
|
||||||
|
if p.DateString == "" {
|
||||||
|
t.Error("no date")
|
||||||
|
}
|
||||||
|
|
||||||
|
if p.Link == "" {
|
||||||
|
t.Error("no link")
|
||||||
|
}
|
||||||
|
|
||||||
|
if p.Body == "" {
|
||||||
|
t.Error("no body")
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
@ -0,0 +1,10 @@
|
||||||
|
package internal
|
||||||
|
|
||||||
|
import "time"
|
||||||
|
|
||||||
|
const iOS13DetriFormat = `2006 M1 2`
|
||||||
|
|
||||||
|
// IOS13Detri formats a datestamp like iOS 13 does with the Lojban locale.
|
||||||
|
func IOS13Detri(t time.Time) string {
|
||||||
|
return t.Format(iOS13DetriFormat)
|
||||||
|
}
|
||||||
|
|
@ -0,0 +1,28 @@
|
||||||
|
package internal
|
||||||
|
|
||||||
|
import (
|
||||||
|
"fmt"
|
||||||
|
"testing"
|
||||||
|
"time"
|
||||||
|
)
|
||||||
|
|
||||||
|
func TestIOS13Detri(t *testing.T) {
|
||||||
|
cases := []struct {
|
||||||
|
in time.Time
|
||||||
|
out string
|
||||||
|
}{
|
||||||
|
{
|
||||||
|
in: time.Date(2019, time.March, 30, 0, 0, 0, 0, time.FixedZone("UTC", 0)),
|
||||||
|
out: "2019 M3 30",
|
||||||
|
},
|
||||||
|
}
|
||||||
|
|
||||||
|
for _, cs := range cases {
|
||||||
|
t.Run(fmt.Sprintf("%s -> %s", cs.in.Format(time.RFC3339), cs.out), func(t *testing.T) {
|
||||||
|
result := IOS13Detri(cs.in)
|
||||||
|
if result != cs.out {
|
||||||
|
t.Fatalf("wanted: %s, got: %s", cs.out, result)
|
||||||
|
}
|
||||||
|
})
|
||||||
|
}
|
||||||
|
}
|
||||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue