|
|
||
|---|---|---|
| .. | ||
| README.md | ||
| constload.png | ||
| spike.png | ||
{kind=link}
{kind=link}
README.md
Benchmark report
The benchmark compares tunnel to koding tunnel on serving 184 midsized files that were gathered by saving amazon.com for offline view. The data set consists of images and text data (js, css, html). On start client loads the files into memory and act as a file server.
The diagrams were rendered using hdrhistogram and the input files were generated with help of github.com/codahale/hdrhistogram library. The vegeta raw results were corrected for stalls using hdr correction method.
Environment
Tests were done on four AWS t2.micro instances. An instance for client, an instance for server and two instances for load generator. For load generation we used vegeta in distributed mode. On all machines open files limit (ulimit -n) was increased to 20000.
Load spike
This test compares performance on two minute load spikes. tunnel handles 900 req/sec without dropping a message while preserving good latency. At 1000 req/sec tunnel still works but drops 0,20% requests and latency is much worse. Koding tunnel is faster at 800 req/sec, but at higher request rates latency degrades giving maximum values of 1.65s at 900 req/sec and 23.50s at 1000 req/sec (with 5% error rate).
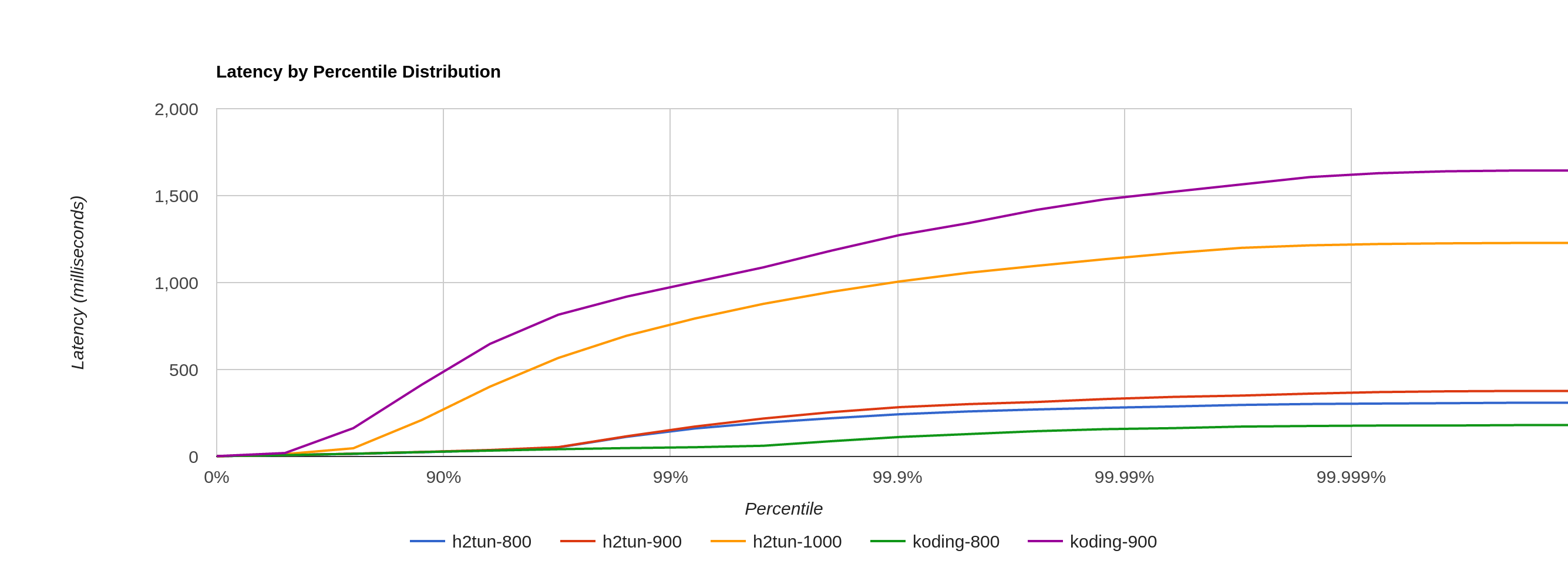
Detailed results of load spike test.
| Impl. | Req/sec | Success rate | P99 (corrected) | Max |
|---|---|---|---|---|
| tunnel | 600 | 100% | 40.079103ms | 147.310766ms |
| tunnel | 800 | 100% | 161.093631ms | 308.993573ms |
| tunnel | 900 | 100% | 172.114943ms | 376.924512ms |
| tunnel | 1000 | 99.90% | 793.423871ms | 1228.133135ms |
| koding | 600 | 100% | 43.161855ms | 173.871604ms |
| koding | 800 | 100% | 53.311743ms | 180.344454ms |
| koding | 900 | 100% | 1003.495423ms | 1648.814589ms |
| koding | 1000 | 94.95% | 16081.551359ms | 23494.866864ms |
Constant pressure
This test compares performance on twenty minutes constant pressure runs. tunnel shows ability to trade latency for throughput. It runs fine at 300 req/sec but at higher request rates we observe poor latency and some message drops. Koding tunnel has acceptable performance at 300 req/sec, however, with increased load it just breaks.
Both implementations have a connection (or memory) leak when dealing with too high loads. This results in process (or machine) crash as machine runs out of memory. It's 100% reproducible, when process crashes it has few hundred thousands go routines waiting on select in a connection and memory full of connection buffers.
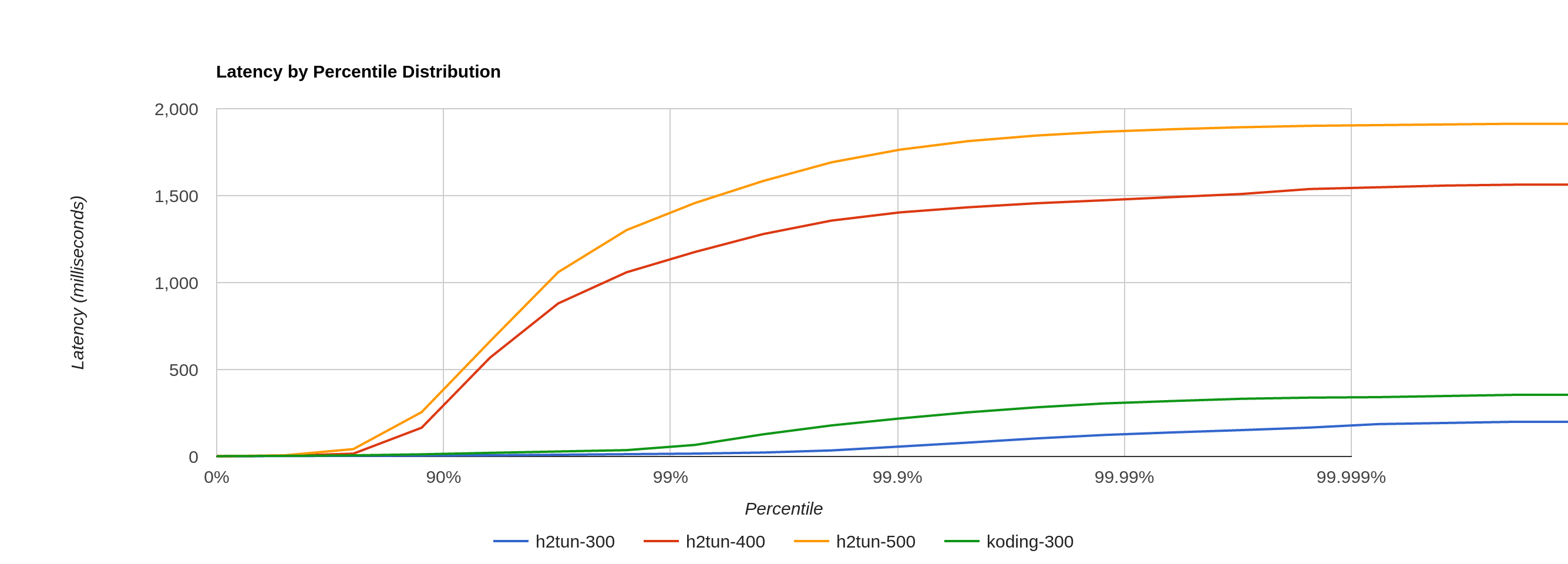
Detailed results of constant pressure test.
| Impl. | Req/sec | Success rate | P99 (corrected) | Max |
|---|---|---|---|---|
| tunnel | 300 | 100% | 16.614527ms | 199.479958ms |
| tunnel | 400 | 99.98% | 1175.904255 | 1568.012326ms |
| tunnel | 500 | 99.96% | 1457.364991ms | 1917.406792ms |
| koding | 300 | 100% | 66.436607ms | 354.531247ms |
| koding | 400 | 82.66% | - | - |
| koding | 500 | 63.16% | - | - |